

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Hlavní partner sekce

Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

Business Intelligence , AI a Business Intelligence


Metody a procesy čištění dat
Ing. Jiří Bohuslav
Bouřlivý rozvoj informačních technologií způsobil, že systémy business intelligence již automaticky zaujímají své místo v podnikových systémech. Přesto se dá říci, že mnoho rozhodovacích procesů ještě není na těchto systémech založeno nebo informace, jež tyto systémy poskytují, nejsou zcela nebo správně využity.
Firmy téměř vždy uchovávají své informace v OLTP (on-line transaction processing) systémech, které zachycují jednotlivé detailní operace. OLTP systém však není vůbec vhodný pro zodpovězení určitých analytických dotazů (Jaké byly trendy prodeje našich výrobků v minulých pěti letech? Jaký je procentuální nárůst prodeje výrobků mezi dvěma kvartály?), velmi složitě lze získat agregovaná data, obsahuje spoustu dat, která pro kvalitní rozhodování vůbec nepotřebujeme, navíc OLTP systém není optimalizován pro složité uživatelské dotazy.
Oblast business intelligence je specifický obor, který je zaměřen převážně na poskytnutí komplexního pohledu na data koncovému uživateli a získání informací potřebných pro správné rozhodnutí. Základním krokem v procesu získání dat z provozních systémů pro kvalitní rozhodování je analýza, konsolidace a čištění zdrojových dat. Z existujících dat (např. o chování zákazníků, objemech prodeje v různých regionech) je třeba vytěžit maximum informací, jež mohou při správném využití poskytnout výraznou konkurenční výhodu.
Obvyklým řešením pro získání kvalitních konsolidovaných dat je vybudování datového skladu (data warehouse), datových tržišť (data mart), případně nadstavbových OLAP (on-line analytical processing) aplikací, neméně důležité je zvolení vhodné technologie pro prezentaci dat uživateli (reporting), která navíc umožní intuitivním způsobem analyzovat data ve vícerozměrné struktuře, sestavovat ad hoc dotazy. Datový sklad se tím pádem stane jedním velkým centralizovaným zdrojem informací pro celou firmu.
Pochopitelně je v zájmu firmy, aby data v datovém skladu byla všeobecně přijata jako „jedna verze pravdy“. Jde o to, že v datovém skladu se střetávají data z různých zdrojových systémů, ale i různá externí data, ručně udržované evidence a podobně. Přitom by měl být kladen velký důraz na zaručenou čistotu, tedy kvalitu dat. V datech přenášených do datového skladu se téměř vždy objevují duplicity a datové chyby, které není jednoduché odhalit. Tyto nepřesnosti způsobuje proměnlivé názvosloví („str. 56“/„stránka 56“), používání, či nepoužívání diakritiky („František Novák“/„Frantisek Novak“), pravopisné a jiné chyby, které způsobují nekonzistenci a je nutné je rozpoznat. Většinou neexistuje korekce chyb ve zdrojovém systému, proto je třeba nekonzistence dohledat, opravit a záznamy logicky spojit do jednoho při plnění datového skladu (ETL proces). Zajímavým postřehem je, že tento proces čištění dat při plnění datového skladu může pak zpětně sloužit jako opravná zpětná vazba pro zdrojový provozní informační systém. Udává se, že až 15 % všech zdrojových dat je nekonzistentních nebo nesprávných.
Zkusme si teď některé metody a procesy čištění dat popsat podrobněji:
Dále je třeba definovat vstupní atributy a roli, jakou údaje ve vstupních datech hrají. Role indikuje, jaký druh dat daný atribut reprezentuje. Rolí může být několik, od těch obecnějších, jako je osoba či adresa, až po konkrétnější, jako je křestní jméno, oslovení, město, země apod.
Posledním krokem je definice výstupních komponent. Každá komponenta reprezentuje konkrétní část jména nebo adresy, jako je oslovení, titul, standardizované křestní jméno, prostřední jména, jméno ulice, číslo domu apod., nebo obecnější entitu, jako adresu, jméno atd. Dále mohou být přidány výstupní komponenty reprezentující příznaky a chybové hlášky zpracování jednotlivých záznamů. Příznaky indikují, zda byl daný záznam, nebo jeho část, úspěšně analyzován a nalezen v databázi srovnávacího software. Tyto komponenty mohou sloužit k oddělení úspěšně zpracovaných záznamů od záznamů obsahujících chyby.
Prvním krokem při použití metody Match-Merge je definice porovnávacích pravidel. Pravidel může být více, záznamy jsou označeny jako identické, pokud splní jedno z následujících pravidel:
1. Porovnání založené na podmínce – například:
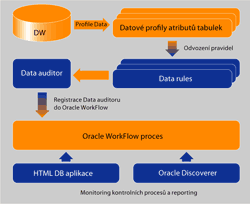
Obr. 1: Postup při řešení data profilingu pomocí nástrojů Oracle
Transformace dat zajišťující čištění atributů se v některých případech nedají dostatečně jednoduše zobecnit, proto se v případě, že žádnou z uvedených metod a nástrojů nelze použít, neobejdeme bez psaní vlastních transformací. Pro řešení složitějších situací, kdy je potřeba při čištění dat využívat robustnějších metod, existuje řada dalších, cenově samozřejmě mnohem náročnějších, specializovaných produktů (např. Trillium Software od společnosti Harte-Hanks, SAS Data Quality Solution, Firstlogic – součást Business Objects, Melissa Data).
Autor působí ve společnosti Sophia Solutions.
Firmy téměř vždy uchovávají své informace v OLTP (on-line transaction processing) systémech, které zachycují jednotlivé detailní operace. OLTP systém však není vůbec vhodný pro zodpovězení určitých analytických dotazů (Jaké byly trendy prodeje našich výrobků v minulých pěti letech? Jaký je procentuální nárůst prodeje výrobků mezi dvěma kvartály?), velmi složitě lze získat agregovaná data, obsahuje spoustu dat, která pro kvalitní rozhodování vůbec nepotřebujeme, navíc OLTP systém není optimalizován pro složité uživatelské dotazy.
Oblast business intelligence je specifický obor, který je zaměřen převážně na poskytnutí komplexního pohledu na data koncovému uživateli a získání informací potřebných pro správné rozhodnutí. Základním krokem v procesu získání dat z provozních systémů pro kvalitní rozhodování je analýza, konsolidace a čištění zdrojových dat. Z existujících dat (např. o chování zákazníků, objemech prodeje v různých regionech) je třeba vytěžit maximum informací, jež mohou při správném využití poskytnout výraznou konkurenční výhodu.
Obvyklým řešením pro získání kvalitních konsolidovaných dat je vybudování datového skladu (data warehouse), datových tržišť (data mart), případně nadstavbových OLAP (on-line analytical processing) aplikací, neméně důležité je zvolení vhodné technologie pro prezentaci dat uživateli (reporting), která navíc umožní intuitivním způsobem analyzovat data ve vícerozměrné struktuře, sestavovat ad hoc dotazy. Datový sklad se tím pádem stane jedním velkým centralizovaným zdrojem informací pro celou firmu.
Pochopitelně je v zájmu firmy, aby data v datovém skladu byla všeobecně přijata jako „jedna verze pravdy“. Jde o to, že v datovém skladu se střetávají data z různých zdrojových systémů, ale i různá externí data, ručně udržované evidence a podobně. Přitom by měl být kladen velký důraz na zaručenou čistotu, tedy kvalitu dat. V datech přenášených do datového skladu se téměř vždy objevují duplicity a datové chyby, které není jednoduché odhalit. Tyto nepřesnosti způsobuje proměnlivé názvosloví („str. 56“/„stránka 56“), používání, či nepoužívání diakritiky („František Novák“/„Frantisek Novak“), pravopisné a jiné chyby, které způsobují nekonzistenci a je nutné je rozpoznat. Většinou neexistuje korekce chyb ve zdrojovém systému, proto je třeba nekonzistence dohledat, opravit a záznamy logicky spojit do jednoho při plnění datového skladu (ETL proces). Zajímavým postřehem je, že tento proces čištění dat při plnění datového skladu může pak zpětně sloužit jako opravná zpětná vazba pro zdrojový provozní informační systém. Udává se, že až 15 % všech zdrojových dat je nekonzistentních nebo nesprávných.
Zkusme si teď některé metody a procesy čištění dat popsat podrobněji:
Name-Address Cleansing
Umožňuje čištění jmen a adres ve zdrojových datech. Nalézá a opravuje chyby a nekonzistence porovnáváním vstupních dat s knihovnami dat často dodávaných třetí stranou. Chyby a nekonzistence ve vstupních datech jsou eliminovány:- analýzou a rozdělením jmen a adres vstupních dat na jednotlivé části,
- převedením jmen a adres na standardní formát podle konvencí dané země,
- doplněním jmen a adres o další údaje, jako je pohlaví, kód státu, obchodní nebo geografické informace apod.
Dále je třeba definovat vstupní atributy a roli, jakou údaje ve vstupních datech hrají. Role indikuje, jaký druh dat daný atribut reprezentuje. Rolí může být několik, od těch obecnějších, jako je osoba či adresa, až po konkrétnější, jako je křestní jméno, oslovení, město, země apod.
Posledním krokem je definice výstupních komponent. Každá komponenta reprezentuje konkrétní část jména nebo adresy, jako je oslovení, titul, standardizované křestní jméno, prostřední jména, jméno ulice, číslo domu apod., nebo obecnější entitu, jako adresu, jméno atd. Dále mohou být přidány výstupní komponenty reprezentující příznaky a chybové hlášky zpracování jednotlivých záznamů. Příznaky indikují, zda byl daný záznam, nebo jeho část, úspěšně analyzován a nalezen v databázi srovnávacího software. Tyto komponenty mohou sloužit k oddělení úspěšně zpracovaných záznamů od záznamů obsahujících chyby.
Match-Merge
Pomocí této metody se na základě předem definovaných pravidel dají určit záznamy, které reprezentují stejná data, a podle dalších pravidel se tyto záznamy dají sloučit do jediného (obr. 1). Tato metoda spolu s metodou Name-Address poskytuje nástroj pro jednoznačnou identifikaci kontaktních informací o zákaznících.Prvním krokem při použití metody Match-Merge je definice porovnávacích pravidel. Pravidel může být více, záznamy jsou označeny jako identické, pokud splní jedno z následujících pravidel:
1. Porovnání založené na podmínce – například:
- přesná shoda – záznamy musí být identické,
- standardizovaná přesná shoda – záznamy musí být identické, ignorují se malá/velká písmena, mezery a nealfanumerické znaky,
- podobnost – lze specifikovat procentuální hodnotu podobnosti, kterou musí záznamy splňovat, aby byly označeny za identické,
- standardizovaná podobnost,
- částečný název – jeden záznam se vyskytuje jako podřetězec ve druhém záznamu počínaje prvním slovem,
- detekce zkratek a akronym.
- srovnání iniciál se jmény, kdy se za identické považují záznamy jako „P.“ a „Petr“,
- srovnání podřetězců se jmény, za identické se považují například záznamy „Rob“ a „Robert“,
- podobnost – lze specifikovat procentuální hodnotu podobnosti, kterou musí záznamy splňovat, aby byly označeny za identické,
- detekce složených jmen,
- srovnání oslovení vůči křestnímu jménu a příjmení – například „p. Novák“ a „Martin Novák“,
- detekce chybějících spojovníků,
- detekce přehozeného křestního jména a příjmení.
| Row | FirstName | LastName | SSN | Address | Unit | Zip |
|---|---|---|---|---|---|---|
| 1 | Jane | Doe | NULL | 123 MainStreet | NULL | 22222 |
| 2 | Jane | Doe | 111111111 | NULL | NULL | 22222 |
| 3 | J. | Doe | NULL | 123 MainStreet | Apt 4 | 22222 |
| 4 | NULL | Smith | 111111111 | 123 MainStreet | Apt 4 | 22222 |
| 5 | Jane | Smith-Doe | 111111111 | NULL | NULL | 22222 |
| Row | FirstName | LastName | SSN | Address | Unit | Zip |
|---|---|---|---|---|---|---|
| 1 | Jane | Doe | 111111111 | 123 MainStreet | Apt 4 | 22222 |
Data Profiling
Metoda, která umožňuje zkoumat data z hlediska struktury, identifikovat anomálie, provádět analýzu atributů, referenční analýzu, případně tzv. custom analýzu, kde si pravidla definuje sám uživatel. Řešení profilace a čištění dat je realizováno v následující posloupnosti kroků:- definice zdrojových dat – tabulek,
- spuštění procesu profilace dat,
- na základě analýzy zdrojových dat je třeba navrhnout pravidla pro jednotlivé atributy (data rule),
- tato pravidla lze převést na tzv. korekce,
- korekce je třeba aplikovat na vstupní data/atributy,
- pro ETL proces lze nastavit strategii pro čištění dat, jako například remove (data, která nesplňují pravidla se nepřenesou dále, jsou odstraněna), match (očištění dat na základě nejbližší shody hodnoty atributů – odstranění překlepů, velká/malá písmena apod.) nebo custom (libovolná vlastní logika čištění dat).
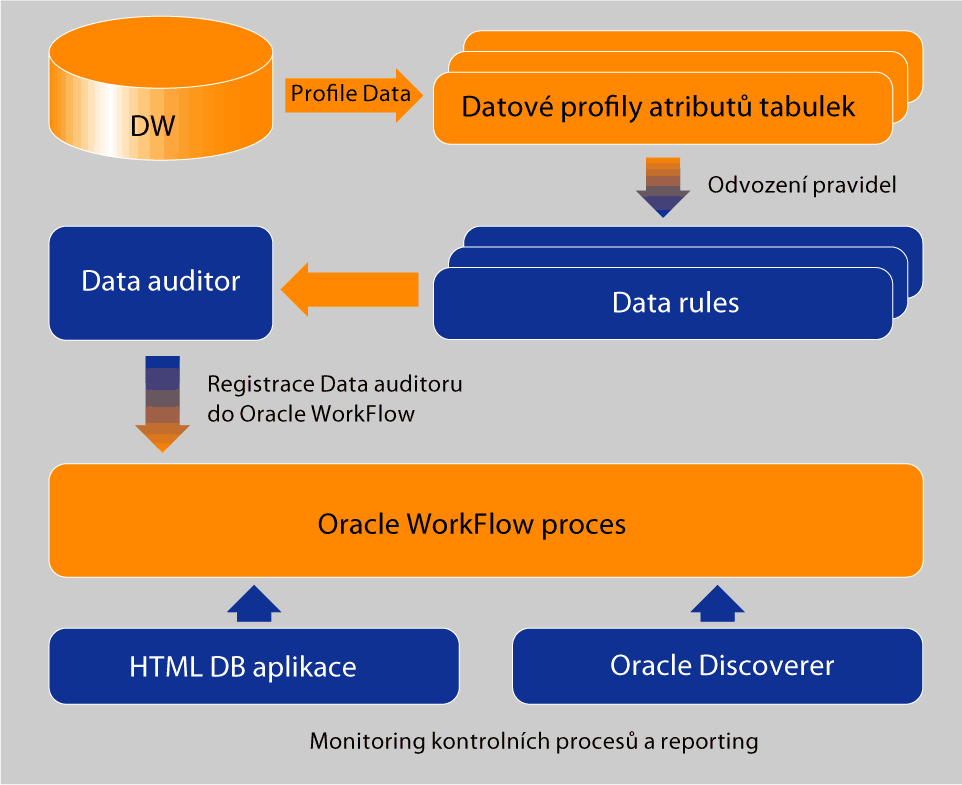
Obr. 1: Postup při řešení data profilingu pomocí nástrojů Oracle
Transformace dat zajišťující čištění atributů se v některých případech nedají dostatečně jednoduše zobecnit, proto se v případě, že žádnou z uvedených metod a nástrojů nelze použít, neobejdeme bez psaní vlastních transformací. Pro řešení složitějších situací, kdy je potřeba při čištění dat využívat robustnějších metod, existuje řada dalších, cenově samozřejmě mnohem náročnějších, specializovaných produktů (např. Trillium Software od společnosti Harte-Hanks, SAS Data Quality Solution, Firstlogic – součást Business Objects, Melissa Data).
Autor působí ve společnosti Sophia Solutions.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce