

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEMS 3/2005

OLAP řešení pro malé a střední firmy
V době, kdy byly definovány původní zásady OLAP technologií, došlo k poměrně striktnímu rozdělení světů vlastního informačního systému organizace (OLTP) a analytických nástrojů OLAP, převážně reprezentovaného datovými sklady. V souvislosti s OLAP se začalo hovořit o „manažerských“ systémech, přičemž již samotný název vzbuzuje pocit, že jsou určeny pouze pro privilegovanou skupinu uživatelů. Pravda je však taková, že pokud mají procesy v organizaci probíhat optimálně, je důležité, aby byly přehledné podklady pro rozhodování dostupné pro všechny její pracovníky.
Většina informací, které jsou pro řízení firmy potřeba, je navíc provozního charakteru. Otázky typu: „Jaké jsou nové zakázky?“ nebo „Máme daný výrobek na skladě?“ jistě zaznívají častěji než „Jaké jsou přehledy tržeb za posledních pět let?“.


Zásadními principy definovanými v rámci OLAP jsou multidimenzionální přístup a hierarchická struktura dimenzí. Multidimenzionální přístup dává možnost sledovat data z různých úhlů pohledu, hierarchická struktura dimenzí umožňuje pohledy na data v různém stupni agregace. Pokud přijmeme konstatování, že oba uvedené principy nejsou výsadou pouze OLAP, nýbrž, že jsou i v rámci OLTP použitelné, obě oblasti splynou. Otázka, zda mají být data čerpána z primárního informačního systému, či z datového skladu se poté redukuje na otázku, co je vhodnější z hlediska technické realizace.
Hlavními kritérii přitom jsou:
· dostatečně rychlá odezva datového serveru na dotazy (při překročení určitého objemu dat a komplikovanosti vnitřní struktury informačního systému již nelze čerpat výstupy z primárních dat s uživatelsky únosnou časovou odezvou),
· požadavek na aktuálnost dat (data uložená v datovém skladu budou vždy méně aktuální),
· realizovatelnost výstupu (některé údaje nelze získat z primárních systémů přímo, je nutno je vypočítat či provést jejich transformaci),
· požadavek na konsolidaci dat z různých heterogenních zdrojů (některá data jsou uložena mimo datové servery, je potřeba je na datový server nejprve převést).
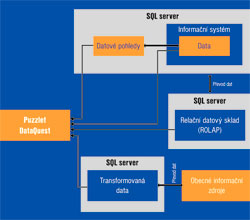
Obr. 1: Schéma spolupráce nástroje Puzzlet DataQuest s datovými zdroji
V každém případě by uživatel neměl být zatěžován znalostí, kde jsou data, se kterými právě pracuje, uložena, měl by však mít k dispozici informaci, jak aktuální jsou. Rozhodování je proces, který do velké míry souvisí s předchozí zkušeností a s porovnáváním současných jevů s jevy minulými. I když jsou nástroje pro podporu rozhodování navrhovány s velkou variabilitou výstupů, uživatel si po čase vytvoří (nebo nechá vytvořit) vlastní skupinu sestav, které používá v rámci svých rozhodovacích procesů. Dokáže tak velmi rychle rozpoznávat odchylky od žádaného stavu či významné hodnoty a následně využít všech možností nástroje k odhalení jejich příčin. Vzhledem k tomu, že to vyžaduje jeho aktivní přístup, je velmi důležitý i výběr prezentačního prostředí. Lze rozlišit tři základní typy:
· Internetový prohlížeč - jeho výhodou je dostupnost bez ohledu na geografické hranice a konkrétní operační systém, je velmi dobře použitelný pro standardizované sestavy a přehledy. Málo vhodný, pokud chce uživatel s daty dále aktivně pracovat.
· Samostatná aplikace - vytváří prostor pro podrobnou analýzu dat, zahrnuje řadu doplňkových funkcí pro jejich zpracování. Uživatel se musí naučit specifické ovládání, aplikace je často závislá na konkrétním operačním systému nebo na databázové platformě.
· Integrace do již existující aplikace (většinou tabulkového procesoru) - umožňuje následnou práci uživatele se získanými daty v prostředí, které dobře zná. Omezením je závislost na dané aplikaci na operačním systému.
Obr. 2: Schéma uložení dat v Puzzlet DataQuest
V řadě menších, ale i středních organizací se můžeme setkat s následujícím stavem informačního systému:
· jednotlivé agendy jsou vedeny paralelně na několika místech v různých formátech (často je pokryto účetnictví jedním informačním systémem, CRM řešení systémem nekompatibilním atd.)
· využívá se file server technologie, teprve postupně se přechází na technologii klient/server,
· k analýzám a vyhodnocování se převážně využívá Microsoft Excel, data se v lepším případě do tohoto programu importují prostřednictvím externích dotazů, často i ručně,
· s některými daty (např. výstupy z pokladních systémů) se pracuje pouze na provozní úrovni, nevyužívá se veškerý jejich informační potenciál.
U tohoto typu organizací je otázkou, jak zajistit systém pro přehledné reportování s minimálními investičními náklady a s maximálním využitím všech informačních zdrojů takové organizace. Nástroje pro podporu rozhodování dostupné na našem trhu jsou v řadě případů velmi úzce navázány na konkrétní komerční databázovou platformu (pořizovat ji pouze za účelem reportingu by bylo pro tyto organizace neefektivní), některé se navíc soustřeďují pouze na oblast multidimenzionálních kostek, což však neřeší případy, kdy je potřeba výstupy získávat také přímo z provozních dat.
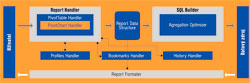
Obr. 3: Architektura nástroje Puzzlet DataQuest
V souladu s výše uvedenými poznatky byly definovány požadavky na reportovací nástroj v následujících bodech:
· umožnit spolupráci s Microsoft Excel (jeho vysoká dostupnost ve většině organizací),
· nezávislost na konkrétní databázové platformě,
· napojení jak na provozní data, tak i na datové sklady,
· možnost vytvářet předpřipravené sestavy,
· sdílení informací v rámci lokální sítě organzace.
Podle těchto požadavků byl vytvořen klientský nástroj Puzzlet DataQuest, který je přímo integrován do Microsoft Excel. Je založen na technologii jazyka SQL, kterou lze realizovat na širokém spektru komerčních i open source databázových systémů. Uživatel v něm pracuje se sešity nazývanými sestavy. Každá sestava obsahuje právě jedna data zobrazená v režimu kontingenční tabulky či grafu. Nástroj umožňuje paralelní práci s řadou takovýchto sestav, kdy každá z nich má autonomní vlastnosti. Konkrétní nastavení sestavy se promítá do jejího interního popisu (Bookmark Definition), který je možno uložit. To ve svém důsledku znamená:
· Puzzlet DataQuest nevyužívá žádný uložený soubor ve formátu Microsoft Excel, plně dokáže nahradit řadu objemných sešitů plných datových tabulek,
· ukládané informace obsahují pouze definice, což jednak minimalizuje jejich objem (řádově několik kB), jednak umožňuje jejich sdílení a distribuci bez rizika narušení bezpečnosti,
· práce se sestavou je monitorována, uživatel se může vracet ke svým předešlým krokům (v rámci každé jednotlivé sestavy nezávisle),
· aktuální podobu sestavy lze v kterýkoliv okamžik uložit ve formě tzv. záložky, která je následně k dispozici prostřednictvím nabídky i pro ostatní uživatele v rámci lokální sítě (pokud k tomu mají příslušná práva).
Vlastní zdroje dat (datové kostky) jsou definovány v rámci struktury Data Source Definition. Ta zahrnuje jednak popis fyzického uložení dat (včetně případů reprezentace dat více fyzickými datovými strukturami s různou úrovní agregace), jednak popis abstraktní vrstvy (popisy faktů, dimenzí a jejich hierarchie). Uživatel je tak "odstíněn" od datového zdroje a pracuje pouze s pojmy, jako je zákazník, čas, tržba apod. Při práci s nástrojem je maximum zátěže při zpracování dotazů ponecháno na datovém serveru, podle aktuálního nastavení sestavy je přenášeno jen nezbytné množství dat. V rámci interaktivní práce se sestavou je důraz kladen na jednoduchost ovládání vycházející ze zvyklostí Microsoft Excel a využívající ve velké míře tlačítek myši v kombinaci s řídicími klávesami. Lze tak jednoduše provádět operace, jako je drill-down/up (rozpad na data o nižší či vyšší úrovni), filtrování, mezisoučty, nastavení řazení apod. Formátovací modul zajišťuje přehledné zobrazení dat, včetně možnosti zvýraznění limitních hodnot. Použití Puzzlet DataQuest je vhodné jak pro méně zkušené uživatele, kteří přistupují pouze k předem připraveným sestavám prostřednictvím nabídky, tak pro uživatele, kteří definují vlastní sestavy výběrem a umístěním dimenzí a faktů, nastavením filtrů a dalších funkcí.
Autor článku, Ing. Tomáš Kratochvíl, je konzultantem v oblasti firemního řízení a informačních systémů.
Zásadními principy definovanými v rámci OLAP jsou multidimenzionální přístup a hierarchická struktura dimenzí. Multidimenzionální přístup dává možnost sledovat data z různých úhlů pohledu, hierarchická struktura dimenzí umožňuje pohledy na data v různém stupni agregace. Pokud přijmeme konstatování, že oba uvedené principy nejsou výsadou pouze OLAP, nýbrž, že jsou i v rámci OLTP použitelné, obě oblasti splynou. Otázka, zda mají být data čerpána z primárního informačního systému, či z datového skladu se poté redukuje na otázku, co je vhodnější z hlediska technické realizace.
Hlavními kritérii přitom jsou:
· dostatečně rychlá odezva datového serveru na dotazy (při překročení určitého objemu dat a komplikovanosti vnitřní struktury informačního systému již nelze čerpat výstupy z primárních dat s uživatelsky únosnou časovou odezvou),
· požadavek na aktuálnost dat (data uložená v datovém skladu budou vždy méně aktuální),
· realizovatelnost výstupu (některé údaje nelze získat z primárních systémů přímo, je nutno je vypočítat či provést jejich transformaci),
· požadavek na konsolidaci dat z různých heterogenních zdrojů (některá data jsou uložena mimo datové servery, je potřeba je na datový server nejprve převést).
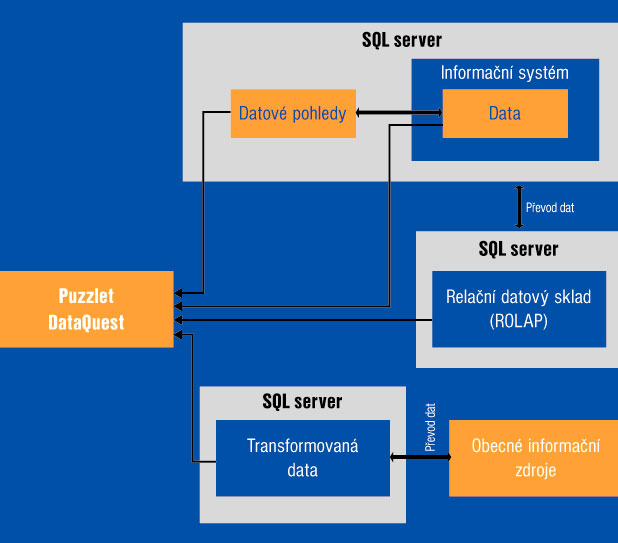
Obr. 1: Schéma spolupráce nástroje Puzzlet DataQuest s datovými zdroji
V každém případě by uživatel neměl být zatěžován znalostí, kde jsou data, se kterými právě pracuje, uložena, měl by však mít k dispozici informaci, jak aktuální jsou. Rozhodování je proces, který do velké míry souvisí s předchozí zkušeností a s porovnáváním současných jevů s jevy minulými. I když jsou nástroje pro podporu rozhodování navrhovány s velkou variabilitou výstupů, uživatel si po čase vytvoří (nebo nechá vytvořit) vlastní skupinu sestav, které používá v rámci svých rozhodovacích procesů. Dokáže tak velmi rychle rozpoznávat odchylky od žádaného stavu či významné hodnoty a následně využít všech možností nástroje k odhalení jejich příčin. Vzhledem k tomu, že to vyžaduje jeho aktivní přístup, je velmi důležitý i výběr prezentačního prostředí. Lze rozlišit tři základní typy:
· Internetový prohlížeč - jeho výhodou je dostupnost bez ohledu na geografické hranice a konkrétní operační systém, je velmi dobře použitelný pro standardizované sestavy a přehledy. Málo vhodný, pokud chce uživatel s daty dále aktivně pracovat.
· Samostatná aplikace - vytváří prostor pro podrobnou analýzu dat, zahrnuje řadu doplňkových funkcí pro jejich zpracování. Uživatel se musí naučit specifické ovládání, aplikace je často závislá na konkrétním operačním systému nebo na databázové platformě.
· Integrace do již existující aplikace (většinou tabulkového procesoru) - umožňuje následnou práci uživatele se získanými daty v prostředí, které dobře zná. Omezením je závislost na dané aplikaci na operačním systému.
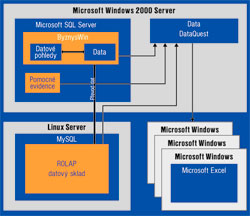
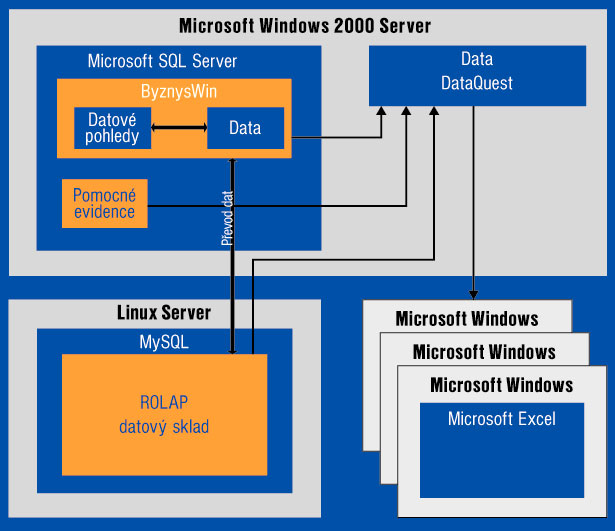
Obr. 2: Schéma uložení dat v Puzzlet DataQuest
V řadě menších, ale i středních organizací se můžeme setkat s následujícím stavem informačního systému:
· jednotlivé agendy jsou vedeny paralelně na několika místech v různých formátech (často je pokryto účetnictví jedním informačním systémem, CRM řešení systémem nekompatibilním atd.)
· využívá se file server technologie, teprve postupně se přechází na technologii klient/server,
· k analýzám a vyhodnocování se převážně využívá Microsoft Excel, data se v lepším případě do tohoto programu importují prostřednictvím externích dotazů, často i ručně,
· s některými daty (např. výstupy z pokladních systémů) se pracuje pouze na provozní úrovni, nevyužívá se veškerý jejich informační potenciál.
U tohoto typu organizací je otázkou, jak zajistit systém pro přehledné reportování s minimálními investičními náklady a s maximálním využitím všech informačních zdrojů takové organizace. Nástroje pro podporu rozhodování dostupné na našem trhu jsou v řadě případů velmi úzce navázány na konkrétní komerční databázovou platformu (pořizovat ji pouze za účelem reportingu by bylo pro tyto organizace neefektivní), některé se navíc soustřeďují pouze na oblast multidimenzionálních kostek, což však neřeší případy, kdy je potřeba výstupy získávat také přímo z provozních dat.
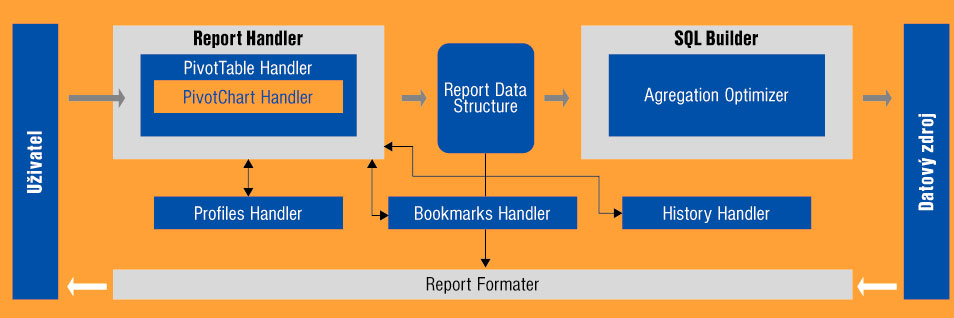
Obr. 3: Architektura nástroje Puzzlet DataQuest
V souladu s výše uvedenými poznatky byly definovány požadavky na reportovací nástroj v následujících bodech:
· umožnit spolupráci s Microsoft Excel (jeho vysoká dostupnost ve většině organizací),
· nezávislost na konkrétní databázové platformě,
· napojení jak na provozní data, tak i na datové sklady,
· možnost vytvářet předpřipravené sestavy,
· sdílení informací v rámci lokální sítě organzace.
Podle těchto požadavků byl vytvořen klientský nástroj Puzzlet DataQuest, který je přímo integrován do Microsoft Excel. Je založen na technologii jazyka SQL, kterou lze realizovat na širokém spektru komerčních i open source databázových systémů. Uživatel v něm pracuje se sešity nazývanými sestavy. Každá sestava obsahuje právě jedna data zobrazená v režimu kontingenční tabulky či grafu. Nástroj umožňuje paralelní práci s řadou takovýchto sestav, kdy každá z nich má autonomní vlastnosti. Konkrétní nastavení sestavy se promítá do jejího interního popisu (Bookmark Definition), který je možno uložit. To ve svém důsledku znamená:
· Puzzlet DataQuest nevyužívá žádný uložený soubor ve formátu Microsoft Excel, plně dokáže nahradit řadu objemných sešitů plných datových tabulek,
· ukládané informace obsahují pouze definice, což jednak minimalizuje jejich objem (řádově několik kB), jednak umožňuje jejich sdílení a distribuci bez rizika narušení bezpečnosti,
· práce se sestavou je monitorována, uživatel se může vracet ke svým předešlým krokům (v rámci každé jednotlivé sestavy nezávisle),
· aktuální podobu sestavy lze v kterýkoliv okamžik uložit ve formě tzv. záložky, která je následně k dispozici prostřednictvím nabídky i pro ostatní uživatele v rámci lokální sítě (pokud k tomu mají příslušná práva).
Vlastní zdroje dat (datové kostky) jsou definovány v rámci struktury Data Source Definition. Ta zahrnuje jednak popis fyzického uložení dat (včetně případů reprezentace dat více fyzickými datovými strukturami s různou úrovní agregace), jednak popis abstraktní vrstvy (popisy faktů, dimenzí a jejich hierarchie). Uživatel je tak "odstíněn" od datového zdroje a pracuje pouze s pojmy, jako je zákazník, čas, tržba apod. Při práci s nástrojem je maximum zátěže při zpracování dotazů ponecháno na datovém serveru, podle aktuálního nastavení sestavy je přenášeno jen nezbytné množství dat. V rámci interaktivní práce se sestavou je důraz kladen na jednoduchost ovládání vycházející ze zvyklostí Microsoft Excel a využívající ve velké míře tlačítek myši v kombinaci s řídicími klávesami. Lze tak jednoduše provádět operace, jako je drill-down/up (rozpad na data o nižší či vyšší úrovni), filtrování, mezisoučty, nastavení řazení apod. Formátovací modul zajišťuje přehledné zobrazení dat, včetně možnosti zvýraznění limitních hodnot. Použití Puzzlet DataQuest je vhodné jak pro méně zkušené uživatele, kteří přistupují pouze k předem připraveným sestavám prostřednictvím nabídky, tak pro uživatele, kteří definují vlastní sestavy výběrem a umístěním dimenzí a faktů, nastavením filtrů a dalších funkcí.
OLAP v praxi
Český národní podnik je společnost nabízející výrobky pod značkou Manufaktura (přírodní dárková kosmetika a bytové doplňky). Její činnost zahrnuje maloobchod (vlastní prodejní síť), velkoobchod a výrobu. V roce 1998 byl instalován maloobchodní informační systém na platformě MS-DOS/FoxPro. Potřeba vyhodnocování maloobchodních výstupů vedla v roce 1999 k realizaci projektu datového skladu na platformě Linux/MySQL. Počátkem roku 2004 došlo k rozhodnutí nahradit stávající informační systém novým, který by lépe odpovídal vzrůstajícím informačním nárokům společnosti. Pro implementaci byl vybrán systém BYZNYSWin společnosti J.K.R. Informační systém je založen na architektuře klient/server a platformě Microsoft SQL Server 2000. Hlavním cílem změny IS bylo integrovat několik dosud oddělených agend, zajistit podporu procesního řízení, řízení styku se zákazníkem a plánování výroby. V rámci implementace byly provedeny úpravy datových struktur IS s cílem posílit hierarchický charakter některých dimenzí. Nad vlastním IS pak byly vytvořeny datové pohledy, které slouží jako datové zdroje pro Puzzlet DataQuest. Do celkového systému byl zapojen koncept datového skladu na platformě Linux - MySQL. Do datovém skladu jsou převedena data z předešlého systému a provedeno plynulé napojení na data systému nového. V systému Puzzlet DataQuest byly následně předpřipraveny skupiny sestav dostupné uživatelům v rámci podnikové sítě.
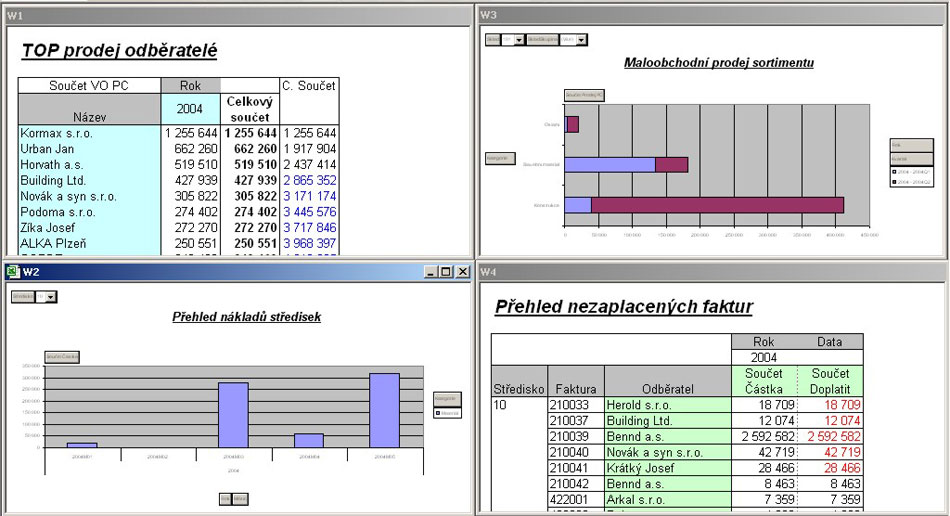
Obr. 4: Schéma nasazení Puzzlet DataQuest ve společnosti Český národní podnik
Příklady realizovaných sestav
· maloobchod: přehledy tržeb členěné dle jednotlivých prodejen a sortimentu, top žebříčky prodejnosti sortimentu, stavy a obrátka zásob
· velkoobchod: přehledy tržeb členěné dle jednotlivých obchodních partnerů a sortimentu, top žebříčky prodejnosti sortimentu dle partnerů, segmentace trhu, hodnocení aktivity jednotlivých obchodních zástupců, přehledy nezaplacených odběratelských faktur, hodnocení hospodářského výsledku jednotlivých zakázek
· výroba: stavy zásob surovin a výrobků, přehledy aktuálních zakázek s požadavky na jednotlivé výrobky, výrobní plán, plán spotřeby a nákupu surovin
· ekonomika: manažerské účetnictví - analýzy nákladů a výnosů, střediskové analýzy
Český národní podnik je společnost nabízející výrobky pod značkou Manufaktura (přírodní dárková kosmetika a bytové doplňky). Její činnost zahrnuje maloobchod (vlastní prodejní síť), velkoobchod a výrobu. V roce 1998 byl instalován maloobchodní informační systém na platformě MS-DOS/FoxPro. Potřeba vyhodnocování maloobchodních výstupů vedla v roce 1999 k realizaci projektu datového skladu na platformě Linux/MySQL. Počátkem roku 2004 došlo k rozhodnutí nahradit stávající informační systém novým, který by lépe odpovídal vzrůstajícím informačním nárokům společnosti. Pro implementaci byl vybrán systém BYZNYSWin společnosti J.K.R. Informační systém je založen na architektuře klient/server a platformě Microsoft SQL Server 2000. Hlavním cílem změny IS bylo integrovat několik dosud oddělených agend, zajistit podporu procesního řízení, řízení styku se zákazníkem a plánování výroby. V rámci implementace byly provedeny úpravy datových struktur IS s cílem posílit hierarchický charakter některých dimenzí. Nad vlastním IS pak byly vytvořeny datové pohledy, které slouží jako datové zdroje pro Puzzlet DataQuest. Do celkového systému byl zapojen koncept datového skladu na platformě Linux - MySQL. Do datovém skladu jsou převedena data z předešlého systému a provedeno plynulé napojení na data systému nového. V systému Puzzlet DataQuest byly následně předpřipraveny skupiny sestav dostupné uživatelům v rámci podnikové sítě.
Obr. 4: Schéma nasazení Puzzlet DataQuest ve společnosti Český národní podnik
Příklady realizovaných sestav
· maloobchod: přehledy tržeb členěné dle jednotlivých prodejen a sortimentu, top žebříčky prodejnosti sortimentu, stavy a obrátka zásob
· velkoobchod: přehledy tržeb členěné dle jednotlivých obchodních partnerů a sortimentu, top žebříčky prodejnosti sortimentu dle partnerů, segmentace trhu, hodnocení aktivity jednotlivých obchodních zástupců, přehledy nezaplacených odběratelských faktur, hodnocení hospodářského výsledku jednotlivých zakázek
· výroba: stavy zásob surovin a výrobků, přehledy aktuálních zakázek s požadavky na jednotlivé výrobky, výrobní plán, plán spotřeby a nákupu surovin
· ekonomika: manažerské účetnictví - analýzy nákladů a výnosů, střediskové analýzy
Autor článku, Ing. Tomáš Kratochvíl, je konzultantem v oblasti firemního řízení a informačních systémů.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce