

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Hlavní partner sekce

Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEMS 4/2018 , AI a Business Intelligence


Úsvit revoluce
Umělá Inteligence a revoluce hlubokého učení
Dr. Robert Šuhada
 V poslední přibližně dekádě proběhla na poli umělé inteligence obrovská revoluce. Po dlouhé roky se nejlepší algoritmy utkávaly každý rok v soutěžích pro stroje v těch nejtěžších úkolech - rozpoznávaní obrázku, videa, přepisu lidského hlasu na text apod. Pokrok v těchto oblastech byl od devadesátých let nepochybný, ale velmi pomalý. I když každým rokem stále víc a víc odborných znalostí a výpočetního času teklo do zdokonalování algoritmů, přesnost predikcí se zvyšovala jen inkrementálně, často jen o zlomky procent.
V poslední přibližně dekádě proběhla na poli umělé inteligence obrovská revoluce. Po dlouhé roky se nejlepší algoritmy utkávaly každý rok v soutěžích pro stroje v těch nejtěžších úkolech - rozpoznávaní obrázku, videa, přepisu lidského hlasu na text apod. Pokrok v těchto oblastech byl od devadesátých let nepochybný, ale velmi pomalý. I když každým rokem stále víc a víc odborných znalostí a výpočetního času teklo do zdokonalování algoritmů, přesnost predikcí se zvyšovala jen inkrementálně, často jen o zlomky procent.
Vše se ale změnilo v roce 2012, když poprvé tzv. hluboké neuronové sítě porazily do té doby vítězné „klasické” algoritmy. Od té doby dominance neuronových sítí jen sílí. Od roku 2015 dokonce porážejí i lidský benchmark v rozpoznávání přirozených obrázků („pes”, „kočka”, „saxofon“ atd. – dlužno ale říct, že jen v kategoriích zahrnutých v soutěži – lidé (zatím!) vedou napříč kategoriemi). Představte si „nadšení” výzkumníků a profesorů, kteří dekády pilovali klasické techniky, jen aby bylo jejich úsilí převálcované úplným algoritmickým nováčkem.
Navzdory tomu, že hluboké učení otřáslo jak akademickým světem, tak mnohými odvětvími průmyslu, je tato oblast pro laickou obec často zahalena tajemstvím a mylnými pověstmi (často především díky agresivnímu marketingu). Dnes si proto projdeme nejčastější otázky, se kterými se v tomto oboru střetáváme.
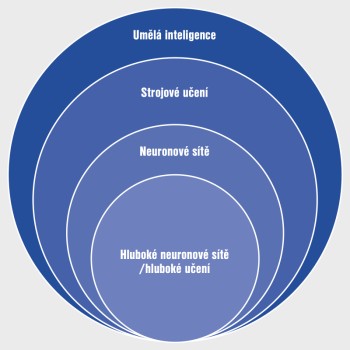
Umělá inteligence, strojové učení, hluboké učení, kdo se v tom má vyznat?
Stejně jako před pár lety „Big Data” otřásalo IT světem, je teď téměř nemožné vyhnout se pojmu „umělá inteligence” (angl. „Artificial Inteligence” – AI). Skutečnost je taková, že AI je nejstarší a taky nejširší pojem. Zahrnuje všechny algoritmy, které se snaží ve vstupních datech hledat nějaké vzory nebo automaticky dělat rozhodnutí. Dá se říct, že když u vás sedí analytik nebo inženýr, který používá lineární regresi (pamatujete ještě ze školy?), tak už používáte techniky „umělé inteligence”.
Dlouhodobě nejúspěšnějším přístupem v AI jsou techniky tzv. strojového učení. Jde o velkou třídu algoritmů, které se učí přímo z dat. To znamená, že namísto toho, abychom „ručně” vkládali rozhodovací kritéria do algoritmu, poskytujeme algoritmu jen vstupní data a algoritmus je sám schopný najít ty nejdůležitější znaky a kritéria (tento proces se nazývá trénováním modelu).
V rámci strojového učení pak máme podskupinu algoritmů - neuronové sítě, což je třída původně biologicky inspirovaných algoritmů, založených na zjednodušeném matematickém modelu fungování neuronů v lidském mozku.
Jednotlivé „neurony“ jsou pak uspořádány ve vrstvách (vstupní, výstupní a alespoň jedna tzv. skrytá vrstva mezi nimi). Uspořádání neuronů a vrstev nazýváme architekturou sítě. Více vrstev, alespoň teoreticky, by přitom mělo umožnit neuronové síti naučit se z dat komplexnější vzorce.
Hluboké učení je nejnovější a nejužší kategorií přístupu k umělé inteligenci, nicméně tyto pojmy se často volně zaměňují – především v marketingovém kontextu. V mnohých oblastech jsou hluboké neuronové sítě skutečně nedosažitelné a také je stále ještě mnoho byznysových oblastí, kde jsou jiné metody stále relevantní, nebo dokonce dominantní. Proto budeme dále používat termín AI (umělá inteligence) v nejširším kontextu a hluboké učení, jen když myslíme konkrétně tuto podskupinu.
Neuronové sítě? Vždyť je to 50 let stará technologie!
Neuronové sítě se objevily na poli umělé inteligence v 60. letech 20. století. I když se původně těšily popularitě, od 90. let bylo jejich využití v praxi často omezené, a to kvůli problému natrénovat sítě hlubší než 1-2 vrstvy, to bránilo jejich aplikaci v komplexnějších problémech. Navzdory tomu několik „skalních” fanoušků – brilantních výzkumníků – v pozadí nadále pokračovalo na jejich zdokonalování, až do překvapivého převratu v letech 2010 – 2012.
Proč právě teď?
Revoluce hlubokého učení spočívala v průlomu v trénování hlubších architektur – 8 vrstev pro rozpoznávání obrázku v roce 2012, až po stovky vrstev v současnosti. Více vrstev znamená více parametrů, a právě díky nim je neuronová síť schopna naučit se komplexní vzory v datech.
Průlom v možnosti trénovat hluboké sítě umožnila souhra několika faktorů:
- Dostupnost ohromné výpočetní sily díky rychlejšímu počítačovému hardwaru.
- Přístup k obrovskému množství dat, která jsou často nutná (ale ne vždy! Viz níže.) pro trénování hlubokých sítí.
- Kombinace mnohých inovací v teoretickém popisu sítí, jejich komponent a architektur (např. renormalizace, konvoluční sítě, residuální vrstvy atd.).
- Nové, vysoce výkonné a robustní metody optimalizace sítí.
Je tedy zajímavé, že revoluci nevyvolal čistý teoretický pokrok, ale do velké míry je za ním právě narůst „hrubé síly” výpočetního hardwaru a velkých dat nebo dnes přesnějšího pojetí „Just Data“.
Co tedy AI a hluboké učení konkrétně umí?
Hlavní domény, kde hluboké učení v současnosti vyniká, jsou:
- Rozpoznávaní obrázku a videa: automatizované „taggování” obrázku ve službách Google/Facebook, rozpoznávání produktů a dílů na výrobních linkách, vizuální kontrola kvality produktů nebo infrastruktury (např. elektrické sítě), rozeznávání tváří, postav. Rozpoznávání ručně psaných dokumentů. Rozpoznávaní videa v autonomních automobilech bez řidiče.
- Rozpoznávání zvuku – rozpoznávání hlasových příkazů (Google asistent, Apple Siri, Amazon Alexa). Detekce poruch strojů pomocí analýzy zvuku apod.
- Analýza textu – sémantické vyhledávání (např. Google vyhledávání, tj. založené na významu textu, ne konkrétních, explicitně uvedených termínů) a klasifikace textu.
- Predikce časových řad a jiných sekvencí – např. senzorická data ze zařízení internetu věcí. Burzová data.
- Uplatnění v robotice a automatizaci – kombinace neuronových sítí na ovládání autonomních automobilů od Google má najeto 570 000 km s 63 intervencemi od lidského řidiče. Je to tedy jedna intervence na 9000 km (stav z r. 2016). Samozřejmě se hluboké učení používá také ve více regulovatelných podmínkách – např. robotika v továrnách.
Algoritmy AI v globálním kontextu se pak používají prakticky v každém oboru – telekomunikace, energetika, výrobní průmysl, online byznys a retail, bankovnictví, finance a tak dále. Jen stěží lze najít nedotčenou oblast.

Podniková AI strategie?
Trendy předpovídají v následujících letech exponenciální narůst trhu pro AI: od přibližně 3-4 miliard USD v roce 2018 až po téměř 60 miliard USD v roce 2025 [1]. Mnohé společnosti se tedy snaží co nejdříve vypracovat koherentní strategii, jak podchytit tento významný trend ve svých firmách.
Podle průzkumu Forbes [2] považuje 83 % respondentů AI za strategickou prioritu. Od technologie očekávají nejen možné úspory ze zefektivnění a automatizace operací, ale především v ní spatřují zdroj konkurenční výhody a klíč k novým trhům a obchodním příležitostem.
S velkým potenciálem ale přichází velká zodpovědnost. V sektoru bezesporu vládne obrovské nadšení, což od výkonných vedoucích a opinion makerů vyžaduje důkladné nahlédnutí skrz prázdné slogany. Prvním krokem je zajisté edukace (což je nakonec taky hlavní motivací tohoto článku). Nevyžaduje si to nutně chápání technologie na té nejhlubší, matematické úrovni, ale jistá dávka technické zvědavosti určitě neuškodí.
Při tvorbě AI strategie a výběru prvních projektů se často setkáváme s podobnými úskalími. V následujících odstavcích si je proto projdeme.
Co jsou tedy hlavní úskalí AI projektů?
Hlavní bariéry vidíme ve dvou faktorech:
- Přístup ke zdrojům potřebným k AI projektu
- Výběr vhodného projektu.
Zajímavostí je, jak k jednotlivým faktorům přistupují firmy. Průkopnické firmy považují za největší úskalí zdroje, kdežto „skeptické” firmy se drží dál, kvůli nedostatku nebo nedůvěře, že by našly vhodný projekt, do kterého by AI zapadla.
Jaké zdroje potřebuji pro AI projekty?
Data
Data jsou jednoznačně hlavním zdrojem konkurenční výhody. Často platí, že máte více dat a potřebujete jich méně, než si myslíte – alespoň pro začátek. V hlubokém učení skutečně preferujeme větší množství dat pro trénování, ale díky novým technikám (především tzv. transfer learning) je možné začít už s několika stovkami vzorků (např. obrázků), samozřejmě v závislosti na druhu úlohy. „Big Data” tedy určitě není nutné!
Software a hardware
Software, především programové knihovny a frameworky pro AI a hluboké učení. Zde máme štěstí – AI komunity jsou silnými zastánci open source, a proto i ty nejmodernější algoritmy jsou dostupné zadarmo. V oblasti hlubokého učení jsou ty nejdůležitější Tensorflow od Googlu, pytorch od Facebooku a MXNet od Amazonu / Apache. Když vám tedy někdo nabízí komerční, proprietární řešení pro AI, určitě bych se zeptal na benchmarky vůči open source řešením. Až na extrémně doménově specifické aplikace je proprietární software často zbytečný.
Na straně hardwaru je pro trénování často výhodné použít grafické karty (GPU – graphic processing unit), které se používají pro moderní počítačové hry (a těžbu kryptoměn…). Cloudoví provideři už poskytuji také pronajímatelný GPU cluster, ceny jsou ale zatím dost vysoké.
Lidské zdroje – AI experti
To nejdůležitější na konec. Aplikací technik AI na byznysové problémy se zabývají datoví vědci a inženýři pro strojové učení. V závislosti na typu byznysu a celkové analytické „zralosti” podniku si mnohé firmy pořídí interní skupinu pro AI nebo se spolehnou na projektovou podporu konzultační firmy. Při založení interní skupiny ale musíme myslet na to, že datový vědec je zřídka efektivní ve „vakuu” – potřebuje podporu a integraci s jinými odděleními a systémy (především pak od pozic jako datový administrátor, big data inženýr apod. a cílových projektových/produktových manažerů). Všeobecně ale platí, že přístup k talentům v této oblasti je v současnosti extrémně těžký a znamená často pro firmy největší úskalí. „Plug-and-play” analytika a automatizovaná AI propagovaná některými firmami je stále ještě v extrémně raných fázích a vyžaduje si hlubší znalosti statistiky a strojového učení, pokud si chceme být jistí, že jsou naše predikce skutečně spolehlivé a robustní.
Jak rozeznat dobré aplikace pro aplikaci umělé inteligence?
Vraťme se k druhému nejčastějšímu úskalí AI strategie: jak identifikovat projekty s vysokým potenciálem.
Zlatá zóna AI projektu je samozřejmě v průsečíku, kde je potenciální byznysová hodnota nejvyšší a kde jsou zdroje (zejména data) dostupné. V mnohých firmách je to zejména oblast automatizace procesů – kde lidští operátoři vykonávají opakující se činnost, která je ale flexibilnější, než co dokážeme automatizovat běžnými algoritmy.
Andrew Ng, bývalý šéf AI v Google a Baidu, má následující jednoduché pravidlo: „Pokud je lidský operátor schopný učinit rozhodnutí za přibližně jednu vteřinu bez hlubšího přemýšlení, jde tuto činnost s velkou pravděpodobností automatizovat pomocí AI.”
Jde například o vizuální kontrolu kvality produktu: ne všechny procesy bylo dosud možné automatizovat. Defekty jsou často variabilní (tvar, poloha, barva…). Člověk je často schopný odhalit je na první pohled, pro klasický algoritmus strojového vidění jsou ale mnohé z těchto úloh neřešitelné. Hluboké učení v těchto doménách však udělalo obrovský pokrok.
Jako v případě jakékoliv heuristiky je platnost této rady omezená. Těžko se proto zobecňuje a nejlepší je obrátit se na radu expertů už v počátečních fázích projektu.
Kam dále?
V prosinci 2017 tým DeepMind (start-up, za kterým stojí Google) oznámil, že se jejich poslední verze hluboké neuronové sítě Alpha Zero naučila hrát šachy, shogi („čínské šachy”) a go (extrémně náročná strategická desková hra) na lepší úrovni než ti nejlepší lidští hráči. Je překvapivé, že 1) to zvládla za 24 hodin, 2) pravidla hry a povolené tahy do ní nebyly naprogramovány a 3) nebyly jí poskytnuty ani žádné příklady ze zápasů lidských hráčů. Vše se naučila úplně sama (proto „Zero” – začínala úplně od nuly) a v průběhu 24 hodin překonala dekády tréninku největších mistrů, a hlavně znalosti celé lidské rasy (go se hraje pres 2500 let!).
Myslím, že není pochyb, že umělá inteligence (včetně hlubokého učení a přístupů, které ji dále zdokonalují), bude výrazně formovat naši budoucnost: jak v průmyslu, tak v tom nejširším společenském kontextu.
Zatím je to ale nás, na našem intelektu a charakteru, abychom připravili tuto budoucnost v souladu s našimi hodnotami a cíli.
 |
Dr. Robert Šuhada Autor článku vede Data Science tým ve společnosti Foxconn 4Tech se zaměřením na hluboké učení v průmyslových aplikacích. Vystudoval astrofyziku na Max-Planck Institutu pro Extraterestriální Fyziku, Mnichov, Německo, kde pracoval na analýze snímků z Rentgenových satelitů. Několik let se věnoval aplikacím strojového učení v energetice (konvenční a obnovitelné zdroje) a v e-komerci a pojišťovnictví. |
Zdroje:
[1] https://www.statista.com/statistics/607716/worldwide-artificial-intelligence-market-revenues/
[2] https://www.forbes.com/sites/louiscolumbus/2017/09/10/how-artificial-intelligence-is-revolutionizing-business-in-2017/#35116f545463
[3] https://arxiv.org/abs/1712.01815
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce