

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Hlavní partner sekce

Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEMS 9/2010 , AI a Business Intelligence



Obr 1: Příklad architektury řešení DQ Scorecards

Obr 2: Vztah metrik DQ a výsledků business procesů
Proč a jak sledovat datovou kvalitu
 O data governance se obvykle píše jako o jakémsi všeobjímajícím, trochu mlhavém konceptu. Složité definice a pojednání nesoucí se spíše ve vzletně filozofickém duchu často nabízejí spoustu moudrých rad, jako že jde o program, který se „musí rozvíjet koncepčně“ a „má odrážet business potřeby“ apod. Že se detailně zabývá organizačními strukturami, zavádí nové pracovní role, doporučuje vytvářet akční plány… Ale když už se natěšený a trochu netrpělivý čtenář domnívá, že „teď to konečně přijde“, že teď už se doví, jak to konkrétně dělat a jak vypadají skutečné výstupy těchto aktivit, traktát se najednou dobere konce a je završen obecnými zvoláními zhruba ve smyslu „že o bohatství uložené v podnikových datech je třeba se skutečně dobře starat“.
O data governance se obvykle píše jako o jakémsi všeobjímajícím, trochu mlhavém konceptu. Složité definice a pojednání nesoucí se spíše ve vzletně filozofickém duchu často nabízejí spoustu moudrých rad, jako že jde o program, který se „musí rozvíjet koncepčně“ a „má odrážet business potřeby“ apod. Že se detailně zabývá organizačními strukturami, zavádí nové pracovní role, doporučuje vytvářet akční plány… Ale když už se natěšený a trochu netrpělivý čtenář domnívá, že „teď to konečně přijde“, že teď už se doví, jak to konkrétně dělat a jak vypadají skutečné výstupy těchto aktivit, traktát se najednou dobere konce a je završen obecnými zvoláními zhruba ve smyslu „že o bohatství uložené v podnikových datech je třeba se skutečně dobře starat“.
Zkusme se tedy na chvíli trochu vzdálit od těchto obecných, byť jistě velkolepých a správných idejí, ponořit se o několik úrovní níže a podívat se, jak může vypadat jedno z možných řešení podporující aktivity v této oblasti. Vezměme to však po pořádku.
Vše stojí na vztazích
Na těch už zmíněných dobrých radách samozřejmě něco je, ostatně jako na každém šprochu. Když se je pokusíme „zhmotnit“ a dát jim konkrétní podobu, může nám vyjít, že jedním z úkolů data governance je zajistit, aby stav dat nepoškozoval výsledky našeho konání (tedy „podnikového businessu“), ba naopak přispíval k jejich zlepšení. Zkusme teď toto sdělení dále dešifrovat:
Předně zde hovoříme o „stavu dat“. Na data se můžeme v tomto kontextu dívat jako na materiál, ze kterého vyrábíme informaci a tu pak použijeme třeba tak, že na jejím základě něco uděláme, neuděláme nebo uděláme jinak… Stejně jako u jakéhokoliv jiného produktu je i zde kvalita konečného „výrobku“ závislá na jakosti vstupního materiálu. V našem případě tedy stav dat znamená především jejich kvalitu. Její údržba a řízení je předmětem samostatného oboru s dnes již propracovanými postupy, standardy a nástroji. Mezi ně patří i metody umožňující stav dat měřit a získaná měření formalizovat.
Pak jsou zde „výsledky našeho konání“ čili podnikového businessu. Toto „konání“ ve skutečnosti znamená konkrétní činnosti a aktivity, do nichž vstupuje materiál (data a informace) a naše úsilí a které skončí vždy nějakým výsledkem (dopadnou dobře, špatně, nebo něco mezi tím). Říká se jim procesy (též podnikové či business procesy) a ty jsou mimo jiné charakterizovány tím, že jejich výsledky lze rovněž měřit.
A do třetice se zde hovoří o „nepoškozování, a naopak přispívání ke zlepšení“, tedy jednoduše ovlivňování jednoho druhým, tedy o nalezení vztahu mezi obojím. Zní to jednoduše, ale ve skutečnosti zde je zakopáno čertovo kopyto, jak se praví v literatuře. Ono totiž není vůbec jednoduché tenhle vztah najít, popsat, formalizovat, z mnoha možných vlivů vybrat ty, které jsou podstatné pro požadovaný výsledek, a navíc vše zasadit do kontextu ostatních procesů a dat a pak to celé prezentovat tak, aby se v tom bylo možné vyznat, a dokonce to třeba i smysluplně použít.
Takže když se na to podíváme z opačného konce, hodilo by se mít k dispozici nástroj či řešení, které by nám umožňovalo monitorovat popsaný vztah, abychom mohli v datech odhalit a zachytit jevy ovlivňující náš business, a to tehdy, když ještě není pozdě – tedy jakýsi systém včasného varování. Příkladem takového nástroje je skórkarta datové kvality (data quality scorecard), kterou se teď pokusíme představit.
Skórkarta datové kvality
Skórkarty představují vcelku známý a obecně přijímaný koncept, který poskytuje „skóre“ pro určité vybrané (důležité) veličiny a srozumitelně, a hlavně konzistentně je prezentuje lidem, kteří jsou nadáni pravomocí na jejich základě rozhodovat. V podstatě jde o mechanismus umožňující vyrobit koncentrovanou, ale přitom výstižnou a dobře srozumitelnou informaci. Přitom původ té informace nebývá nikterak jednoduchý a přímočarý, většinou vychází z mnoha různorodých a různě dostupných zdrojů.
Podobně je tomu i u skórkaret datové kvality. Ve zde prezentovaném pojetí představují systém signalizující přehledným způsobem dopady kvality (či nekvality) dat na výsledky business procesů, které s nimi pracují. A nejen signalizující. Jsou na různé úrovni napojeny přímo na procesní a řídící workflow, takže umožňují na základě indikovaných jevů automaticky iniciovat odpovídající akce.
Jak DQ skórkarty fungují
Dle očekávání jsou na vstupu změřené ukazatele datové kvality (DQ metriky získané automatizovaně speciálním softwarovým nástrojem). Tyto ukazatele jsou seskupeny a agregovány a jsou vypočítány souhrnné metriky, které už indikují, jak se věci mají. Konkrétně se rozsvítí symbolická červená, respektive zelená či oranžová žárovička, jestliže příslušná hodnota překročí určený limit, nebo se k němu – v oranžovém případě – přiblíží. A v určených případech je zavolána služba, spuštěn proces, odeslán e-mail nebo SMS s upozorněním, požadavkem či varováním… Ano, to je ono, to přesně chceme. Je s tím však spojeno hned několik potíží.
Kde jsou zakopáni skórkartoví psi
Předně: je zde otázka, jak nastavit zmíněné limity, určující, kdy je ještě úroveň datové kvality únosná bez následků pro business, a kdy už nekvalita přerůstá tolerovatelnou mez. Stanovení této úrovně je obtížné i proto, že musí mimo jiné vycházet z podobných ukazatelů pro kvalitu výstupů samotných business procesů (například procento zmetků, response rate, doba vyřízení zakázky atd.).
V praxi se to většinou dělá tak, že se vezmou naměřené metriky, transformují se do procentuální škály a provede se „expertní odhad“ – tedy někdo (důvěryhodný, moudrý, respektovaný) řekne, že do 85 procent to je v pořádku (zelená), při poklesu na úroveň mezi 75 a 85 procent vyšleme varování (oranžová) a pod 75 procent nastává kritický stav a spouští se alarm (červená). Ten dotyčný musí být skutečně moudrá a nezpochybnitelná autorita, aby náhodou nějakého šťourala nenapadlo se v tom vrtat. Fakticky to ovšem znamená, že jsou tyto limity nastaveny v podstatě náhodně a není jasné, jaký je jejich skutečný vztah k výsledkům business procesů. Inu, nemůžeme se na onu autoritu zlobit, ono to ve skutečnosti ani moc nejde jinak udělat, jestliže jsou příslušné ukazatele konstruovány stejně náhodným způsobem, jak je naznačeno dále.
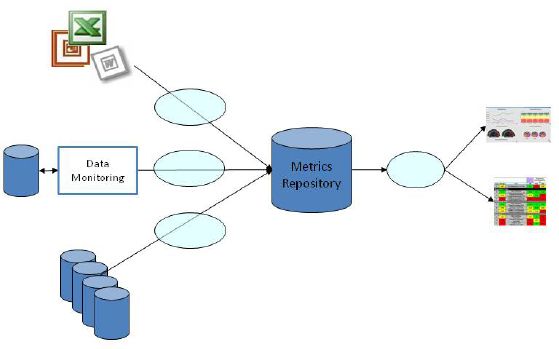
Obr 1: Příklad architektury řešení DQ Scorecards
Za druhé: velmi důležité a přitom nesnadné je najít a vybrat ty ukazatele datové kvality, které mají význam pro výsledek procesu. Říká se jim relevantní metriky. Velmi často se to dělá metodou nejmenšího odporu (dokonce jest možno tento přístup spatřit i v odborných pracích na toto téma). Logickým základem je známá poučka, jejímž autorem je slavný fyzik William Thomson, též známý jako lord Kelvin: „Když něco nemůžete měřit, nemůžete to zlepšit.“ Toto tvrzení je ovšem tvořivě uchopeno a převedeno (nesprávně) do podoby „co můžeme měřit, můžeme zlepšit“ a následně pragmaticky rozvedeno jako „co se změří, může se reportovat“… Výsledkem je snaha měřit kde co, hlavně když se to dá snadno provést, a hned máme k dispozici stovky a tisíce ukazatelů a následně tabulek, reportů a grafů a to by v tom byl čert, abychom z nich něco nevytěžili. Ve skutečnosti je u většiny takto získaných hodnot přinejmenším sporné, zda a jaký vůbec mají vztah ke konkrétnímu businessu. Samozřejmě, pokud je máme převést do přehledných skórkaret, musíme je agregovat, což tento vztah ještě více znetransparentní. A i v samotném způsobu agregace spočívá další potíž.
Tedy za třetí: protože je v každém případě potřeba z mnoha ukazatelů vytvořit jeden, nebo jenom několik, je vždy nutno provést nějaký typ agregace. A tato agregační funkce je fakticky oním mechanismem, který formalizovaně popisuje vztah mezi datovou kvalitou a výsledky business procesů. Zde, vzhledem k tomu, že součástí maturitních zkoušek není povinná matematika, nastává další potíž. Představy o agregování naměřených hodnot většinou končí u (v lepším případě váženého) průměru. Realita je však mnohem pestřejší – ve skutečnosti mohou dílčí ukazatele datové kvality ovlivňovat procesy různou měrou za různých okolností (například při malé četnosti konkrétního defektu bude jeho relativní vliv menší než při velké četnosti), jejich dílčí složky mohou mít prohibitivní charakter (důležitější mohou být například minimální hodnoty daného ukazatele naměřené ve všech systémech než jejich vážený průměr), nebo mohou být některé extrémní hodnoty vyřazeny, nebo naopak pouze ony zařazeny atd. Jinak řečeno, agregace není banální záležitostí a může nabývat mnoha podob lišících se pro jednotlivé složky vstupující do výpočtu… Co s tím?
Výběr relevantních metrik
Jak je zřejmé z výše popsaného, základem je výběr správných metrik datové kvality.
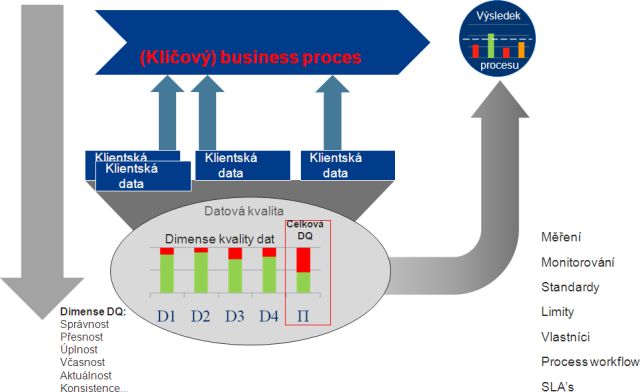
Obr 2: Vztah metrik DQ a výsledků business procesů
Říká se jim také relevantní metriky. Jak je poznáme? Existuje samozřejmě celá řada přístupů a metodik, pro náš účel vycházíme z pěti charakteristik, které by měla dobrá (tj. relevantní) metrika splňovat:
- Business relevance. To je skutečný základ. Jde o definici metrik datové kvality v business kontextu. Jinak řečeno, filtrování ukazatelů podle toho, jak měřené hodnoty korelují se zlepšením konkrétního procesu. Znamená to, že se začíná výběrem důležitých procesů, diskusí o tom, jak se pozná, že daný proces dopadl hůře nebo lépe, případně že vůbec nedopadl, a teprve po formalizování tohoto výsledku zkoumáme, které metriky datové kvality jej dokážou ovlivnit.
- Měřitelnost. Jde o to, aby existoval proces kvantifikace daného měření. Pokud bychom například sledovali estetickou hodnou vytištěných záznamů (Proč ne? Určitě to může něco ovlivnit…), tak by se nám s výsledkem měření špatně pracovalo, kdyby jeho hodnoty byly „Hezké“, „Uspokojivé“, „Dobře uspořádané“, „Hezké, ale neuspořádané“, „Nevhodný font“, „Výborné“. Zkrátka, musí existovat postup, metodika, proces převádějící výsledky měření na čísla.
- Řiditelnost. Smysl má zabývat se ukazateli těch jevů, které můžeme ovlivnit. Tedy takových, u kterých jsme schopni při zjištění hodnot mimo požadovaný rozsah provést akci či opatření, jež povede ke změně tohoto ukazatele, tedy „že se vrátí do latě“. Například by bylo málo platné zjistit, že nám kvalita dat kolísá v závislosti na rotaci zeměkoule; s tou zkrátka nehneme.
- Reportovatelnost. Každý ukazatel, má-li být použitelný, musí odpovídat úrovní detailu svému adresátovi. Tedy – daná metrika musí umožňovat rozpad podle procesů, zodpovědností, oblastí, systémů tak, aby „do ní viděli“ ti, kteří za data pro danou oblast zodpovídají (může se jim říkat třeba datoví stewardi).
- „Stopovatelnost“. Všechno tohle děláme pro to, abychom „zlepšili náš business“. Tedy abychom provedli nápravná opatření a zásahy a nastavili pravidla a podobně. A to vše něco stojí. Takže je nanejvýš potřeba, abychom měli data o tom, jaký je výsledek a účinnost nápravných akcí a jaká je jejich náročnost, což znamená, že dané metriky potřebujeme sledovat v časových řadách.
Agregační funkce
Jak už bylo naznačeno výše, agregační funkce je oním požadovaným formálním vyjádřením vztahu mezi úrovní datové kvality a business procesů. Její složitost je dána především tím, že procesů, jež jsou ovlivňovány, je mnoho a ještě výsledek každého z nich může mít různé dopady (např. na produktivitu, finance, riziko, image společnosti, …). Kromě toho je zde spousta ukazatelů datové kvality představujících různé faktory v působení na business procesy. A ještě nás zajímá, jak se to projevuje v členění podle organizačních jednotek, business streamů, typů činností, úrovně řízení a podobně. Dá se říci, že nás zajímají vztahy mezi daty a procesy nahlíženy dle (mnoha) různých dimenzí. A pro každou z těchto dimenzí může být agregační formule odlišná (někde průměr, jinde maximum a onde zase třeba speciální funkce transformující metriku do binární podoby). Zkonstruovat tedy takovou funkci, která by pracovala nad celým modelem, zohlednila popsanou různorodost a přitom dávala za všech okolností konzistentní výsledky, není žádná legrace. A podařit se nám to může pouze tehdy, máme-li k dispozici relevantní metriky. A odpovídající matematický aparát.
Nastavení limitů
A teprve teď se můžeme bavit o nastavení limitů. Tedy žádný prošedivělý (nebo charizmatický) guru, jemuž si nikdo nedovolí nevěřit, ale dojednaný, s businessem odsouhlasený, a hlavně formálně akceptovaný a schválený standard, který je součástí komplexnějších pravidel pro řízení datové kvality (říká se tomu data quality service level agreements – DQ SLA, nebo zkrátka DQA). A tohle si můžeme domluvit tehdy, když už se bavíme o relevantních metrikách a máme jasno, jak je budeme sledovat (tedy agregovat).
Jak vypadá technické řešení
Když se tak na to teď podíváme, vypadá to, že realizace vlastního technického řešení bude ve srovnání s návrhem jeho business logiky hračka. Inu, je tomu tak i není.
Na jedné straně takto pojato umožňuje využít známých konceptů a nástrojů (například profilig, multidimenzionální analýzy a reporting). To celou věc usnadní. Na druhé straně je třeba si uvědomit, že aby řešení jako celek sloužilo skutečně jako automatizovaná podpora data governance, mělo by obsahovat i další komponenty a musí být zasazeno do celkové datové a aplikační architektury včetně takových podsystémů, jako je specializovaný nástroj pro řízení datové kvality, napojení na procesní workflow systém, integrační a aplikační platformy a podobně. A ještě k tomu budou některé komponenty použity „nestandardním“ způsobem (vzpomeňme na výše přetřásanou agregační funkci).
Vcelku tedy i realizace představuje intelektuální výzvu a může se hodit, že i v tomto směru jsou už některé cestičky prošlapány. Když se to však podaří, můžeme se těšit z řešení, které je postaveno koncepčním způsobem a může být platné pro reálné zlepšení businessu. Takže – půjdeme do toho?
Autor působí jako business intelligence advisor ve společnosti SAS.
Vladimír Kyjonka
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce