

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Hlavní partner sekce

Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEMS 11/2012 , AI a Business Intelligence


Predikce prodeje s pomocí kontextové analýzy
 Předpověď poptávky je jedním ze základních úkolů podnikového plánování. Přesné a včasné predikce prodeje jsou zásadní například pro řízení zásob, potravinářské velkoobchody a maloobchodní sektor i jinde. S ohledem na velké množství faktorů, které poptávku ovlivňují, je přitom její predikce složitým úkolem. Odpovědí na tyto výzvy je využití kontextové analýzy.
Předpověď poptávky je jedním ze základních úkolů podnikového plánování. Přesné a včasné predikce prodeje jsou zásadní například pro řízení zásob, potravinářské velkoobchody a maloobchodní sektor i jinde. S ohledem na velké množství faktorů, které poptávku ovlivňují, je přitom její predikce složitým úkolem. Odpovědí na tyto výzvy je využití kontextové analýzy.
Spotřebitelská poptávka může být ovlivněna různými faktory – typicky cenou, reklamou, spotřebitelskými preferencemi, počasím a jejich změnami. K základním kvantitativním metodám pro její predikci patří analýza časových řad, jejímž cílem je odhalení trendů a vzorů v datech, a jejich využití. K dalším nejčastěji používaným kvantitativním metodám patří využití neuronových sítí a metod dolování dat.
V současné době jsou tyto předpovědi odbytu prováděny lidmi, kteří mají znalosti a zkušenosti s prodejem určitého zboží, s tím, jak se mění prodeje výrobků během roku v závislosti na dobrém nebo špatném počasí, letním období, způsobu propagace a reklamy a podobně. Tyto zkušenosti používají pro úpravy výchozích předpovědí provedených pomocí analytických metod. Ze svých zkušeností odhadují vliv některých faktorů na spotřebitelskou poptávku – nadcházející svátky (školní, národní nebo náboženské), období dovolené, změnu a další. Hovoříme o kvalitativních metodách predikce spotřebitelské poptávky.
Mohou zde však působit lidské faktory, jako je frustrace, přetížení informacemi, chybějící odborné znalosti (zejména u nových pracovníků nebo pro nové výrobky) nebo jednoduše zapomnětlivost. Ty mohou mít za následek nevhodné předpovědí a špatné rozhodování. Sezonnost, kterou lze definovat jako externí faktory závisející na čase ovlivňující spotřebitelskou poptávku a způsobující její různé změny, tak nemusí nutně znamenat přísnou periodicitu. Zpřesnění předpovědi spotřebitelské poptávky, případně odstranění výše uvedených nepřesných předpovědí, je možné jen zapojením kontextu do procesu predikce pro předpověď spotřebitelské poptávky. Tedy využitím softwaru, který integruje kontext do kvantitativních metod predikce.
Co je to kontext a kontextová analýza?
Kontext určitého systému (např. informačního) definujeme jako jakoukoliv informaci charakterizující okolní situaci, podmínky a okolní subjekty, které mají určitým způsobem vztah k tomuto systému nebo jeho uživatelům. Kontextu můžeme využít na vysoké nebo nízké úrovni abstrakce. S použitím kontextové analýzy na nízké úrovni abstrakce se setkáváme často. Příkladem může být automatická změna hlasitosti autorádia v závislosti na hluku ve vozidle nebo změna nabídky v aplikaci v závislosti na výběru určitého příkazu apod. Využití kontextu na vysoké úrovni abstrakce je složitější. Zde již můžeme mluvit o kontextové analýze, kde obvykle není možné jednoduše zahrnout uvažovaný kontext do systému.
Základní otázka řešená vývojáři systémů využívajících znalostí kontextu na vyšší úrovni abstrakce je, jak integrovat informace o kontextu do těchto systémů, aby se dosáhlo určitého zlepšení chování systému v závislosti na kontextu, například lepší predikce změn ve spotřebitelské poptávce. Přitom se řeší následující otázky:
- Jak definovat kontext (jeho formu), jak například definovat a udržovat kontextové kategorie? Kontextová informace může být velmi rozmanitá. Je proto vhodné kontext kategorizovat jak z důvodu jeho snazšího pochopení, tak zejména z důvodu různého způsobu využití kontextu v různých kategoriích a práce s ním v aplikaci.
- Jak propojit kontext například s procesem predikce pro předpověď spotřebitelské poptávky? Může jít o různé způsoby využití kontextu v aplikacích. Prvním způsobem je prezentace kontextové informace jako takové nebo zobrazení určité nabídky s výběrem akcí pro uživatele dle aktuálního kontextu. Druhým způsobem využití je automatické spouštění určité služby při změně kontextu a třetím způsobem využití kontextu je jeho uložení pro pozdější využití při zpracování dat.
- Jak integrovat mechanismy detekce změn kontextu do procesu predikce? Týká se například možností rozšíření mechanismů, které umožňují načíst kontext z externích zdrojů. V souvislosti s tím mohou být definovány další vrstvy potřebné pro zpracování takových informací.
- Jak by měla být navržena architektura systému umožňující propojení informací o kontextu s určitou aplikací? Jaké vrstvy by aplikace měla mít? Jaké bude uživatelské rozhraní? Do jaké vrstvy zahrnout hlavní složky aplikací využívající kontext – interprety, agregátory a další služby.
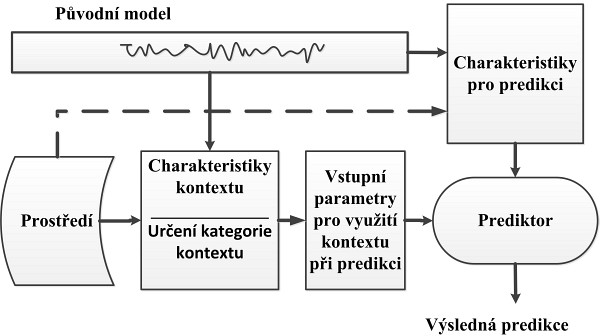
Schéma procesů predikce s využitím kontextové informace
Proces predikce poptávky po konkrétním výrobku s využitím kontextu si můžeme představit v následujících krocích. Nejdříve extrahujeme charakteristiky původní historické časové řady tržeb produktu. Potom přiřadíme produkt do jedné z kategorií. Vybereme kontextové charakteristiky spojené s určitou kategorií. Charakteristiky původní časové řady a kontextové charakteristiky jsou vstupními veličinami prediktoru. Výsledné hodnoty mohou být nyní použity pro rozhodování v obchodním procesu.Příklady z praxe
Typickým příkladem využití kontextové analýzy pro předpověď poptávky je energetika. V této oblasti se kontextová analýza již začíná využívat. Kontinuální vyvážení energetické poptávky s nabídkou je základním předpokladem pro stabilitu a účinnost energetických sítí. Toto vyvažování vyžaduje přesné prognózy budoucí spotřeby elektřiny a výroby v libovolném bodě a čase. Pro tento účel musí být databázové systémy schopny rychle zpracovat dotazy týkající se prognózování a poskytnout přesné výsledky v krátkých lhůtách. Zpracování časových řad spotřeby elektřiny není jednoduchým úkol, protože k časové řadě jsou neustále přidávána nová měření. Použití jednoduchých přístupů pro vyvíjející se časovou řadu by znamenalo nový odhad příslušným matematickým modelem od nuly pro každé nové měření, což je časově velmi náročné. Z tohoto důvodu se s ohledem na zvláštnosti časových řad spotřeby elektřiny využívá dříve spočtených modelů spotřeby a kombinace jejich parametrů. Tyto kombinace parametrů a informace o kontextu, ve kterém platily, se ukládají do databáze. Potom se porovnává aktuální kontext s kontextem uloženým v databázi a z databáze se vybírají kombinace parametrů s kontextem podobným aktuálnímu kontextu a berou se jako výchozí body pro další optimalizaci.
Předpovědi pomocí kontextové analýzy se dnes rozšiřují především v oblasti webové analytiky. Ta je zaměřena na pochopení vzorců chování, a to na základě dat o chování návštěvníků užívajících obsah webových stránek a aplikací. Webová analytika je ve své podstatě citlivá na kontext. Chování se může lišit v závislosti na kontextu a potenciálně v rámci kontextu. Lze tedy očekávat, že jeho zahrnutím do predikčních modelů webové analytiky budou předpovědi chování zákazníků přesnější, a to včetně předpovědí prodejů.
Pokud dokážeme co nepřesněji předpovědět chování zákazníků za určitých okolností (v rámci určitého kontextu), můžeme dosáhnout personalizace a přizpůsobení různým potřebám zákazníků a jejich preferencí. Kontext můžeme uvažovat v rovině časové, geografické, v rovině určitých činností nebo chování apod. Jako příklad mohou sloužit webové stránky nabízející na vyžádání video (televizní pořady, filmy, dokumentární pořady). Chování koncového uživatele na těchto webových stránkách se může lišit v závislosti na kontextu jeho potřeby. Uživatel může například hledat konkrétní dokumentární pořad potřebný jako zdroj informace pro práci nebo může hledat nové zábavné filmy, když už je doma a odpočívá. Nákupní chování se také mění v závislosti na době dovolených nebo v závislosti na počasí. Počet kontextových faktorů, které mohou ovlivnit chování návštěvníků na webových stránkách, je však často velmi rozsáhlý, proto není možné toto chování modelovat explicitně. Jedním z klíčových úkolů je tedy vybudovat mechanismy, které by identifikovaly aktuální kontext a které by řešily mechanismy pro jeho začlenění do predikčních modelů.
Budoucnost kontextové analýzy v podniku
V současné době jsou systémy pro prediktivní analýzu dodávány například společnostmi SAS (SAS Enterprise Miner), SPSS (Insightful Miner), KXEN (KXEN Analytic Framework), IBM (DB2 Intelligent Miner for Data), Dynamic Future (PREWIT), Economic Wizard (expertní systém Forecast Wizard) a dalšími. Použití kontextové analýzy u těchto aplikací se však začíná teprve rozvíjet. Příklady z jiných oblastí ale ukazují, že zahrnutí kontextové informace do aplikací pro předpověď může být velmi užitečné. Aplikace samotná pak může být na trhu velice úspěšná. Za všechny jmenujme službu Flightcaster, která je určena cestujícím letadlem po USA. Ta provádí predikce, zda bude let opožděn či nikoliv. Aplikace (webová) využívá dostupné historické údaje o letecké dopravě včetně příslušného kontextu, jako jsou podmínky na letišti, typ letadla, počasí a další. Její tvůrci uvádějí, že až 95 procent všech zpoždění mohou predikovat. Uživatelé se mohou podívat na předpověď zpoždění jejich letu na webové stránce nebo přes mobilní aplikaci.
I přes problémy, které jsme uvedli výše, je využití kontextové analýzy při predikcích velmi perspektivní směr vývoje, a tak se v budoucnu i v běžné podnikové praxi setkáme s různými aplikacemi využívajícími jejích principů, které budou dostatečně generické a současně vysoce přesné a účinné.
Ladislav Beránek
Ing. Ladislav Beránek, CSc., MBA, působí jako vysokoškolský učitel na Jihočeské univerzitě v Českých Budějovicích, Ekonomické fakultě, katedře aplikované matematiky a informatiky.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce