

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Hlavní partner sekce

Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT řešení pro veřejný sektor a zdravotnictví , AI a Business Intelligence , Veřejný sektor a zdravotnictví


Odhalování podvodů ve státní sféře pomocí data miningu
 Nepodvedeš, nepokradeš. Jedny ze základních předpokladů slušné společnosti. Bohužel však v minulých desetiletích spíše platilo „kdo nekrade, okrádá rodinu“ a nyní stále ještě většinou platí „že příležitost dělá zloděje“. Ve státní sféře, kde se přerozdělují miliardové prostředky, je takových příležitostí opravdu hodně. Odhalování podvodů ve státní sféře čelí několika obtížím. Jsou jimi dynamika prostředí, utajení většiny informací a diverzita podvodů. Důležité je zdůraznit, že nestačí podvod pouze detekovat, ale také aktivně prošetřit a dovést do legislativního vyústění. Tento článek popisuje hlavně první část odhalování podvodů, tedy jejich detekci.
Nepodvedeš, nepokradeš. Jedny ze základních předpokladů slušné společnosti. Bohužel však v minulých desetiletích spíše platilo „kdo nekrade, okrádá rodinu“ a nyní stále ještě většinou platí „že příležitost dělá zloděje“. Ve státní sféře, kde se přerozdělují miliardové prostředky, je takových příležitostí opravdu hodně. Odhalování podvodů ve státní sféře čelí několika obtížím. Jsou jimi dynamika prostředí, utajení většiny informací a diverzita podvodů. Důležité je zdůraznit, že nestačí podvod pouze detekovat, ale také aktivně prošetřit a dovést do legislativního vyústění. Tento článek popisuje hlavně první část odhalování podvodů, tedy jejich detekci.
Normální je nepodvádět
Podvod je v českém právním řádu zjednodušeně definován jako chování, kdy někdo uvede někoho jiného v omyl s úmyslem obohatit se. Podobná situace může nastat i neúmyslně, např. nesplněním všech legislativních podmínek. Nicméně platí, že neznalost zákona neomlouvá. Oba případy, úmyslné i neúmyslné, pak anglickou terminologií nazýváme fraud, úlohu jeho odhalování fraud detection. Cílem úlohy je zefektivnit práci vyšetřovatelů, ušetřit peníze a najít nové vzory podvodného chování.
Podvody se vyskytují prakticky všude, kde jde o peníze. Příkladem „omylů“ ve státní sféře mohou být zmanipulovaná výběrová řízení, dotace či daňové úniky. Atraktivitu státní sféry pro podvodníky zvyšuje skutečnost, že státní sféra často není ochotna, nebo s ohledem na rozpočtové možnosti schopna, proti fraudu účinně bojovat.
Detekce podvodů je klasickou dataminingovou úlohou zpracovávající relativně velké množství dat, včetně dat specifických pro různé oblasti státní sféry. Jedná se například o dotační žádosti, daňová přiznání nebo různé obchodní informace. Charakteristikou dat ve státní sféře je, že jsou často zastaralá, nekonzistentní a i v rámci jednoho ministerstva či odboru jsou v různých formátech. Nevýhodou této úlohy je skutečnost, že neexistuje jasný postup jak proti fraudu bojovat. Výraznou oporou při řešení úlohy nám může být obecná dataminingová metodologie CRISP-DM a útěchou skutečnost, že detekce podvodů bývá dataminingová úloha s největší návratností investice, tzv. ROI.
Dataminingová metodologie a nástroje
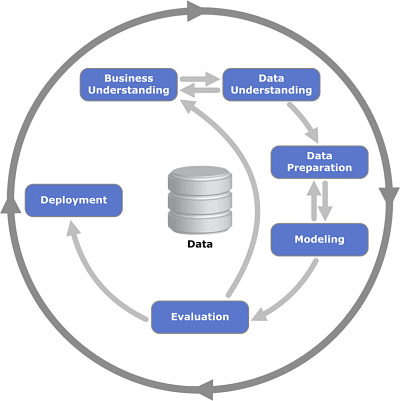
Detekci podvodů lze řešit různými nástroji a různými postupy. Jedním z nich je řešení úlohy v souladu s dataminingovou metodologií CRISP-DM (Cross Industry Standard Proces for Data-mining). Ta rozděluje dataminingovou úlohu na několik navazujících fází. Metodologie nedefinuje striktně, jak danou úlohu řešit, ale jakými pravidly se při jejím řešení řídit. Šipkami je vyznačena časová posloupnost zpracování dataminingové úlohy.

Každá fáze je důležitá a podcenění či nekvalitní provedení jakékoli fáze by mělo fatální následky. V prvé řadě je třeba úlohu pochopit a definovat její cíle. Poté je třeba důkladně prozkoumat a analyzovat data z hlediska jejich kvality a dostupnosti. Časově nejnáročnější je fáze Data Preparation, kde se provádí datové operace, jako jsou slučování datasetů, přidání záznamů, výběr případů, agregace záznamů, odvození nových proměnných, třídění, ošetření chybných a chybějících hodnot. Fáze modelování spočívá v nalezení vhodných predikčních modelů. Ty se následně ověřují, do jaké míry splňují stanovená kritéria úspěchu. Celý proces končí nasazením řešení do praxe a jeho integrací do provozních procesů.
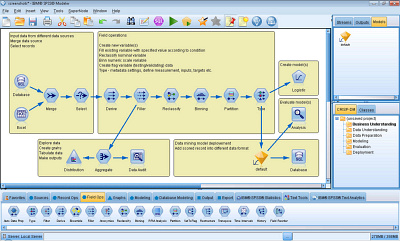
Kvalita predikčních modelů je dána kvalitou dat použitých k jejich odvození. Kvalitu dat nejvíce ovlivňující procesy, které většinou nijak ovlivnit nemůžeme. Pro zajištění kvality dat je za prvé třeba pochopit, jak jsou data zaznamenána, v jakém umístění, formátu, aktuálnosti, granularitě atd. Za druhé musí být k dispozici nástroj, který taková data dokáže zpracovat, provést s nimi potřebné manipulace a transformace, odhadnout a evaluovat predikční modely. Takový nástroj musí být datově nezávislý, graficky a uživatelsky přívětivý a jednoduchý. Musí disponovat širokým spektrem funkcí a predikčních algoritmů. Na obrázku je ukázka rozhraní takového nástroje, ve kterém se vytváří datový tok, posloupnost operací od načtení datového zdroje po export výsledků.

Praktické řešení detekce podvodů
Hlavním cílem detekce podvodů je redukovat obrovské množství případů, které by mohlo být zkontrolováno a identifikovat pouze ty nejpodezřelejší. To zefektivní práci vyšetřovatelů a povede k jejich vyšší úspěšnosti při stejných nákladech. Mechanismus určující podezřelost případu, může být různý. V praxi se používá několik přístupů.
Prvním z nich jsou expertní pravidla. Je to znalost vyšetřovatelů a analytiků získaná zkušenostmi. Pokud tato znalost není nijak formalizována a procesně zaznamenána, hrozí nebezpečí, že odchodem takového člověka se tato znalost ztratí. Formalizací expertních pravidel vznikne sada jednoznačných a srozumitelných podmínek. Expertní pravidla přidělují každému případu trestné body. Jejich součet je kategorizován a každé kategorii přiřazena nějaká akce, například nevyšetřovat, projít standardním postupem, oznámit a prošetřit.
Druhým přístupem jsou predikční modely. Ty vychází z analýzy tzv. behaviorálních dat popisujících chování zkoumaného subjektu. Subjektem může být žadatel o dotaci, či plátce daně. Často se jedná o transakční data, která se agregují na úroveň subjektu nebo za určitá časová období. Pro identifikaci podezřelých případů se používají tzv. supervizované, učící se, modely. Tyto modely potřebují historická data z případů, o kterých je známo, zda se jednalo či nejednalo o podvod. Poté je model použit ke skórování dalších případů. Výsledkem je předpověď, zda se jedná či nejedná o podvod a pravděpodobnost této předpovědi. Predikční modely se učí z historických dat a vědí, co mají předpovídat.
Třetím přístupem je detekce anomálií, kdy se využívají dataminingové algoritmy, které hledají skryté vztahy v datech na základě jejich podobnosti, aniž by předpovídaly podvodné chování subjektu. Chování subjektu není explicitně popsáno konkrétní hodnotou v datech. Zde hovoříme o tzv. nesupervizovaném modelování. Anomální subjekty jsou dobrým kandidátem pro důkladnější kontrolu.
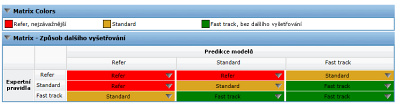
Klíčovým aspektem při detekci podvodů je využití maximální informace a znalosti, kterou máme k dispozici. Kombinace přístupů je podmíněna formalizací expertních pravidel a existencí nástroje, který tyto přístupy dokáže zkombinovat. Velice jednoduše se totiž může stát, že expertní pravidla a predikční modely dávají různé předpovědi, co se týká podezřelosti jednotlivých případů. V případě neshody předpovědí musíme určit, zda mají v rozhodování navrch expertní pravidla či predikční modely. Ukázka kombinace přístupů, a určení z ní plynoucí závažnosti, je barevně naznačena na obrázku. Akce plynoucí z doporučení jsou Refer, červená nejzávažnější, oranžová Standard a zelená Fast track bez dalšího vyšetřování případu.

Čím více podvodů, tím snadnější odhalení
Bylo řečeno, že úloha detekce podvodů obvykle mívá nejvyšší ROI z klasických dataminingových úloh. To však platí v případě menších podvodů. Menší podvodníci se sice snaží přijít stále s něčím novým a neotřelým, ale „naštěstí“ se úspěšné podvody brzy rozšíří, začnou napodobovat a brzy odhalí. Paradoxně je tedy největší devízou při odhalování podvodů jejich rostoucí počet. Toto bohužel neplatí v případě velkých organizovaných skupin, kdy je pro odhalení řádově menšího počtu, řádově finančně závažnějších podvodů, nutný individuální přístup.
Pokud by nebyly podvody, nebylo by co vyšetřovat. Když už ale podvody jsou, chceme dosáhnout toho, abychom prošetřili co největší objem těch nejpodezřelejších případů, pro jejichž prozkoumání máme dostatečné lidské kapacity. Odhadovaný objem šedé ekonomiky v České republice je přes 15% HDP, cca 600 miliard korun, čili stále je co odhalovat. Detekce fraudu není jednorázový proces, ale kontinuální činnost, kdy se soustavně hledají nové vzory podvodného chování a aktualizují se predikční modely. Je to soustavná snaha o to, nebýt za podvodníky pozadu o tři, čtyři kroky, ale pouze o jeden či dva.
 |
Ing. Libor Šlik Autor článku je certifikovaným analytikem a konzultantem pro data mining, sběr dat a jeho automatizace ve společnosti ACREA CR. |
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce
| 30.9. | Konference Světlo |