

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEMS 7-8/2018 , CRM systémy , Energetika a utility


Retence zákazníků v utilitách
Ing. Ondřej Brom
 S liberalizací trhu s elektřinou od roku 2006 a trhu se zemním plynem od roku 2007 postupně vznikalo v České Republice konkurenční prostředí. Větší počty zákazníků začaly měnit dodavatele až v letech 2010 či 2011. Od té doby je pohyb na trhu celkem živý a dá se očekávat, že bude růst s rostoucím povědomím a hlavně rostoucími zkušenostmi zákazníků. Prodejci energií proto stojí před úkolem získávat nové zákazníky, ale také udržet si stávající.
S liberalizací trhu s elektřinou od roku 2006 a trhu se zemním plynem od roku 2007 postupně vznikalo v České Republice konkurenční prostředí. Větší počty zákazníků začaly měnit dodavatele až v letech 2010 či 2011. Od té doby je pohyb na trhu celkem živý a dá se očekávat, že bude růst s rostoucím povědomím a hlavně rostoucími zkušenostmi zákazníků. Prodejci energií proto stojí před úkolem získávat nové zákazníky, ale také udržet si stávající.
Nástrojem k udržení zákazníka jsou nejčastěji retenční nabídky, ale podat takovou nabídku v době, kdy zákazník, často v zastoupení novým poskytovatelem, podává výpověď, je již pozdě. Zákazník má tou dobou obvykle sjednané dodávky u nového poskytovatele a zvrátit jeho rozhodnutí je obtížné. Na druhou stranu retenční nabídka zákazníkovi, který nemá v úmyslu odejít, zbytečně snižuje marži poskytovatele nebo může zákazníka vybudit k hledání nového poskytovatele energií. Z toho plyne nutnost umět odhadnout dopředu, zda zákazník má v úmyslu změnit dodavatele energií. To znamená vybudovat statistický model schopný ohodnotit riziko odchodu každého zákazníka na základě o něm známých informací.
Sestavení datové základny a řešení datových problémů
Poskytovatel má standardně k dispozici cenné informace o zákazníkovi. K dispozici bývají sociodemografické údaje, ale hlavně záznam historie chování zákazníka u poskytovatele. Nejde jen o samozřejmý vývoj spotřebovávaných energií, ale také údaje o platební morálce, o komunikaci zákazníka s poskytovatelem, o jeho chování na dalších odběrných místech, případně vývoj spotřeby druhé komodity atd. Záleží na poskytovateli, jaká data a v jakém rozsahu o zákazníkovi shromažďuje. Samozřejmostí je soulad s Obecným nařízením o ochraně osobních údajů (GDPR). Údaje obvykle nejsou shromažďovány zvlášť pro tyto účely, ale jde o běžné provozní údaje sloužící primárně k zajištění obsluhy zákazníka. Poskytovatel musí pouze zajistit, aby se uchovaly historické záznamy.
Princip odhadu budoucího chování zákazníka vychází z jeho historie. U každého zákazníka se stanoví datum v minulosti, ke kterému bude hodnocen (skórován). Je důležité zjistit, co se se zákazníkem dělo před i po datu hodnocení. Po datu hodnocení se sleduje, zda zákazník změnil během určitého období poskytovatele. Má-li se například předpovídat odchod zákazníka během jednoho roku, musí být datum hodnocení alespoň jeden rok v minulosti. Doba sledování je rozhodnutím uživatele předpovědi, např. pro plánování je vhodnější sledovat delší období, pro zacílení kampaní zase kratší.
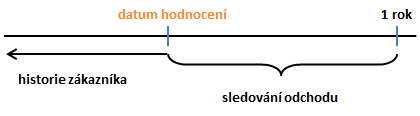
Zákazníci, kteří změnili poskytovatele před datem hodnocení, jsou pro odhad budoucího chování nepoužitelní, protože u nich odchod už nastal. Takoví zákazníci musejí být z dalších úvah vyloučeni. Proces změny poskytovatele neproběhne v jednom okamžiku, administrativně trvá až 3 měsíce, ale zákazník se na něj může připravovat ještě déle. Takže je nutné v celém procesu přesně stanovit událost, která se bude předpovídat. Ideálně je to okamžik, kdy se zákazník rozhodne poskytovatele změnit. Taková informace ale v datech obvykle není, tedy se musí volit například okamžik, kdy zákazník, přímo nebo v zastoupení, doručí poskytovateli výpověď. Z dalších úvah se proto vyloučí zákazníci doručivší výpověď před datem hodnocení.
Mnohem více práce je s obdobím před datem hodnocení. V něm se sleduje historie zákazníka. První rozhodnutí je, jak dlouhou historii vzít. Neměla by být příliš dlouhá, protože chování zákazníků se na trhu mění. Měly by v ní ale být zachyceny změny chování, což u standardních ročních fakturací znamená vzít do úvahy alespoň 2 roky dat. Právě dva až tři roky historie jsou obvykle dostatečné. Dále je třeba rozhodnout, co se v historii bude sledovat. To dopředu říci nelze. Nevíme, co vše může ovlivnit rozhodnutí zákazníka změnit poskytovatele. Je proto vhodné využít vše, co je k dispozici, ale i tak je téměř jisté, že nebudou k dispozici údaje o všem, co zákazníka ovlivňuje.
Sestavit historii zákazníka je z datového pohledu relativně komplikovaný proces. Zvlášť, pokud data pocházejí primárně z produkčního prostředí. Datový sklad v takové situaci velmi usnadní další činnost a umožní dosáhnut přijatelné flexibility při aktualizaci předpovědí. Z primárních dat je nutné odvodit mnoho nových ukazatelů, například procentní změnu spotřeby elektrické energie mezi dvěma následujícími roky. Nutností je software s rozsáhlými možnostmi datových manipulací.
Určení co, jak a čím modelovat
Důležité je rozhodnout se, pro co se bude odchod předpovídat. Nabízejí se dvě varianty: zákazník a odběrné místo (OM), resp. smlouva. Rozdíl je v tom, že jeden zákazník může mít více OM nebo smluv. Oba přístupy mají své pro a proti. Některé údaje se týkají zákazníka jako osoby (věk, pohlaví, atd.) a on pak na jejich základě rozhoduje o všech svých smlouvách, na druhou stranu jiné údaje se týkají konkrétního OM zákazníka. Zákazník navíc může změnit poskytovatele jen u některých svých OM, pracovat se zákazníkem jako celkem by pak bylo obtížné. Jako nejlepší se jeví pracovat na úrovni OM, ale k němu mít připojené i události z jiných OM zákazníka. Údaje navázané přímo na zákazníka se promítají na všechna jeho OM.
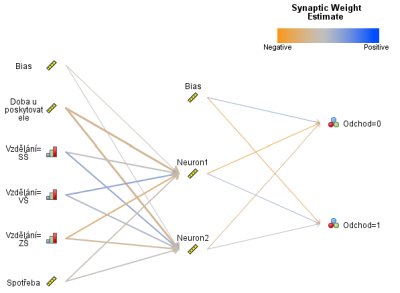
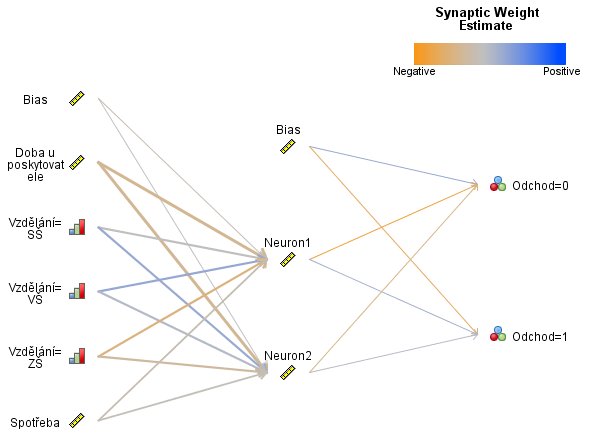
Po vytvoření ukazatelů z doby před hodnocením a zjištěním, zda nastala změna po datu hodnocení, se může přistoupit ke konstrukci samotné předpovědi. K tomu je nutné vytvořit statistický model. Model je algoritmus, jednouchá rovnice nebo složitý sled výpočetních operací, který ze vstupních ukazatelů spočítá nový ukazatel, mající vztah ke změně poskytovatele. Obvykle je vypočteným ukazatelem přímo pravděpodobnost, že zákazník poskytovatele změní. Typicky se předpovídá proměnná, která má dvě hodnoty, v tomto případě změna nebo setrvání u poskytovatele. Předpovídané proměnné se říká závislá nebo cílová. Algoritmus není pevná konstrukce, ale závisí na parametrech, které je třeba odhadnout právě z ukazatelů o zákazníkovi. Samotný výpočet parametrů zajistí vhodný statistický či dataminingový program.
Algoritmů existuje mnoho, výsledný se volí podle přesnosti, s jakou odchody předpovídá, ale také podle interpretovatelnosti. Často se používá logistická regrese, rozhodovací stromy nebo neuronová síť, ta ovšem za cenu nulové možnosti interpretace.
Odhad a evaluace vhodného modelu
Pro předpověď chování zákazníka nikdy však nebudou nutné všechny ukazatele. Je typické, že zákazník je popsán mnoha desítkami různých ukazatelů, ale v modelech se obvykle používá jen malý počet ukazatelů, asi do 20 nebo i méně. Velkým úkolem je tedy vybrat vhodné ukazatele do modelu. Síla vztahu ukazatele a závislé proměnné se dá měřit běžnými statistickými testy. Na jejich základě se vyřadí ukazatele, které o závislé proměnné nic neříkají. Testy zkoumají vztah ukazatelů k závislé proměnné bez ohledu na vliv jiných ukazatelů, ale v realitě vždy mezi ukazateli existují vzájemné vztahy a vlivy na závislou proměnnou se prolínají. Výběr kompletní sady proměnných je proto složitý. Často se používá kombinace přístupů založených na expertní znalosti poskytovatele a různé statistické metody pro výběr proměnných. Určité metody jsou také součástí modelovacích algoritmů.
Když jsou proměnné vybrány a koeficienty modelu odhadnuty, je třeba model otestovat tak, aby test co nejvíce odpovídal jeho reálnému použití. Model se bude používat na nové případy, na kterých nebyl odhadnut. Testován by měl být proto na případech nepoužitých pro jeho odhad. Z toho důvodu jsou data před odhadem rozdělena náhodně na část trénovací a testovací. Na trénovací části se model odhadne a na testovací ověří. Testovací data model nijak neovlivnila, ale je u nich známa hodnota cílové proměnné (odchod). Je tak možné srovnat předpověď modelu a skutečnost. K tomu se používají různé ukazatele, např. ROC křivka a z ní vycházející Ginniho koeficient. Je-li model ze statistického hlediska správný, může se přikročit k jeho použití v reálném rozhodovacím procesu.
Implementace řešení do produkčních systémů a jeho přínosy
Aby se dal model použít, je obvykle nutné ho implementovat do informačních systémů poskytovatele. To může být často velmi obtížné. Záleží na tom, kde a jak se budou realizovat výpočty. Nejsnazší je, když výpočty provádí software, kde byl celý proces vyvinut a do systémů poskytovatele se předá jen výsledek, např. ve formě databázové tabulky. Má-li být integrace hlubší a data zpracovávána přímo v informačních systémech, je třeba počítat s tím, že v systémech se musí nejen odhadnout model, ale i provést všechny datové operace s tím spojené. Výhodou je přímočařejší a obvykle i rychlejší proces výpočtu. Nevýhodou celková pracnost takové integrace. Odhad pravděpodobnosti odchodu není třeba počítat každý den, často postačí měsíční, čtvrtletní nebo i delší intervaly. Integrovat celý proces do systémů poskytovatele je pak zbytečné a nákladné.
Model se v praxi používá tak, že se k určitému datu, např. každé čtvrtletí, spočítá historie všech zákazníků a na získané proměnné se použije model. Ten vypočítá pravděpodobnost odchodu pro budoucí období. Poskytovatel tím získá informaci o zákazníkovi a může ji využít v marketingových procesech, např. pro zacílení retenční kampaně. Model by se měl testovat nejen statisticky, ale i z hlediska jeho praktického přínosu. K tomu účelu je vhodné náhodně vyčlenit kontrolní skupinu zákazníků a s nimi pracovat způsobem, který poskytovatel používal před zavedením modelu. Srovnáním výsledků retence na kontrolní a modelované skupině se definitivně zjistí, jaký přínos byl používáním modelu získán. Pomocí hodnoty zachráněných zákazníků ho pak lze i finančně vyčíslit.
Používání modelů pro retenci se stává běžnou součástí konkurenčního boje a umožňuje poskytovateli reagovat na změny trhu rychleji než podle zkušeností marketingových pracovníků, pro jejichž vytvoření je třeba delší doba.
 |
Ing. Ondřej Brom Autor článku je lektor, analytik a odborný konzultant ve společnosti ACREA CR, spol. s r.o. Ve své činnosti se zaměřuje na realizaci dataminingových projektů a výuce data miningu. Věnuje se ale také řešení statistických úloh a výuce statistických metod, zejména lineární regrese a časových řad. |
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce