

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Hlavní partner sekce

Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

Big Data a Business Intelligence , AI a Business Intelligence


Analýza nestrukturovaných dat je klíčovou kompetencí
Kateřina Veselovská
 Žijeme ve věku velkých dat, jejichž objem stále narůstá. Podstatnou část těchto dat tvoří data nestrukturovaná, která již není možné třídit ani prohledávat manuálně. Roste tedy přirozeně potřeba automatické analýzy využívající nejmodernějších přístupů z oblasti strojového učení, počítačového zpracování přirozeného jazyka či kognitivního programování. Získat detailní informace o klientech a struktuře firemních dat nebylo nikdy tak snadné – a zároveň tak složité.
Žijeme ve věku velkých dat, jejichž objem stále narůstá. Podstatnou část těchto dat tvoří data nestrukturovaná, která již není možné třídit ani prohledávat manuálně. Roste tedy přirozeně potřeba automatické analýzy využívající nejmodernějších přístupů z oblasti strojového učení, počítačového zpracování přirozeného jazyka či kognitivního programování. Získat detailní informace o klientech a struktuře firemních dat nebylo nikdy tak snadné – a zároveň tak složité.
Nestrukturovaná data jako cenný zdroj informací
Interní i externí údaje o klientech – zákaznické emaily, poznámky k transakcím, přepisy telefonních hovorů, data ze sociálních sítí, novinové články, ale také obrázky, fotky nebo audio či video záznamy. To všechno jsou nestrukturovaná data, v nichž je dnes ukryta podstatná část informací, které mohou mít pro firmy zásadní hodnotu. Lze z nich např. vyčíst zájmy či záměry klientů, jejich vztahy mezi sebou i k dalším entitám, nebo získat detailní zpětnou vazbu. Nadto mají firmy k dispozici množství interních dokumentů, ať už jde o životopisy zaměstnanců či nejrůznější smlouvy nebo nabídky. Schopnost tato data zpracovávat se stává pro konkurenceschopnost firem klíčovou kompetencí.
Zatímco analýza dat strukturovaných či tzv. „tvrdých“ je pro většinu firem a společností již delší dobu standardním přístupem, doba pokročilé analýzy nestrukturovaných dat teprve nadchází. Zejména zpracování textových dat je pak komplexní a technologicky obtížná úloha. Typicky jsou tato data náročná na objem, navíc je potřeba je převést do podoby, kterou je možné dále zpracovávat a využívat v analýzách. Díky aktuálnímu technologickému rozvoji zejména v oblasti strojového učení, potažmo hlubokých neuronových sítí, je ale možné takové zpracování provádět v relativně krátkém čase.
Nejnovější přístupy k textové analytice
V byznysovém pojmosloví se se zpracováváním textových dat častěji setkáváme pod pojmem textová analytika. Jejím cílem je porozumění psanému textu počítačem, či přesněji pochopení a extrakce informací důležitých pro následné business rozhodování. Při tomto typu analýzy se tradičně využívají nástroje a algoritmy z oblasti zpracovávání přirozeného jazyka (známého také jako NLP, natural language processing, někdy nazývaného komputační lingvistika).
Zpracování textu lze rozdělit na dvě základní oblasti: přípravu a samotné vytěžování dat. V rámci přípravy textových dat probíhá řada dílčích úloh. Mezi ty nejzákladnější patří oprava překlepů a gramatických chyb, buďto pomocí slovníku nebo s využitím tzv. fuzzy matching algoritmů používajících editační vzdálenosti. Někdy je nutno zapojit také pokročilejší metody sémantické analýzy (aby bylo možno rozpoznat správný kontext daného výrazu a zjistit, zda bylo záměrem použít např. tvar čest nebo cest). Dále je pro potřeby zevrubnější analýzy výhodné segmentovat text na dílčí části: odstavce, věty či slova. Zdánlivě jednoduchá úloha má svá úskalí zejména v jazycích, ve kterých jsou velkou měrou zastoupena tzv. kompozita, a je v nich tedy těžší hranici slov určit – viz např. německé Donaudampfschiffahrtsgesellschaftskapitän.
Za účelem následného trénování pravděpodobnostních modelů je výhodné snížit počet jednotlivých slovních tvarů v textu na minimum. K tomu může sloužit poněkud mechanické převedení slov na slovní základy, čili tzv. stemming, při kterém se odstraňují koncovky jednotlivých tvarů. Pokročilejší možností je lemmatizace neboli převedení slova do slovníkového tvaru s využitím gramatiky daného jazyka. Zejména u morfologicky bohatších jazyků (jako je např. čeština), je dále důležité určení slovních druhů a příslušných gramatických kategorií, bez kterého se neobejde parsing neboli syntaktická analýza dat vyžívaná při pokročilejších úlohách typu sentiment analysis neboli automatické identifikace emocí vyjádřených v textu. Mezi základní úlohy patří také odstranění obsahově prázdných či pro analýzu nedůležitých slov (spojek, předložek apod.) či obecná detekce jazyka pomocí n-gramového modelu.
Text mining, čili samotné vytěžování informací z textových dat, rovněž zahrnuje velké množství samostatných úloh. Jejich obecným cílem je obvykle obsahová analýza a automatizované vyhledávání skrytých vzorců v datech. Jedná se například o klasifikaci dokumentů, zmíněnou sentiment analysis či identifikaci pojmenovaných entit a vztahů mezi nimi. Ještě pokročilejší, ale v průmyslu řidčeji využívané, jsou pak úlohy jako automatická sumarizace, automatické odpovídání na otázky, sémantická analýza nebo strojový překlad.
Většina zmiňovaných úloh donedávna využívala standardní pravděpodobnostní modely především z oblasti strojového učení s učitelem (Naivní Bayesův klasifikátor, logistická regrese apod.), pro které bylo třeba mít k dispozici co možná největší množství trénovacích dat. V poslední době a díky nárůstu výpočetních kapacit však tyto postupy stále častěji nahrazuje tzv. hluboké učení, které zahrnuje jak algoritmy strojového učení s učitelem, tak i bez něj. Hluboké učení se nejčastěji využívá při trénování umělé neuronové sítě – výpočetním modelu pro distribuované paralelní zpracování dat, jehož předobrazem je chování biologických neuronů, a který dosahuje při zpracování většiny nestrukturovaných dat překvapivých výsledků. Dobrá performance je ostatně i důvodem, proč má řada nástrojů pro zpracování přirozeného jazyka tato algoritmy již implementovány, od open sources typu Google NLP po plně komerční řešení.
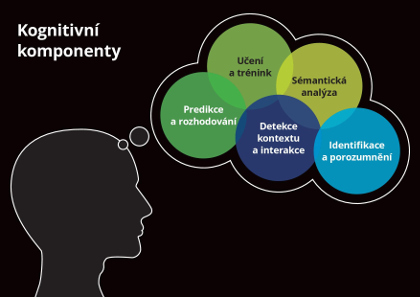
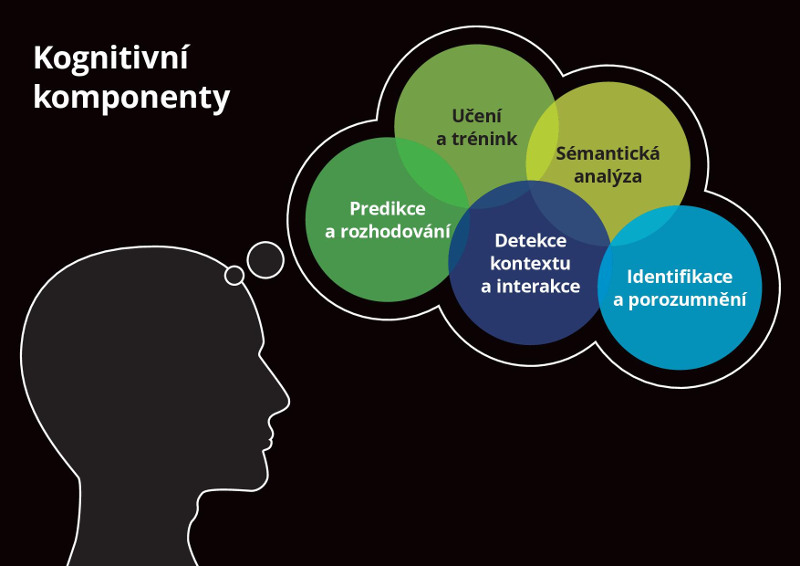
Deep Learning algoritmy jsou navíc využívány také v oblasti umělé inteligence a tzv. kognitivního programování, cognitive computingu, které se zpracování textových a všeobecně nestrukturovaných dat úzce souvisejí a ve velké míře s nimi pracují. Podobně jako umělá inteligence, i cognitive computing má za cíl imitovat výkon lidského mozku, včetně paralelního zpracování dat a asociativní paměti. Technologie spojené s cognitive computingem automaticky extrahují z dat koncepty a vztahy, „rozumějí“ jejich významu, učí se na základě nalezených vzorců a předchozích zkušeností a rozšiřují tak schopnosti, které mají lidé a stroje samy o sobě. Tento proces zahrnuje právě komplexní analýzu nestrukturovaných dat a jejich propojení s daty strukturovanými. Mezi kognitivní komponenty patří třeba rozpoznávání rukopisu, syntéza řeči nebo sémantická analýza, které mohou být využity například při vytváření personalizovaných digitálních asistentů ve formě chatbotů.
Byznysové přínosy vytěžování nestrukturovaných dat
Důvodů, proč by se společnosti měly snažit vytěžit svá nestrukturovaná data, a možností jejich využití, je bezpočet. Víme-li díky analýze, která data jsou platná a relevantní, můžeme značně snížit náklady na ukládání a zálohování dat. Automatizace manuálních vstupů či třídících procesů je navíc mnohem přesnější a výkonnější.
Mezi hlavní přínosy analýzy nestrukturovaných dat patří zlepšení procesů na odhalení rizik ohrožujících společnost, jako jsou například odliv zákazníků (customer churn), třeba na základě stížností zpracovávaných v rámci sentiment analysis, nebo nástup konkurence. Ve forenzní analytice pak lze vytěžit informace týkající se praní špinavých peněz nebo podvodů. V oblasti prediktivního modelování jde o zlepšení modelů ochoty k nákupu, získání bližších informací o zákaznících, o jejich životním stylu a smýšlení, to vše pro účely detekce loajálních klientů, personalizovaného marketingu i širšímu přizpůsobení marketingových kampaní.
Obecně jsou nestrukturovaná data využívána k zefektivnění firemních postupů. Skoro každá firma má dnes např. centrum zákaznické podpory, které musí zpracovávat velké množství klientských mailů. Není nic jednoduššího než tento proces automatizovat za pomoci kategorizace obsahu. V případě výstupů z call center lze díky voice-to-text analýze snadno zjistit nejčastější důvody hovoru. V rámci CRM je zase možno detekovat vztahy mezi klienty a získávat tak doplňující informace např. pro přístup Customer 360. Zákazníkům lze díky textové analytice usnadnit třeba prohledávání firemního webu a vést je tak k větší samostatnosti.
Interně mohou firmy snáze provádět např. monitoring korporátní komunikace, externě pak analyzovat obsah komunikace mimo firmu, například v příspěvcích na webových fórech nebo sociálních sítích (jejichž monitoring je mimo jiné důležitou podoblastí kybernetické bezpečnosti).
Závěrem
Jak již bylo řečeno v úvodu, ve firmách má zatím tradici zejména vytěžování dat strukturovaných. Ta nám říkají, jak se lidé chovají, neříkají nám však proč. Vztah se zákazníkem však nelze vždy popsat jen prostřednictvím čísel. Analýza nestrukturovaných dat již v mnohých úlohách ukázala, že může přispět například ke zlepšení prodejních výsledků nebo zmírnění odchodovosti klientů. I proto se řadí k nejdůležitějším oblastem, do nichž by firmy měly do budoucna investovat.
 |
Kateřina Veselovská Autorka článku je manažerkou v oddělení Data Analytics společnosti Deloitte, kde vede tým pro analýzu nestrukturovaných dat. Během své kariéry se věnovala jak vývoji softwaru pro textovou analytiku, tak business poradenství zejména v projektech týkajících se oblasti nestrukturovaných a velkých dat. V současné době se zaměřuje zejména na projekty z oboru forenzní analytiky a řízení rizik. |
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce