

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Hlavní partner sekce

Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEMS 7-8/2011 , ITSM (ITIL) - Řízení IT



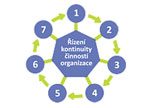
Obr. 1: Proces tvorby řízení kontinuity

Obr. 2: Optimální výdaje na zajištění kontinuity
Jak na havarijní plány a plány obnovy ICT infrastruktury?
 Každý, kdo měl na starosti chod ICT zázemí, řešil otázky v souvislosti s možnými havarijními situacemi, kdy část ICT může být z různých důvodů mimo provoz a s ním i některé firemní procesy. Předcházení těmto nestandardním stavům je dílčí část pracovní náplně odpovědných zaměstnanců společně s jejich rutinní správou ICT. S rostoucími požadavky na dostupnost prostředků informačního systému rostou i požadavky na zajištění kontinuity ICT a tyto požadavky stále více vedou k budování havarijních plánů a plánů obnovy ICT, tj. DRP – disaster recovery plans. Jak takové plány vytvořit? Co vše mají obsahovat a v čem nám vlastně mohou pomoci? Na tyto otázky jsme se zeptali Martina Tobolky, konzultanta společnosti AEC.
Každý, kdo měl na starosti chod ICT zázemí, řešil otázky v souvislosti s možnými havarijními situacemi, kdy část ICT může být z různých důvodů mimo provoz a s ním i některé firemní procesy. Předcházení těmto nestandardním stavům je dílčí část pracovní náplně odpovědných zaměstnanců společně s jejich rutinní správou ICT. S rostoucími požadavky na dostupnost prostředků informačního systému rostou i požadavky na zajištění kontinuity ICT a tyto požadavky stále více vedou k budování havarijních plánů a plánů obnovy ICT, tj. DRP – disaster recovery plans. Jak takové plány vytvořit? Co vše mají obsahovat a v čem nám vlastně mohou pomoci? Na tyto otázky jsme se zeptali Martina Tobolky, konzultanta společnosti AEC.
Jak pomůže DRP v případě havárie v ICT?
V případě havárie v ICT vám implementované řízení kontinuity (business continuity management), jehož podmnožinou je i DRP, umožní v co nejkratších lhůtách zajistit obnovu provozu informačního systému, aniž by to mělo negativní dopad na plnění legislativních a interních požadavků, stanovených podnikatelských záměrů a smluvních povinností vůči zákazníkům, akcionářům či obchodním partnerům.
DRP tedy poskytuje záruky, že ICT je připraveno řešit havarijní situace?
Po implementaci řízení kontinuity firma ví, jak zvládne provoz ICT při nejčastějších technických selháních, jako je výpadek dodávek energie, selhání technického nebo programového vybavení, přizpůsobení přírodních živlů, tedy například požár, povodeň. Při selhání lidského faktoru, kde může jít o hrozby úmyslné i neúmyslné – chyby uživatelů, podvody, krádeže, napadení informačního systému apod.
Jak zjistit, která technická selhání nejvíc ovlivní chod ICT, potažmo celé firmy?
Pomocí analýzy dopadů a analýzy rizik je specifikována pravděpodobnost výskytu rizik a finanční náklady při výpadcích různých procesů firmy a je na míru vypracována strategie obnovy klíčových procesů včetně priorit obnovy. Standardy v této oblasti jsou BS 25999 (Code of Practice for Business Continuity Management) a BS 25777 (Information and communications technology continuity management). Proces tvorby řízení kontinuity je zobrazen na zjednodušeném schématu (obr. 1).

Obr. 1: Proces tvorby řízení kontinuity
V čem spočívá strategie obnovy?
Jde o nastavení RTO a RPO parametrů s ohledem na provedenou analýzu dopadů. RTO (recovery time objective) představuje maximálně akceptovatelný čas výpadku firemního procesu, RPO (recovery point objective) maximální přípustnou ztrátu dat za definovaný čas. Oba parametry mohou být různé.
Jak se docílí stanovených RTO a RPO?
Pokud je definována strategie a identifikovány kritické procesy firmy včetně vazby na ICT technologie, pak se vypracovává seznam technicko-organizačních opatření, jejichž náklady na realizaci musí být v rovnováze s náklady z analýzy dopadů. V oblasti technické jde o investice do infrastruktury, záložních zdrojů, náhradní lokality apod. U organizačních opatření jde o aktualizaci stávajících interních dokumentů, seznámení uživatelů s jejich povinnostmi a odpovědnostmi, změny smluvních vztahů s dodavateli reflektující nové požadavky na dodávané služby atd.
RTO a RPO tedy pomáhá zamezit zbytečně drahým opatřením?
Přesně tak, nepotřebujete atomový kryt na serverovnu, kterou máte duplicitně v jiné lokalitě a RTO máte 24 hodin. Optimální výdaje demonstruje následující obrázek (obr. 2).

Obr. 2: Optimální výdaje na zajištění kontinuity
Jaké havarijní oblasti by měly DRP plány pokrývat?
To vyplyne z provedených analýz rizik a dopadů – tj. vhodné scénaře k pokrytí jsou výpadky elektřiny, působení vody, požár, výpadek klimatizace v serverovně, výpadek internetu, selhání datové sítě, působení počítačových virů, napadení technologického systému hackerem, selhání klíčového hardwaru apod.
Co by měly obsahovat DRP plány?
Havarijní plán ICT popisuje činnosti, které je potřeba začít provádět bezprostředně po zjištění mimořádné události, na kterou je havarijní plán sestaven (např. selhání klimatizace v datacentru). Musí v nich být uvedeno, kdo může havarijní plán spustit, kdo má co dělat, v jakém pořadí, jaký je účel plánu a jaký je cílový stav po realizaci havarijního plánu. Plán obnovy předpokládá dokončení příslušného havarijního plánu. Jedná se o technicky zaměřený plán určený pracovníkům ICT, který umožní obnovu ICT s návratem procesů firmy k běžnému provozu. Plán nouzového provozu definuje pracovní postupy a činnosti, kterými lze udržet kritické procesy firmy alespoň v omezené míře do té doby, než bude obnoven informační systém tak, aby dopad na chod organizace byl minimální. Definuje alternativní postupy, kterými lze po stanovenou dobu provádět kritické činnosti bez prostředků ICT. V plánech je vhodné uvést orientační časovou osu sledu událostí vedoucí k zajištění RTO a RPO.
Jaké jsou dnes trendy v řešení technických opatření k dosažení RTO, RPO?
Jednoznačně využití virtualizace serverů, kdy několik fyzických serverů je spojeno v jeden virtuální cluster a každý dílčí virtuální server lze jednoduše zálohovat. Obnova na jiném fyzickém serveru, na kterém je k dispozici virtuální server, je pak otázkou nikoliv hodin, ale minut. Na trhu již existují produkty, které jsou schopny zálohovat a obnovovat libovolné kombinace fyzických i virtuálních serverů, tj. včetně neobvyklé možnosti obnovy virtuálního serveru na fyzický server či přenosu fyzického serveru na jiný fyzický server s jinou hardwarovou konfigurací – v těchto případech se samozřejmě využívá opět virtualizace, není však třeba mít připravené virtuální (licencované) prostředí.
Jak ověřit, že firma má dobré DRP?
Mnoho organizací má zdokumentováno něco, čemu říká plán kontinuity (BCM) a co je často sepsáno na základě potřeby splnění požadavků různých ISO certifikací či požadavků zahraničního vlastníka organizace. Není nutné rozvádět, že formálně sepsané řízení kontinuity a jeho DRP v případě havárie moc nepomůže, zvlášť pokud není pravidelně testované a aktualizované. Aby byla zajištěna kvalita, efektivnost a aktuálnost firemního procesu řízení kontinuity, je nutná právě jeho údržba, testování a aktualizace plánů a dále vzdělávání zainteresovaných uživatelů zaměřené na pochopení procesů spojených s DRP.
Jak ověřit, že ICT oddělení je připraveno zvládnout havarijní situace?
Běžná praxe při rozhovoru s vedoucím ICT oddělení je, že incidenty určitě zvládnou, že při výpadku elektřiny mají UPS, že v serverovně jsou protipožární čidla, na servery mají technickou podporu a že data přece zálohují na pásky. Tento výčet možná kdekoho uklidní, vždyť to v ICT vždy nakonec nějak zvládli. Nemuseli však třeba zatím čelit rozsáhlejšímu incidentu, či přímo katastrofě. Při rozhovoru s vedoucím ICT je třeba rozhovor vést v rovině příkladů možných havárií a zkoumat míru připravenosti ICT na zvládnutí nastalé situace a zaměřit se na odhadnutou dobu obnovy.
Jak tedy vyhodnocovat interview s pracovníky ICT?
Pokud vám vedoucí ICT na otázku, jak dlouho bude trvat obnova porouchaného diskového pole, na kterém máme technologická data pro řízení výroby, odpoví, že je servisní smlouva NBD a že zavolají, aby to opravili, tak počítejte s tím, že například výroba stojí do příštího pracovního dne, kdy bude diskové pole opraveno. Dále počítejte s tím, že diskové pole bude třeba muset být kompletně nahrazeno novým kusem a veškerá data bude třeba nahrát ze zálohy na páskách. Připočítejte si další den na konfiguraci nového pole, obnovu dat a nakonec se smiřte s tím, že data za poslední dvě směny nejsou k dispozici, protože poslední záloha diskového pole na pásku proběhla večer před havárií diskového pole. Suma sumárum výroba stojí dva dny a k části výrobků, které byly zhotoveny za uvedené dvě směny v době před havárií, nejsou data, která jsou potřeba například pro ověření jakosti výrobků, a produkty tak nemohou být expedovány
Co vede firmy k tomu, že začínají řešit plánování kontinuity a DRP?
Určitě trend konsolidace dat a aplikací zvyšuje požadavky na kontinuitu. Mnoho organizací v minulosti necítilo potřebu řešit DRP, protože závislost na ICT nebyla tak velká a například výroba mohla nějakou dobu běžet nezávisle na tom, zda funguje datová síť organizace. S nástupem nových technologií pro automatizaci výroby a její vizualizaci roste náročnost na součinnost s ICT. Během výroby jsou používána data, která putují obousměrně mezi databázovým serverem a technologickými prvky (PLC apod.). Důsledky ztráty těchto datových toků a dat samotných má stále vyšší dopad právě díky masivní konsolidaci technologických prvků s ICT. Zatímco v nedávné minulosti jste mohli v případě havárie obnovit nejdříve kritické aplikace, a méně důležité aplikace později, tak dnes u integrovaných aplikací typu ERP jsou rázem všechny aplikace kritické. Chcete-li obnovit řízení dodavatelského řetězce, procesy skladů, podporu prodeje, účetnictví a finanční vykazování – to vše využívá ERP a je to uloženo většinou na stejném databázovém serveru jako data z technologických prvků výroby. Při technickém selhání databázového serveru je masivní dopad na kontinuitu podniku více než zřejmý.
Martin Tobolka působí jako senior IT security consultant společnosti AEC, člena Cleverlance Group. Je rovněž vedoucím auditorem ISO 27001 (ISMS) a ISO 20000 (ITSM) certifikačního orgánu CQS, člena IQNet.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce