

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Hlavní partner sekce

Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

Data Warehousing , AI a Business Intelligence
 Datové sklady jsou velmi sofistikovaná řešení, která musí spoléhat na nejmodernější vlastnosti aktuálních verzí špičkových databázových systémů. Právě na prostředcích, které databázový systém poskytuje tvůrcům datového skladu, závisí schopnost výsledného řešení vyhovět uživatelům v jejich analýzách rozsáhlých historických dat při krátkých dobách odezvy. O jednom z nich se zmíním v tomto článku.
Datové sklady jsou velmi sofistikovaná řešení, která musí spoléhat na nejmodernější vlastnosti aktuálních verzí špičkových databázových systémů. Právě na prostředcích, které databázový systém poskytuje tvůrcům datového skladu, závisí schopnost výsledného řešení vyhovět uživatelům v jejich analýzách rozsáhlých historických dat při krátkých dobách odezvy. O jednom z nich se zmíním v tomto článku.


Návrh datových modelů datových skladů se řídí určitými doporučeními. Jejich respektování zajišťuje řešiteli alespoň základní záruku schopnosti dnešních relačních databázových systémů s daným datovým modelem efektivně pracovat (viz například kapitoly Dimensional Data Modeling na stránkách www.learndatamodeling.com).
Datové kostky, nazývané někdy také tabulky faktů, obsahují obvykle velké množství záznamů. V jejich položkách nalezneme hodnoty, které lze nějakým způsobem agregovat (např. položka s názvem „Prodej Kč“ je v analýzách agregována do výstupu „Suma prodeje Kč“).
V tabulkách dimenzí se většinou nachází méně záznamů než v datových kostkách. Jedná se o záznamy-klíče, které slouží pro řezy datovou kostkou. Do tabulek dimenzí se zpravidla načítají záznamy číselníků zdrojových provozních systémů společnosti. Využitím dimenze „Produkt“ a jejích záznamů popisujících jednotlivé produkty společnosti tak můžeme provést řez datovou kostkou a získat tak „sumy prodeje v Kč za jednotlivé produkty“ nebo „top10 produktů dle sumy prodaných kusů“.
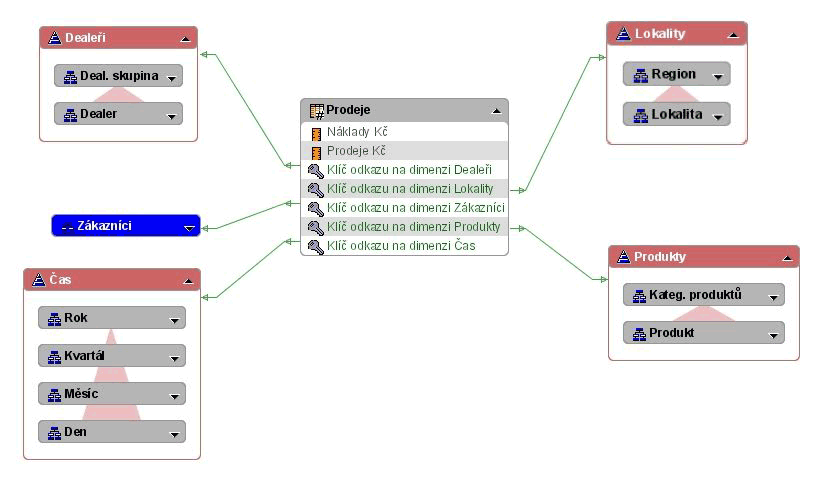
Jedna datová kostka je obvykle napojena svými klíčovými položkami na několik dimenzí, které ji ve schématickém znázornění obklopují. Dimenze pak slouží pro různé analytické řezy danou datovou kostkou („kategorizaci“ jejích dat). Datové modely používané v praxi nesou označení podle schématického rozmístění tabulek dimenzí kolem datové kostky. Při návrhu se vývojář obvykle drží buď hvězdicového schématu (star schema) nebo schématu sněhové vločky (snowflake schema).
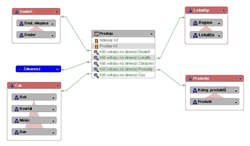
Obr. 1: Prodeje – hvězdicové schéma
Pro vysvětlení rozdílu mezi zmíněnými dvěma schématy datových modelů je nutné rozšířit informace o dimenzích.
Hierarchie najdeme téměř u všech dimenzí. Produkty jsou obvykle zařazené do Kategorií produktů, Pobočky společnosti geograficky náleží k Regionu, Kraji a Státu atp. Rozdíl mezi hvězdicovým schématem a schématem sněhové vločky je nejvíce patrný právě z definice hierarchií dimenzí. V případě datových modelů sestavených podle hvězdicového schématu jsou hierarchie dimenzí tvořeny pouze úrovněmi, jejichž klíčové položky jsou uvnitř jediné tabulky. U schématu sněhové vločky jsou klíčové položky jednotlivých úrovní hierarchií dimenzí rozprostřeny v několika tabulkách vzájemně propojených vazbou s kardinalitou „N:1“. Data dimenze Produkt mohou být v tomto schématu rozprostřena do dvou tabulek Produkt a Kategorie produktů. Ke každému záznamu tabulky Produkt je navázán klíčem příslušný záznam jeho kategorie z tabulky Kategorie produktů. V datovém modelu navrženém podle schématu sněhové vločky pak obvykle tabulkám, které tvoří dimenzi, odpovídají i definované úrovně hierarchií dané dimenze. V našem příkladu bude hierarchie dimenze Produkt sestávat z minimálně dvou úrovní – Produkt a Kategorie produktů.
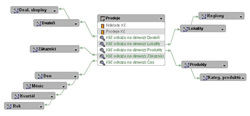
Obr. 2: Prodeje – schéma sněhové vločky
Datový model navržený podle schématu sněhové vločky se zpravidla pečlivě drží „třetí normální formy“ (viz heslo „database normalization“ na stránkách www.wikipedia.org). Naopak v hvězdicových schématech jsou data, i za cenu redundance uložení údajů, „denormalizována“ do jedné jediné tabulky. Na obranu těchto hvězdicových datových modelů je však třeba uvést, že u datových skladů není nutné se obávat následků denormalizace dat v tabulkách dimenzí. Aktualizaci dat datových skladů neprovádějí uživatelé, ale obstarávají ji, většinou dávkově, ETL procesy. Ty dokáží při přesunu a transformaci dat pohlídat konzistenci redundantního obsahu tabulek dimenzí. S hvězdicovými schématy se v praxi setkáme nejčastěji, protože mají díky své jednodušší struktuře rozsáhlejší podporu ze strany dnešních relačních databázových systémů. Denormalizace údajů v tabulkách dimenzí vede i k rychlejším odezvám.
Aby celý tento článek nevyzněl zcela teoreticky, přesuňme se ke konkrétní implementaci snímků v databázovém systému Oracle. Snímky s připravenými výsledky vyšších úrovní agregací se realizují v databázi Oracle užitím objektů zvaných Materialized View (materializované pohledy). „Materializace“ těchto „pohledů“ spočívá v tom, že se určitý pohled na data (výsledek dotazu SQL) zhmotní v podobě tabulky, do které je výsledek uložen. Dotyčný pohled může být sestaven právě jako onen výše zmíněný výsledek agregací spočtených po jednotlivých měsících. Výsledky uložené ve snímcích, protože jejich obsah odpovídá zmrazenému stavu surových dat v době materializace pohledu, se musí pravidelně aktualizovat. Jednou z velmi příjemných vlastností databázového systému Oracle je jeho schopnost provádět rychlé, inkrementální aktualizace těchto snímků. Pokud při implementaci datového modelu a snímků jejich tvůrce dodrží určité dané podmínky, provádí databázový systém Oracle aktualizaci pouze těch záznamů výsledků, jichž se dotkla změna v surových datech v datových kostkách a/nebo dimenzích.
Pokud toho skutečně chceme dosáhnout, musí, buď přímo databázový server, nebo nějaká jiná programová vrstva mezi uživatelem a daty, umět vyhodnotit, zda se již uživatel dostal při analýze dat na tak vysokou úroveň agregace, že je již možné přesměrovat jeho dotaz právě na tabulku předpočítaných výsledků. V databázovém systému Oracle vyhodnocuje všechny dotazy kladené systému tzv. optimalizátor. Ten je již od verze 8i schopen inteligentně posuzovat, za jakých okolností lze dotaz přesměrovat na připravené výsledky v tabulkách materializovaných pohledů a zda to skutečně povede z hlediska času či zatížení zdrojů serveru k úsporám. Tato jeho vlastnost je nazývaná Query Rewrite (přepis dotazu). Při globálních analýzách využití této vlastnosti přináší neporovnatelné zrychlení odezvy. U objemnějších tabulek by v reálném čase ani nebyly analýzy takového rozsahu dat bez optimalizace možné.
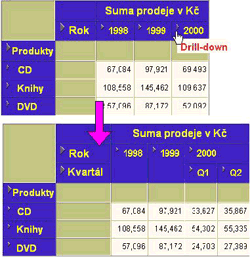
Obr. 3: Drill-down z úrovně roku 2000 na jeho kvartály
Uživatel se pak z globálního přehledu zanoří do zobrazení jednotlivých měsíců vybraných kvartálů. I zde databázový systém použije připravené snímky a odezva zůstává stále přijatelná. Další rozbalování všech buněk vybraného období do větší podrobnosti nemá smysl, protože by byl uživatel zahlcen takovým množstvím záznamů, že by z nich stejně nemohl dělat žádné závěry. Budeme tedy předpokládat, že uživatele z nějakého důvodu zaujaly výsledky v některém ze zobrazených kalendářních měsíců. Zanoří se tedy do podrobnosti pouze na této konkrétní buňce analytického výstupu. V globální analýze se v místě dané buňky rozevře detail. Dle požadavku uživatele to může být detail v úrovni dekád či dokonce dnů. Při přípravě odpovědi se databázový systém již nemůže opírat o snímky. Uživatel se zanořením do detailu dostal pod úroveň agregace, která byla použita při přípravě snímků. V tuto chvíli jsou však již databázovému systému známa omezujících kritéria požadovaného detailu. Kontext původní buňky globálního přehledu, ve které se uživatel do detailu zanořil, udává jednoznačně kategorii produktů a kalendářní měsíc, který uživatele v detailu zajímá. V tomto rozsahu již nedělá databázovému systému potíže v reálném čase filtrovat a agregovat data surová, přímo z datové kostky.
Náš uživatel-analytik v průběhu své práce s analytickými (BI) nástroji ani nezaznamenal, kdy databázový systém použil připravené předpočítané výsledky ze snímků, a kdy již přešel k práci se surovými daty datové kostky.
Autor článku působí ve společnosti Per4mance.
Optimalizace odezev pro globální přehledy
Karel Novotný
Datové sklady jsou velmi sofistikovaná řešení, která musí spoléhat na nejmodernější vlastnosti aktuálních verzí špičkových databázových systémů. Právě na prostředcích, které databázový systém poskytuje tvůrcům datového skladu, závisí schopnost výsledného řešení vyhovět uživatelům v jejich analýzách rozsáhlých historických dat při krátkých dobách odezvy. O jednom z nich se zmíním v tomto článku. Datové modely datových skladů
Nejdříve však zrekapitulujme základní principy datových skladů. V datových skladech nejsou „živá“ data, která uživatelé přímo aktualizují. Do datových skladů se data přesunují z jiných zdrojů dat (většinou provozních systémů) a transformují se do datového modelu navrženého specificky pro analýzy velkého množství dat. Díky zaměření datových skladů na sledování trendů a vzájemné porovnávání výsledků v mnohaleté historii jsou analýzy prováděné nad tabulkami se stamiliony záznamů běžnou praxí. Právě kvalita návrhu datového modelu datového skladu ovlivňuje nejvyšší měrou výslednou použitelnost řešení. Sebelepší nadstavba v podobě nástroje BI (business intelligence) či jakékoliv aplikace pro analýzy nemůže eliminovat handicap vzniklý nekvalitním návrhem datového modelu.Návrh datových modelů datových skladů se řídí určitými doporučeními. Jejich respektování zajišťuje řešiteli alespoň základní záruku schopnosti dnešních relačních databázových systémů s daným datovým modelem efektivně pracovat (viz například kapitoly Dimensional Data Modeling na stránkách www.learndatamodeling.com).
Hvězda nebo sněhová vločka?
Základními objekty cílového datového modelu jsou i v případě datových skladů tabulky. Rozdělujeme je však logicky podle jejich role a také počtu záznamů na tzv. dimenze a datové kostky.Datové kostky, nazývané někdy také tabulky faktů, obsahují obvykle velké množství záznamů. V jejich položkách nalezneme hodnoty, které lze nějakým způsobem agregovat (např. položka s názvem „Prodej Kč“ je v analýzách agregována do výstupu „Suma prodeje Kč“).
V tabulkách dimenzí se většinou nachází méně záznamů než v datových kostkách. Jedná se o záznamy-klíče, které slouží pro řezy datovou kostkou. Do tabulek dimenzí se zpravidla načítají záznamy číselníků zdrojových provozních systémů společnosti. Využitím dimenze „Produkt“ a jejích záznamů popisujících jednotlivé produkty společnosti tak můžeme provést řez datovou kostkou a získat tak „sumy prodeje v Kč za jednotlivé produkty“ nebo „top10 produktů dle sumy prodaných kusů“.
Jedna datová kostka je obvykle napojena svými klíčovými položkami na několik dimenzí, které ji ve schématickém znázornění obklopují. Dimenze pak slouží pro různé analytické řezy danou datovou kostkou („kategorizaci“ jejích dat). Datové modely používané v praxi nesou označení podle schématického rozmístění tabulek dimenzí kolem datové kostky. Při návrhu se vývojář obvykle drží buď hvězdicového schématu (star schema) nebo schématu sněhové vločky (snowflake schema).
Obr. 1: Prodeje – hvězdicové schéma
Pro vysvětlení rozdílu mezi zmíněnými dvěma schématy datových modelů je nutné rozšířit informace o dimenzích.
Hierarchie dimenzí
V rámci definice dimenzí se setkáváme s tzv. hierarchiemi. V analýzách chceme uživatelům umožnit zanořování a vynořování do/z úrovně podrobnosti pohledu. Nejjednodušší příkladem adepta pro definici hierarchie je „časová dimenze“. U ní bude zcela jistě požadována flexibilita úrovně zanoření do detailu a tím i agregace surových dat. Uživatel bude v analýzách požadovat přehledy s údaji agregovanými po kvartálech, po měsících a někdy po dekádách či jednotlivých dnech. Právě tyto úrovně agregace zároveň tvoří úrovně hierarchie časové dimenze.Hierarchie najdeme téměř u všech dimenzí. Produkty jsou obvykle zařazené do Kategorií produktů, Pobočky společnosti geograficky náleží k Regionu, Kraji a Státu atp. Rozdíl mezi hvězdicovým schématem a schématem sněhové vločky je nejvíce patrný právě z definice hierarchií dimenzí. V případě datových modelů sestavených podle hvězdicového schématu jsou hierarchie dimenzí tvořeny pouze úrovněmi, jejichž klíčové položky jsou uvnitř jediné tabulky. U schématu sněhové vločky jsou klíčové položky jednotlivých úrovní hierarchií dimenzí rozprostřeny v několika tabulkách vzájemně propojených vazbou s kardinalitou „N:1“. Data dimenze Produkt mohou být v tomto schématu rozprostřena do dvou tabulek Produkt a Kategorie produktů. Ke každému záznamu tabulky Produkt je navázán klíčem příslušný záznam jeho kategorie z tabulky Kategorie produktů. V datovém modelu navrženém podle schématu sněhové vločky pak obvykle tabulkám, které tvoří dimenzi, odpovídají i definované úrovně hierarchií dané dimenze. V našem příkladu bude hierarchie dimenze Produkt sestávat z minimálně dvou úrovní – Produkt a Kategorie produktů.
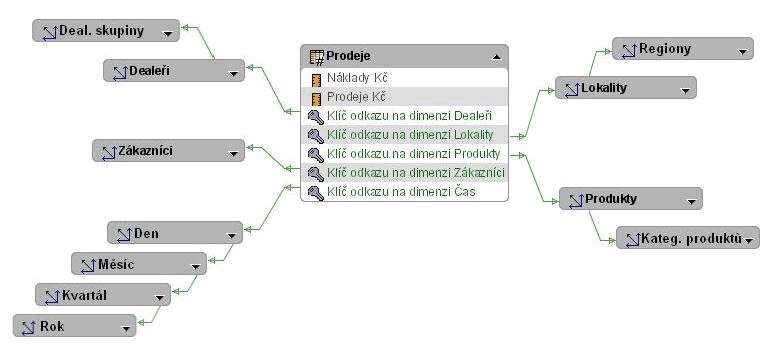
Obr. 2: Prodeje – schéma sněhové vločky
Datový model navržený podle schématu sněhové vločky se zpravidla pečlivě drží „třetí normální formy“ (viz heslo „database normalization“ na stránkách www.wikipedia.org). Naopak v hvězdicových schématech jsou data, i za cenu redundance uložení údajů, „denormalizována“ do jedné jediné tabulky. Na obranu těchto hvězdicových datových modelů je však třeba uvést, že u datových skladů není nutné se obávat následků denormalizace dat v tabulkách dimenzí. Aktualizaci dat datových skladů neprovádějí uživatelé, ale obstarávají ji, většinou dávkově, ETL procesy. Ty dokáží při přesunu a transformaci dat pohlídat konzistenci redundantního obsahu tabulek dimenzí. S hvězdicovými schématy se v praxi setkáme nejčastěji, protože mají díky své jednodušší struktuře rozsáhlejší podporu ze strany dnešních relačních databázových systémů. Denormalizace údajů v tabulkách dimenzí vede i k rychlejším odezvám.
Optimalizace odezev pro globální přehledy
Vraťme se nyní k dříve zmíněné flexibilitě analýz prováděných uživatelem. Manažera společnosti více než údaje určitého dne nebo týdne zajímá globální pohled na data společnosti. Časté jsou tedy v analytických výstupech agregace po měsících či kvartálech a jednotlivých pobočkách společnosti v dlouhodobém historickém kontextu. Jak počet záznamů v datovém skladu narůstá, je zřejmé, že není možné uspokojit požadavek uživatele tak, že teprve při spuštění analýzy budou data vyhledávána a agregována „ad hoc“. Problém rychlé dostupnosti výsledků globálních analýz se řeší tak, že se v době mimo špičku provozu systému vytvoří v databázi tzv. snímky. Do snímku se uloží výsledky agregací obsahu položek datové kostky v daném čase. Pokud jsou například „surová data“ v datové kostce uložena v detailu po jednotlivých dnech, ve snímku již můžeme mít uložené výsledky agregací hodnot po měsících a/nebo kvartálech. Konkrétní implementace snímků v dnešních databázových systémech se velmi liší. Někde dokonce neexistuje vůbec, takže řešitel datového skladu nad těmito databázemi musí podporu pro uložení výsledků vyšších úrovní agregací sám vyvinout a řešit ji pak na úrovni své aplikace.Aby celý tento článek nevyzněl zcela teoreticky, přesuňme se ke konkrétní implementaci snímků v databázovém systému Oracle. Snímky s připravenými výsledky vyšších úrovní agregací se realizují v databázi Oracle užitím objektů zvaných Materialized View (materializované pohledy). „Materializace“ těchto „pohledů“ spočívá v tom, že se určitý pohled na data (výsledek dotazu SQL) zhmotní v podobě tabulky, do které je výsledek uložen. Dotyčný pohled může být sestaven právě jako onen výše zmíněný výsledek agregací spočtených po jednotlivých měsících. Výsledky uložené ve snímcích, protože jejich obsah odpovídá zmrazenému stavu surových dat v době materializace pohledu, se musí pravidelně aktualizovat. Jednou z velmi příjemných vlastností databázového systému Oracle je jeho schopnost provádět rychlé, inkrementální aktualizace těchto snímků. Pokud při implementaci datového modelu a snímků jejich tvůrce dodrží určité dané podmínky, provádí databázový systém Oracle aktualizaci pouze těch záznamů výsledků, jichž se dotkla změna v surových datech v datových kostkách a/nebo dimenzích.
Transparentnost řešení pro uživatele i aplikace
Samotná existence připravených předagregovaných údajů v tabulkách materializovaných pohledů by však měla jen malý přínos pro uživatele, pokud by jeho dotazy spouštěné z analytických nástrojů či BI aplikací dále směřovaly do surových (detailních) dat datových kostek. Přitom nechceme koncového uživatele řešení nutit ke změnám definice analytického výstupu podle úrovně zanoření v hierarchii. V ideálním případě by uživatel neměl mít ani tušení o tom, že si databáze musí pro globální přehledy, tedy vyšší úrovně agregace, vypomáhat nějakým trikem, spočívajícím ve využívání předpočítaných výsledků ze snímků.Pokud toho skutečně chceme dosáhnout, musí, buď přímo databázový server, nebo nějaká jiná programová vrstva mezi uživatelem a daty, umět vyhodnotit, zda se již uživatel dostal při analýze dat na tak vysokou úroveň agregace, že je již možné přesměrovat jeho dotaz právě na tabulku předpočítaných výsledků. V databázovém systému Oracle vyhodnocuje všechny dotazy kladené systému tzv. optimalizátor. Ten je již od verze 8i schopen inteligentně posuzovat, za jakých okolností lze dotaz přesměrovat na připravené výsledky v tabulkách materializovaných pohledů a zda to skutečně povede z hlediska času či zatížení zdrojů serveru k úsporám. Tato jeho vlastnost je nazývaná Query Rewrite (přepis dotazu). Při globálních analýzách využití této vlastnosti přináší neporovnatelné zrychlení odezvy. U objemnějších tabulek by v reálném čase ani nebyly analýzy takového rozsahu dat bez optimalizace možné.
Drill-down (zanoření do detailu v kontextu)
Budeme-li sledovat běžný postup uživatele-analytika z pohledu odbavení jeho dotazu databázovým systémem, začneme s ním na úrovni globálního přehledu. Po databázovém systému se požaduje, aby vypočetl a vrátil sumy prodejů v Kč za aktuální kvartál a vybrané kategorie produktů. Navíc má být ve výstupu pro porovnání i předchozí kvartál a stejný kvartál minulého roku. Agregace, kterou uživatel pro přehled požaduje, je v tomto případě nad úrovní použitou při materializaci výsledků ve snímcích. Připomeňme, že jsme do tabulek materializovaných pohledů (snímků) uložili výsledky agregací po měsících. Databázový systém vyhodnotí, že v případě tohoto požadavku bude snadnější a rychlejší spočítat výsledné sumy za kvartál z existujících „měsíčních“ výsledků, a použije připravené snímky.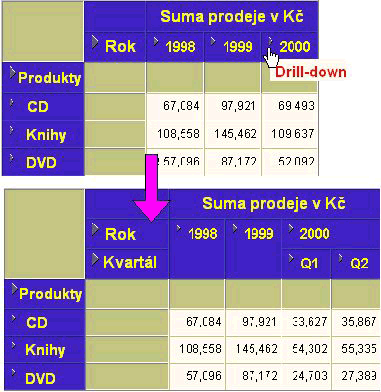
Obr. 3: Drill-down z úrovně roku 2000 na jeho kvartály
Uživatel se pak z globálního přehledu zanoří do zobrazení jednotlivých měsíců vybraných kvartálů. I zde databázový systém použije připravené snímky a odezva zůstává stále přijatelná. Další rozbalování všech buněk vybraného období do větší podrobnosti nemá smysl, protože by byl uživatel zahlcen takovým množstvím záznamů, že by z nich stejně nemohl dělat žádné závěry. Budeme tedy předpokládat, že uživatele z nějakého důvodu zaujaly výsledky v některém ze zobrazených kalendářních měsíců. Zanoří se tedy do podrobnosti pouze na této konkrétní buňce analytického výstupu. V globální analýze se v místě dané buňky rozevře detail. Dle požadavku uživatele to může být detail v úrovni dekád či dokonce dnů. Při přípravě odpovědi se databázový systém již nemůže opírat o snímky. Uživatel se zanořením do detailu dostal pod úroveň agregace, která byla použita při přípravě snímků. V tuto chvíli jsou však již databázovému systému známa omezujících kritéria požadovaného detailu. Kontext původní buňky globálního přehledu, ve které se uživatel do detailu zanořil, udává jednoznačně kategorii produktů a kalendářní měsíc, který uživatele v detailu zajímá. V tomto rozsahu již nedělá databázovému systému potíže v reálném čase filtrovat a agregovat data surová, přímo z datové kostky.
Náš uživatel-analytik v průběhu své práce s analytickými (BI) nástroji ani nezaznamenal, kdy databázový systém použil připravené předpočítané výsledky ze snímků, a kdy již přešel k práci se surovými daty datové kostky.
Závěrem
Závěrem můžeme shrnout největší výhody tohoto řešení. Uživatele, především z řad vyššího managementu, zajímají spíše globální přehledy (např. prodeje za aktuální kvartál v porovnání se stejným kvartálem předchozích tří let za všechny pobočky). Nezřídka se ale také stává, že se analytikovi na základě globálního přehledu podaří identifikovat nějakou zjevnou anomálii (např. v prodeji určité kategorie produktů v některém ze zobrazených měsíců). Pak se analytik z globálních přehledů potřebuje zanořit do detailu a zjistit, který produkt, či konkrétně který dealer anomálii způsobil. Anomálie může být paradoxně způsobena i jednou jedinou fakturou. Nelze tedy předem říci, jakou úroveň podrobnosti bude uživatel vyžadovat. Proto je tak důležité, aby dříve zmíněné automatické přesměrování dotazů na tabulku s přepočítanými výsledky agregací bylo pro uživatele i jeho nástroj či aplikaci zcela transparentní. Uživatelé, ať již se pohybují v jakékoliv úrovni zanoření do detailu, dostanou v jednotkách vteřin výsledky agregací, které požadují.Autor článku působí ve společnosti Per4mance.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce