

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Hlavní partner sekce

Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

Business Intelligence , AI a Business Intelligence
 V dnešním konkurenčním prostředí
a díky nasycenému trhu přicházejí
nově získaní zákazníci převážně
od konkurence, a proto je udržení
stávajících zákazníků důležitým
měřítkem úspěchu a konkurenční
výhodou. Odchod stávajících
zákazníků přináší jak snížení
zisků, tak ztrátu pozice na trhu
a zároveň narůstající náklady na
získání nových klientů. Udržení
zákazníků řeší tzv. churn management,
který identifikuje mezi
zákazníky hlavní kandidáty na
odchod, zjišťuje příčiny jejich
chování, realizuje vhodnou
retenční kampaň k jejich udržení
a měří dosažené výsledky.
V dnešním konkurenčním prostředí
a díky nasycenému trhu přicházejí
nově získaní zákazníci převážně
od konkurence, a proto je udržení
stávajících zákazníků důležitým
měřítkem úspěchu a konkurenční
výhodou. Odchod stávajících
zákazníků přináší jak snížení
zisků, tak ztrátu pozice na trhu
a zároveň narůstající náklady na
získání nových klientů. Udržení
zákazníků řeší tzv. churn management,
který identifikuje mezi
zákazníky hlavní kandidáty na
odchod, zjišťuje příčiny jejich
chování, realizuje vhodnou
retenční kampaň k jejich udržení
a měří dosažené výsledky.


Identifikaci zákazníků z hlediska jejich odchodu a zjištění příčin jejich odchodů nalézají metody data miningu. Výstupem procesů data miningu jsou modely, které aplikují vhodný algoritmus na historická data. Dalším zajímavým výstupem je z dat získaná znalost, která umožňuje systémovou změnu. Rychlý rozvoj datových skladů v kombinaci s výkonnou výpočetní technikou napomáhá vytvářet kvalitní predikční modely v rychlých časových cyklech. Celý projekt typicky trvá několik málo měsíců.
Data mining se definuje jako netriviální dobývání skrytých, předem neznámých a potenciálně užitečných informací z dat. Využívají se metody umělé inteligence (strojového učení) a statistiky. Velký rozvoj data miningu v akademickém světě začal v 70. a 80. letech minulého století a od konce 90. let se čím dál více jeho metody nasazují v praxi. Při realizaci se často postupuje podle metodologie CRISP-DM (CRoss Industry Standard Process for Data Mining). Celý proces se definuje jako průchod šesti fázemi s tím, že velký důraz se klade na iterativnost celého procesu. Právě možnost vrátit se v případě potřeby k jednotlivým předchozím fázím dává procesu velkou flexibilitu a možnosti optimalizace. Tento článek ukazuje životní cyklus řešení prevence odchodu zákazníků podle metodologie CRISP-DM.
Predikce odchodu zákazníků je úkol, který je netriviální díky velkému množství dat a obtížnosti najít predikční model s vhodným obchodním přínosem. Odchod zákazníka zpravidla nebývá způsoben jedním důvodem (ani po měsíci mi nebyla zavedena služba), ale je obvykle způsoben kombinací několika důvodů (již nepotřebuji danou službu, přecházím na jinou, nejsem spokojen s komunikací, nabídka lepších cen). Další komplikací je, že každý odchod je jedinečný a zákazník při odchodu nesděluje důvod, proč odchází. Existuje pouze záznam o tom, že v daném čase odešel.
Poskytovatelé telekomunikačních služeb, tradiční pevné linky a mobilní operátoři, čelí úbytku zákazníků. Lidé buď odcházejí od pevných linek k mobilním operátorům, nebo přecházejí mezi jednotlivými mobilními operátory. Celosvětově ztrácí každý mobilní operátor v průměru měsíčně 2 % svých zákazníků. Ročně to může být i 25 %. Skoro polovina zákazníků internetových poskytovatelů také ročně odchází ke konkurenci. V bankovnictví odchází ročně mezi 10 % a 15 % zákazníků. Výzkumy ukazují, že udržení stávajících zákazníků je ekonomicky výhodnější (zhruba pět- až sedmkrát) než získávání nových. Hlavním důvodem je také fakt, že noví zákazníci nevyužívají tolik služeb v porovnání se stávajícími zákazníky.
Všechny společnosti v poslední době nabízejí kombinace více služeb prostřednictvím tzv. balíčků. Udržet zákazníka znamená nabídnout mu stejné, či pokud možno lepší podmínky a služby, které typicky využívá či využívat může. Možné cíle analýzy představují odpovědi na otázky jako:
Prvním důležitým krokem je definovat, co je odchod zákazníka, případně definovat fáze odchodu v čase. Doplňujícím identifikátorem je stanovení hodnoty zákazníka. Největší prioritu má identifikace zákazníků, kteří přinášejí užíváním svých služeb zisk, případně jinou hodnotu (např. prestiž, perspektivu růstu užívání služeb apod.). Identifikace hodnoty zákazníka se využívá při následném výběru a cílení kampaní.
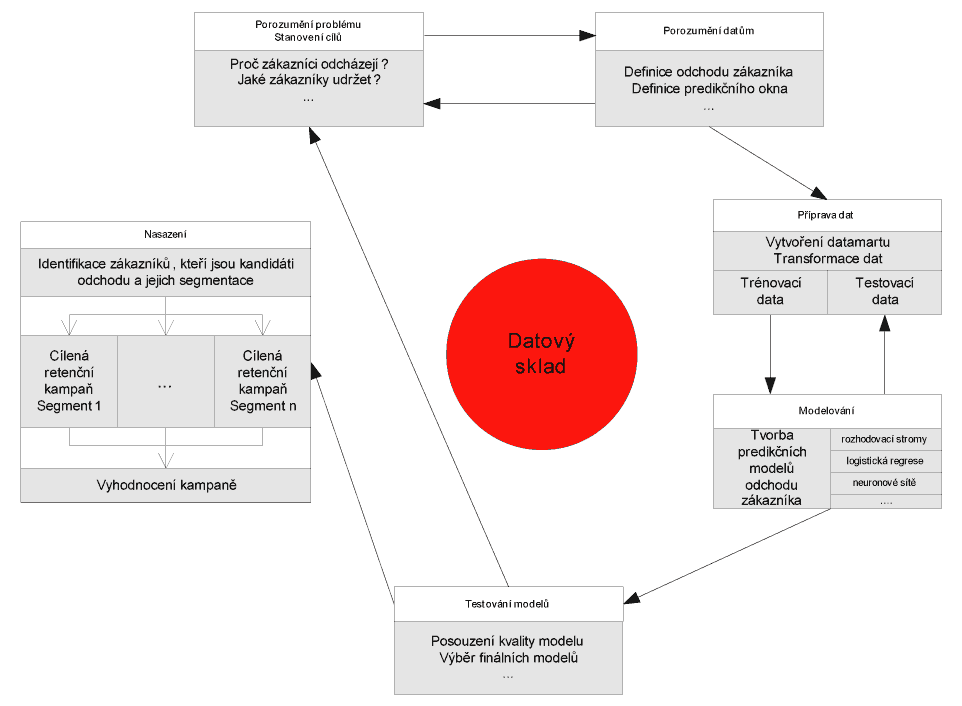
Obr. 1: Nasazení CRISP-DM metodologie na prevenci odchodu zákazníků
Hlavním úkolem přípravy dat je vytvořit datamart. Datamart je datová matice, jejíchž řádky tvoří záznamy jednotlivých zákazníků. Sloupce popisující zákazníky pomocí atributů, které jsou vhodné pro vytváření modelů demografická data, behaviorální data, informace o odchodu, hodnota zákazníka a další). Atributy jsou buď přímo součástí datových skladů nebo se z nich odvozují pomocí vhodných transformací (čištění dat, diskretizace, normalizace, kombinace atributů, nelineární transformace apod.). Volba transformace je výsledkem analýzy a praktických zkušeností. Dalším faktorem je výběr dat z hlediska jejich stáří. Je třeba vybrat taková historická data, která mají relevantní význam. Má smysl použít dva roky stará data, když v tomto období nebyla dostupná daná služba? Mají tato data o odchodu odpovídající vypovídací hodnotu? V bankovnictví lze použít i starší data v porovnání s telekomunikačním trhem, který je daleko více dynamický.
Důležité je také správně definovat predikční mezeru, která definuje „zpoždění“ použití predikčního modelu. Zpravidla platí, že před odchodem zákazníci přestávají užívat určité služby, a to už většinou bývá pozdě na vhodnou kampaň. Predikční model založený na takové informaci pak nic užitečného nepřináší. Zákazník, který odejde a v posledních dvou měsících nevyužíval služeb, byl o odchodu patrně rozhodnut již před více než dvěma měsíci. Právě ve starších datech je třeba hledat důvody jeho odchodu, nevyužívání služeb v posledních dvou měsících je jen důsledek něčeho jiného, ne příčina jeho odchodu. Dalším důvodem tvorby predikční mezery je agregace dat, která se dokončuje po uplynutí daného období. Agregovaná data se aplikují na predikční model, identifikují se potenciálně odcházející zákazníci a následně lze spustit retenční kampaň. Obecně platí, že příliš dlouhá predikční mezera snižuje kvalitu modelu, a příliš krátká nerespektuje vhodně daný problém či neumožňuje včasně reagovat na získané informace. Zvolení optimální predikční mezery je tedy záležitostí správné obchodní úvahy a zkušenosti.
Jako klasifikační algoritmy se nejčastěji používají rozhodovací stromy, logistická regrese, neuronové sítě, metoda podpůrných vektorů, případové uvažování a další. Hlavní výhodou algoritmů jako jsou rozhodovací stromy, logistická regrese a částečně i případového uvažování je snadná interpretace jejich výsledků. Je možné sledovat jak jednotlivé vstupy s danou hodnotou přispívají k celkovému výsledku. Z rozhodovacích stromů pak lze přímo generovat pravidla. To přispívá k důvěryhodnosti těchto metod a jejich obecné oblibě. Na druhou stranu neuronové sítě, metoda podpůrných vektorů a další mívají v některých případech lepší vlastnosti. Jejich nevýhodou je však komplikovanost modelu, který po přivedení vstupů dodá výstup s tím, že nelze lehce interpretovat, co se děje uvnitř.
Po identifikaci zákazníků, kteří mají velkou pravděpodobnost odchodu, je vhodné následně provést jejich segmentaci. Segmentace rozdělí vybrané zákazníky do skupin, které jsou charakteristické určitým druhem chování (např. hodnota zákazníka, využívající danou službu, více služeb apod.). Segmentace vybraných zákazníků slouží k výběru a nacílení vhodné retenční kampaně.
Při tvorbě predikčních modelů se často používá testovací strategie, která dělí data z časového pohledu. Data do určitého časového okamžiku se určí jako trénovací data a od tohoto okamžiku za testovací data. Takový přístup simuluje nasazení modelu v praxi. Testovací data představují neznámou budoucnost a slouží k určení časové stability modelu. Pro některé případy je možné vzít nejlepší model bez ohledu na jeho zhoršující se kvalitu v čase. Pro dlouhodobě použitelné modely je však třeba vzít ten model, který vykazuje stabilně kvalitní chování v čase.
Vyhodnocení by mělo mít vazbu na předem definované cíle a obchodní aplikovatelnost. Typickým ukazatelem kvality modelu je tzv. lift, který představuje rozdíl mezi náhodným výběrem a výběrem provedeným pomocí predikčního modelu. Ukazatel přínosu také může být rozdíl mezi liftem stávajícího řešení a nově nalezeného řešení pomocí metod data miningu, což určuje předpokládaný ukazatel návratnosti investic.
Hlavním základem úspěchu je dobře navržená a řízená retenční kampaň, která reflektuje výstupy poskytované predikčním modelem. Následná segmentace zákazníků, kteří mají velkou pravděpodobnost odchodu, napomáhá hledat společné znaky skupin zákazníků, což pomáhá cílení i vytvoření kampaně. Některé ztrátové zákazníky nemá cenu držet, některé zákazníky zajímá drobná sleva, někoho přesvědčí poskytnutí jiné služby za zvýhodněných podmínek, do některých zákazníků vzhledem k jejich vysoké hodnotě má význam investovat více apod.
V telekomunikacích jsou například vhodné „slevy“ na předplacené karty (za 500 Kč dostanete službu za 550 Kč). Jinou možností, jak udržet klienty, je nabídnout určité skupině zákazníků nový telefon ještě před uplynutím smlouvy na dobu určitou s podmínkou prodloužení smlouvy na další cyklus. V bankovním a pojišťovacím sektoru napomáhají modely identifikovat špatně fungující služby či komunikaci se zákazníkem.
Důležitým závěrečným krokem je vyhodnocení celé kampaně. Vybraná skupina se rozdělí na dvě části s tím, že jedna část se osloví náhodně či pomocí dosavadní praxe a druhá část pomocí vytvořených predikčních modelů. Tak lze stanovit přínos řešení pomocí data miningu.
Přirozeným pokračováním celého procesu je jeho periodická opakovatelnost. V takovém případě je třeba účinnost predikčního modelu periodicky sledovat. Pokud model ztrácí dobré predikční vlastnosti, je nutné přikročit k novému modelování a vytvořit upravený predikční model na základě aktuálních dat. Fáze vytváření nového modelu není při zachování stejných datových základen časově náročná.
Modely odchodu také umožňují ověřovat cenovou politiku jednotlivých služeb, jejich kombinaci a optimalizaci spolu s lepším porozuměním klientům a jejich potřeb. Modely rovněž vytvářejí podněty pro lepší komunikaci se zákazníkem. Důležitým dlouhodobým přínosem je pak znalost získávaná z dat.
Zdroje:
www.crisp-dm.org – Cross Industry Standard Process for Data Mining.
Usama M. Fayyad, Gregory Piatetsky-Shapiro, Padhraic Smyth: From Data Mining to Knowledge Discovery: An Overview. Advances in Knowledge Discovery and Data Mining 1996, 1-34, AAAI, 1996.
Michael J. A. Berry, Gordon S. Linoff: Data Mining Techniques for Marketing, Sales and Customer Relationship Management, Wiley, 2004.
Autor působí jako data mining specialist ve společnosti Adastra.
Prevence odchodu zákazníka pomocí data miningu
Jan Kout
V dnešním konkurenčním prostředí
a díky nasycenému trhu přicházejí
nově získaní zákazníci převážně
od konkurence, a proto je udržení
stávajících zákazníků důležitým
měřítkem úspěchu a konkurenční
výhodou. Odchod stávajících
zákazníků přináší jak snížení
zisků, tak ztrátu pozice na trhu
a zároveň narůstající náklady na
získání nových klientů. Udržení
zákazníků řeší tzv. churn management,
který identifikuje mezi
zákazníky hlavní kandidáty na
odchod, zjišťuje příčiny jejich
chování, realizuje vhodnou
retenční kampaň k jejich udržení
a měří dosažené výsledky. Identifikaci zákazníků z hlediska jejich odchodu a zjištění příčin jejich odchodů nalézají metody data miningu. Výstupem procesů data miningu jsou modely, které aplikují vhodný algoritmus na historická data. Dalším zajímavým výstupem je z dat získaná znalost, která umožňuje systémovou změnu. Rychlý rozvoj datových skladů v kombinaci s výkonnou výpočetní technikou napomáhá vytvářet kvalitní predikční modely v rychlých časových cyklech. Celý projekt typicky trvá několik málo měsíců.
Data mining se definuje jako netriviální dobývání skrytých, předem neznámých a potenciálně užitečných informací z dat. Využívají se metody umělé inteligence (strojového učení) a statistiky. Velký rozvoj data miningu v akademickém světě začal v 70. a 80. letech minulého století a od konce 90. let se čím dál více jeho metody nasazují v praxi. Při realizaci se často postupuje podle metodologie CRISP-DM (CRoss Industry Standard Process for Data Mining). Celý proces se definuje jako průchod šesti fázemi s tím, že velký důraz se klade na iterativnost celého procesu. Právě možnost vrátit se v případě potřeby k jednotlivým předchozím fázím dává procesu velkou flexibilitu a možnosti optimalizace. Tento článek ukazuje životní cyklus řešení prevence odchodu zákazníků podle metodologie CRISP-DM.
Porozumění problému a stanovení obchodního cíle
Porozumění problému a definování cílů jsou hlavními předpoklady úspěchu projektu. Problém odchodu zákazníků se týká převážně telekomunikací, bankovnictví, pojišťovnictví, retailu a dalších segmentů, kde se obsluhuje větší množství zákazníků (v telekomunikacích se převážně hovoří o churn managementu, ve finanční sféře o attrition managementu).Predikce odchodu zákazníků je úkol, který je netriviální díky velkému množství dat a obtížnosti najít predikční model s vhodným obchodním přínosem. Odchod zákazníka zpravidla nebývá způsoben jedním důvodem (ani po měsíci mi nebyla zavedena služba), ale je obvykle způsoben kombinací několika důvodů (již nepotřebuji danou službu, přecházím na jinou, nejsem spokojen s komunikací, nabídka lepších cen). Další komplikací je, že každý odchod je jedinečný a zákazník při odchodu nesděluje důvod, proč odchází. Existuje pouze záznam o tom, že v daném čase odešel.
Poskytovatelé telekomunikačních služeb, tradiční pevné linky a mobilní operátoři, čelí úbytku zákazníků. Lidé buď odcházejí od pevných linek k mobilním operátorům, nebo přecházejí mezi jednotlivými mobilními operátory. Celosvětově ztrácí každý mobilní operátor v průměru měsíčně 2 % svých zákazníků. Ročně to může být i 25 %. Skoro polovina zákazníků internetových poskytovatelů také ročně odchází ke konkurenci. V bankovnictví odchází ročně mezi 10 % a 15 % zákazníků. Výzkumy ukazují, že udržení stávajících zákazníků je ekonomicky výhodnější (zhruba pět- až sedmkrát) než získávání nových. Hlavním důvodem je také fakt, že noví zákazníci nevyužívají tolik služeb v porovnání se stávajícími zákazníky.
Všechny společnosti v poslední době nabízejí kombinace více služeb prostřednictvím tzv. balíčků. Udržet zákazníka znamená nabídnout mu stejné, či pokud možno lepší podmínky a služby, které typicky využívá či využívat může. Možné cíle analýzy představují odpovědi na otázky jako:
- Neodcházejí zákazníci využívající stejnou službu? Není třeba službu upravit či změnit podmínky poskytování?
- Neodcházejí zákazníci využívající podobné kombinace služeb? Je třeba nabídnout nové balíčky služeb?
- Není problém v komunikaci se zákazníkem?
- Kdy dochází k rozhodnutí o odchodu? Jaké jsou projevy zákazníka v čase před rozhodnutím?
- Kdy k odchodu dochází? Jaké jsou typické příznaky odchodů?
Porozumění datům a jejich příprava
V dataminigových projektech se až 80 % času alokuje na přípravu dat. Zároveň je to patrně nejproblémovější fáze celého cyklu. V přípravě dat se střetává realita pochopení problému a jeho relevantnost vzhledem k dostupným datům. Dobrým předpokladem data miningu je kvalitní datový sklad, který integruje a agreguje všechny dostupné informace o zákaznících za dostatečně dlouhou dobu.Prvním důležitým krokem je definovat, co je odchod zákazníka, případně definovat fáze odchodu v čase. Doplňujícím identifikátorem je stanovení hodnoty zákazníka. Největší prioritu má identifikace zákazníků, kteří přinášejí užíváním svých služeb zisk, případně jinou hodnotu (např. prestiž, perspektivu růstu užívání služeb apod.). Identifikace hodnoty zákazníka se využívá při následném výběru a cílení kampaní.
Obr. 1: Nasazení CRISP-DM metodologie na prevenci odchodu zákazníků
Hlavním úkolem přípravy dat je vytvořit datamart. Datamart je datová matice, jejíchž řádky tvoří záznamy jednotlivých zákazníků. Sloupce popisující zákazníky pomocí atributů, které jsou vhodné pro vytváření modelů demografická data, behaviorální data, informace o odchodu, hodnota zákazníka a další). Atributy jsou buď přímo součástí datových skladů nebo se z nich odvozují pomocí vhodných transformací (čištění dat, diskretizace, normalizace, kombinace atributů, nelineární transformace apod.). Volba transformace je výsledkem analýzy a praktických zkušeností. Dalším faktorem je výběr dat z hlediska jejich stáří. Je třeba vybrat taková historická data, která mají relevantní význam. Má smysl použít dva roky stará data, když v tomto období nebyla dostupná daná služba? Mají tato data o odchodu odpovídající vypovídací hodnotu? V bankovnictví lze použít i starší data v porovnání s telekomunikačním trhem, který je daleko více dynamický.
Důležité je také správně definovat predikční mezeru, která definuje „zpoždění“ použití predikčního modelu. Zpravidla platí, že před odchodem zákazníci přestávají užívat určité služby, a to už většinou bývá pozdě na vhodnou kampaň. Predikční model založený na takové informaci pak nic užitečného nepřináší. Zákazník, který odejde a v posledních dvou měsících nevyužíval služeb, byl o odchodu patrně rozhodnut již před více než dvěma měsíci. Právě ve starších datech je třeba hledat důvody jeho odchodu, nevyužívání služeb v posledních dvou měsících je jen důsledek něčeho jiného, ne příčina jeho odchodu. Dalším důvodem tvorby predikční mezery je agregace dat, která se dokončuje po uplynutí daného období. Agregovaná data se aplikují na predikční model, identifikují se potenciálně odcházející zákazníci a následně lze spustit retenční kampaň. Obecně platí, že příliš dlouhá predikční mezera snižuje kvalitu modelu, a příliš krátká nerespektuje vhodně daný problém či neumožňuje včasně reagovat na získané informace. Zvolení optimální predikční mezery je tedy záležitostí správné obchodní úvahy a zkušenosti.
Modelování
Modelování obecně klade nároky na pochopení problému s ohledem na správnou interpretaci výsledků. Úloha identifikace odchodů zákazníků je příkladem klasifikační úlohy s učitelem. Výstupem klasifikačního modelu je rozhodnutí o stavu (v našem případě o dvou stavech: zákazník odchází/neodchází). Stav je možné v závislosti na použitém algoritmu doplnit „váhou“ takové informace (obvykle čísly mezi 0 a 1, které lze interpretovat mírou jistoty odchodu: určitě odchází, spíše odchází apod.). Pro úlohy s učitelem je charakterické využívání historických dat, která obsahují požadované vstupy i požadované výstupy. V našem případě víme, zda zákazník s danou charakteristikou v daném čase odešel, či nikoliv.Jako klasifikační algoritmy se nejčastěji používají rozhodovací stromy, logistická regrese, neuronové sítě, metoda podpůrných vektorů, případové uvažování a další. Hlavní výhodou algoritmů jako jsou rozhodovací stromy, logistická regrese a částečně i případového uvažování je snadná interpretace jejich výsledků. Je možné sledovat jak jednotlivé vstupy s danou hodnotou přispívají k celkovému výsledku. Z rozhodovacích stromů pak lze přímo generovat pravidla. To přispívá k důvěryhodnosti těchto metod a jejich obecné oblibě. Na druhou stranu neuronové sítě, metoda podpůrných vektorů a další mívají v některých případech lepší vlastnosti. Jejich nevýhodou je však komplikovanost modelu, který po přivedení vstupů dodá výstup s tím, že nelze lehce interpretovat, co se děje uvnitř.
Po identifikaci zákazníků, kteří mají velkou pravděpodobnost odchodu, je vhodné následně provést jejich segmentaci. Segmentace rozdělí vybrané zákazníky do skupin, které jsou charakteristické určitým druhem chování (např. hodnota zákazníka, využívající danou službu, více služeb apod.). Segmentace vybraných zákazníků slouží k výběru a nacílení vhodné retenční kampaně.
Vyhodnocení modelů
Ať už je model vytvořen jakýmkoliv algoritmem nebo jejich kombinací, je vždy třeba otestovat jeho kvalitu a robustnost na datech, která nebyla použita během vytváření modelu. Při použití stejných dat na trénování i testování hrozí problém přeučení (overfitting). K testování modelů se obvykle přistupuje tak, že se původní datová množina rozdělí na dvě části. Jedna se použije pro vytváření modelu (trénovací data) a druhá pro testování (testovací data). Testovací část obvykle tvoří okolo 20–40 % objemu dat. Jestliže má vytvořený model lepší vlastnosti na trénovacích datech a výrazně horší na testovacích, pak je model pravděpodobně přeučen, tj. má slabé generalizující schopnosti na neznámých datech. V takovém případě je třeba provést fázi učení znovu s jinými parametry vytváření modelů, případně najít jiné vhodné popisující atributy.Při tvorbě predikčních modelů se často používá testovací strategie, která dělí data z časového pohledu. Data do určitého časového okamžiku se určí jako trénovací data a od tohoto okamžiku za testovací data. Takový přístup simuluje nasazení modelu v praxi. Testovací data představují neznámou budoucnost a slouží k určení časové stability modelu. Pro některé případy je možné vzít nejlepší model bez ohledu na jeho zhoršující se kvalitu v čase. Pro dlouhodobě použitelné modely je však třeba vzít ten model, který vykazuje stabilně kvalitní chování v čase.
Vyhodnocení by mělo mít vazbu na předem definované cíle a obchodní aplikovatelnost. Typickým ukazatelem kvality modelu je tzv. lift, který představuje rozdíl mezi náhodným výběrem a výběrem provedeným pomocí predikčního modelu. Ukazatel přínosu také může být rozdíl mezi liftem stávajícího řešení a nově nalezeného řešení pomocí metod data miningu, což určuje předpokládaný ukazatel návratnosti investic.
Nasazení – aplikace modelů k udržení zákazníků
Žádný predikční model nezaručuje úspěch při udržení zákazníků. Fáze nasazení predikčního modelu je klíčovou a zároveň rizikovou součástí celého procesu. Je to způsobeno tím, že se dataminingové projekty převážně realizují ve velkých firmách, které mají nastaveny interní procesy a jejich změna je často komplikovaná.Hlavním základem úspěchu je dobře navržená a řízená retenční kampaň, která reflektuje výstupy poskytované predikčním modelem. Následná segmentace zákazníků, kteří mají velkou pravděpodobnost odchodu, napomáhá hledat společné znaky skupin zákazníků, což pomáhá cílení i vytvoření kampaně. Některé ztrátové zákazníky nemá cenu držet, některé zákazníky zajímá drobná sleva, někoho přesvědčí poskytnutí jiné služby za zvýhodněných podmínek, do některých zákazníků vzhledem k jejich vysoké hodnotě má význam investovat více apod.
V telekomunikacích jsou například vhodné „slevy“ na předplacené karty (za 500 Kč dostanete službu za 550 Kč). Jinou možností, jak udržet klienty, je nabídnout určité skupině zákazníků nový telefon ještě před uplynutím smlouvy na dobu určitou s podmínkou prodloužení smlouvy na další cyklus. V bankovním a pojišťovacím sektoru napomáhají modely identifikovat špatně fungující služby či komunikaci se zákazníkem.
Důležitým závěrečným krokem je vyhodnocení celé kampaně. Vybraná skupina se rozdělí na dvě části s tím, že jedna část se osloví náhodně či pomocí dosavadní praxe a druhá část pomocí vytvořených predikčních modelů. Tak lze stanovit přínos řešení pomocí data miningu.
Přirozeným pokračováním celého procesu je jeho periodická opakovatelnost. V takovém případě je třeba účinnost predikčního modelu periodicky sledovat. Pokud model ztrácí dobré predikční vlastnosti, je nutné přikročit k novému modelování a vytvořit upravený predikční model na základě aktuálních dat. Fáze vytváření nového modelu není při zachování stejných datových základen časově náročná.
Ať vám neutíkají klienti
Data mining přináší do churn managementu významnou přidanou hodnotu. Jeho výstupy primárně umožňují cíleně oslovovat zákazníky, kteří přinášejí hodnotu a pravděpodobnost jejich odchodu je velká.Modely odchodu také umožňují ověřovat cenovou politiku jednotlivých služeb, jejich kombinaci a optimalizaci spolu s lepším porozuměním klientům a jejich potřeb. Modely rovněž vytvářejí podněty pro lepší komunikaci se zákazníkem. Důležitým dlouhodobým přínosem je pak znalost získávaná z dat.
Zdroje:
www.crisp-dm.org – Cross Industry Standard Process for Data Mining.
Usama M. Fayyad, Gregory Piatetsky-Shapiro, Padhraic Smyth: From Data Mining to Knowledge Discovery: An Overview. Advances in Knowledge Discovery and Data Mining 1996, 1-34, AAAI, 1996.
Michael J. A. Berry, Gordon S. Linoff: Data Mining Techniques for Marketing, Sales and Customer Relationship Management, Wiley, 2004.
Autor působí jako data mining specialist ve společnosti Adastra.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce