

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Hlavní partner sekce

Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEMS 5/2007 , AI a Business Intelligence
 Pokud jste na konferenci nebo v odborném časopise zahlédli magické spojení slov business a intelligence, pak byl s velkou pravděpodobností někde v pozadí nebo pod nadpisem zmíněn i další odborný termín: datový sklad. Pokud chcete dát vašemu byznysu inteligenci, potřebujete tedy nutně datový sklad? Pojďme si vysvětlit jednotlivé odborné termíny a přístupy k technologickému řešení.
Pokud jste na konferenci nebo v odborném časopise zahlédli magické spojení slov business a intelligence, pak byl s velkou pravděpodobností někde v pozadí nebo pod nadpisem zmíněn i další odborný termín: datový sklad. Pokud chcete dát vašemu byznysu inteligenci, potřebujete tedy nutně datový sklad? Pojďme si vysvětlit jednotlivé odborné termíny a přístupy k technologickému řešení.


Co si pod pojmem business intelligence (BI) přesně představit? Existuje odborná definice: souhrnný pojem pro procesy, technologie a nástroje potřebné k přetvoření dat do informací, informací do znalostí a znalostí do plánů, které umožní provést akce podporující splnění primárních cílů organizace. Stejně tak existuje několik zjednodušených interpretací. Asi ta nejpovedenější z našeho pohledu zní: business intelligence jsou nástroje a úkony vedoucí k získání informací z ukládaných dat, které pak slouží pro operativní i strategická rozhodování. Ještě jednodušeji by se dalo říci, že ukládat data umí dnes jakýkoliv informační systém, ale vytáhnout z něj relevantní informace vztahující se k aktuální potřebě rozhodnutí, na to již potřebuji pokročilejší inteligenci.
Praktické příklady o uplatnění business intelligence ovšem vypovídají úplně nejlépe: potřebuji vědět, kterým klientům mohu nabídnout po telefonu úvěrovou kartu, u kterých klientů je vysoké riziko odchodu ke konkurenci, potřebuji znát vývoj tržeb za posledních třicet dní v členění dle regionů a produktů či jak se liší skutečný výkon společnosti od plánovaného. Mít informace také znamená možnost seznámit se prostřednictvím jednoho kliknutí myší s detailním profilem každého klienta, který se dovolá na call centrum. Získat cennou informaci však není až tak triviální, jak se může zdát.
Získat agregovanou informaci pro zlepšení byznysu tak v první fázi znamená převést data do vhodných struktur – datového skladu (data warehouse, DWH). Data warehouse není nic jiného než databáze obsahující konsolidovaná data ze všech dostupných provozních systémů a optimalizovaná nikoli pro rychlé zpracování transakcí, nýbrž pro reporting, analýzu a archivaci dat.
Pro práci není potřeba hluboká znalost technologií, sestavení je otázka několika kliků, případně výběru informací nabízených průvodci. Po stažení nástroje a nainstalování přibude další pás karet, který je třeba dále nastavit. Konfigurace spočívá v připojení na analytické služby SQL Serveru 2005 (podle edice SQL se odvíjí i možnosti a funkcionalita).

A pak už se můžeme vrhnout do práce. Nástroje pro dolování dat nabízejí:
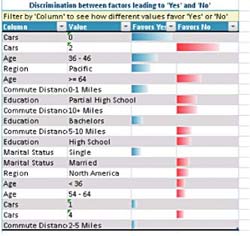
Další příjemnou možností je nalezení podobných skupin v datech (do kategorií sloučí řádky s podobnou charakteristikou), nebo kvalitní what-if analýzy nad velkým množstvím dat.
Dolování dat v Excelu 2007 nabízí prostředky analytických služeb SQL Serveru 2005 do prostředí Excel 2007. Umožňuje práci se sofistikovanými algoritmy, strukturami a pohledy, které jsou součástí databázového stroje (který provádí většinu práce), kde zdrojem dat je tabulka Excel 2007. Tyto možnosti jistě ocení nejen datoví analytici, ale určitě najdou oblibu i mezi pokročilejšími uživateli, kteří potřebují z dat získat další, na první pohled neviditelné informace.
Podle čeho tedy vybrat? Uveďme si několik hledisek, jak pohlížet na databázi s perspektivou BI platformy:
Oba autoři působí ve společnosti Microsoft. Michal Hroch jako produktový manažer divize Server Platform, Pavel Cach je softwarovým architektem pro velké zákazníky.
Business intelligence staví na datovém skladu
Michal Hroch, Pavel Cach
Pokud jste na konferenci nebo v odborném časopise zahlédli magické spojení slov business a intelligence, pak byl s velkou pravděpodobností někde v pozadí nebo pod nadpisem zmíněn i další odborný termín: datový sklad. Pokud chcete dát vašemu byznysu inteligenci, potřebujete tedy nutně datový sklad? Pojďme si vysvětlit jednotlivé odborné termíny a přístupy k technologickému řešení. Co si pod pojmem business intelligence (BI) přesně představit? Existuje odborná definice: souhrnný pojem pro procesy, technologie a nástroje potřebné k přetvoření dat do informací, informací do znalostí a znalostí do plánů, které umožní provést akce podporující splnění primárních cílů organizace. Stejně tak existuje několik zjednodušených interpretací. Asi ta nejpovedenější z našeho pohledu zní: business intelligence jsou nástroje a úkony vedoucí k získání informací z ukládaných dat, které pak slouží pro operativní i strategická rozhodování. Ještě jednodušeji by se dalo říci, že ukládat data umí dnes jakýkoliv informační systém, ale vytáhnout z něj relevantní informace vztahující se k aktuální potřebě rozhodnutí, na to již potřebuji pokročilejší inteligenci.
Praktické příklady o uplatnění business intelligence ovšem vypovídají úplně nejlépe: potřebuji vědět, kterým klientům mohu nabídnout po telefonu úvěrovou kartu, u kterých klientů je vysoké riziko odchodu ke konkurenci, potřebuji znát vývoj tržeb za posledních třicet dní v členění dle regionů a produktů či jak se liší skutečný výkon společnosti od plánovaného. Mít informace také znamená možnost seznámit se prostřednictvím jednoho kliknutí myší s detailním profilem každého klienta, který se dovolá na call centrum. Získat cennou informaci však není až tak triviální, jak se může zdát.
Datový sklad je základ pro BI
K hlavnímu zdroji informací patří jednak systémy přímo určené pro provoz firmy (ERP, SCM, CRM), jednak externí databáze (např. číselníky adres, obcí, telefonní seznamy, registry ekonomických subjektů, databáze neplatičů apod.). Tyto „generátory“ dat však většinou nejsou schopny požadovanou informaci uživatelům poskytnout, a to hned z několika důvodů. Rozšiřování o nové produkty, zavádění nových systémů, fúze a akvizice společností vedou k tomu, že data jsou uložena na mnoha místech, platformách a odlišných strukturách i formátech. Dalším problémem je kvalita těchto dat. Data na pobočkách či call centrech se pořizují ve stresu, a tedy nejsou úplná, obsahují chyby, překlepy či neplatné hodnoty. Provozní systémy, které tvoří hlavní zdroj dat jsou navíc natolik vytížené, že nějaké složité analýzy zde ani nepřipadají v úvahu. Ale i kdyby to možné bylo, data většinou nejsou uložena ve strukturách vhodných pro analýzy a obsahují často pouze aktuální stav bez historie. Primární systémy mají jediný cíl – zajistit operativu fungování firmy.Získat agregovanou informaci pro zlepšení byznysu tak v první fázi znamená převést data do vhodných struktur – datového skladu (data warehouse, DWH). Data warehouse není nic jiného než databáze obsahující konsolidovaná data ze všech dostupných provozních systémů a optimalizovaná nikoli pro rychlé zpracování transakcí, nýbrž pro reporting, analýzu a archivaci dat.
Data mining v Excelu?
Novinkou v globální rovině jsou business intelligence nástroje integrované do Excelu 2007. Částečně zavádějící název „data mining addins“ (nástroje pro dolování dat) napovídá o spojení s data miningem, nicméně tak tomu úplně není. Součástí tohoto volně stažitelného pluginu jsou mimo dolování dat například i nástroje pro datovou analýzu, modelování, předpovědi, případně i šablony do aplikace Microsoft Visio. Tyto nástroje ocení všichni, kdo hledají závislosti a trendy v rozsáhlých datech (Excel 2007 již podporuje milion řádků) a potřebují vytvářet kvalitní grafické výstupy. Umožňují analyzovat korelace a sestavovat předpovědi, jak s využitím dat přímo v Excelu 2007, tak i s využitím modelů uložených v analytických službách SQL Serveru 2005.Pro práci není potřeba hluboká znalost technologií, sestavení je otázka několika kliků, případně výběru informací nabízených průvodci. Po stažení nástroje a nainstalování přibude další pás karet, který je třeba dále nastavit. Konfigurace spočívá v připojení na analytické služby SQL Serveru 2005 (podle edice SQL se odvíjí i možnosti a funkcionalita).

- Panel nástrojů pro přípravu dat umožňuje odhalit extrémy a zobrazit rozdělení dat, vyčistit data podle daného klíče (například nekompletní hodnoty), případně změnit hodnoty pro snadnější analýzu nebo připravit datové podklady pro následné zpracování.
- Další panel nástrojů umožňuje vytvoření různých datových modelů (závislosti dat v jednom sloupci na základě informací ve sloupcích ostatních, předpověď číselných dat, shlukovací a asociační model), vytváření předpovědí na základě předchozích trendů a zobrazení do grafů, případně sestavení složitějšího modelu s využitím MDX skriptů.
- Pokud je již model sestavený, nabízí se možnost zjistit jeho kvalitu (a to jak v tabulkovém, případně grafickém zobrazení).
- Další možností je správa modelů v SQL Serveru 2005 nebo sestavování dotazů (od jednoduchých průvodců až po složitější MDX skripty).
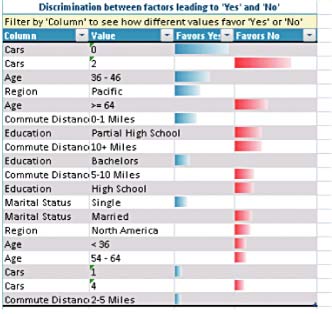
Další příjemnou možností je nalezení podobných skupin v datech (do kategorií sloučí řádky s podobnou charakteristikou), nebo kvalitní what-if analýzy nad velkým množstvím dat.
Dolování dat v Excelu 2007 nabízí prostředky analytických služeb SQL Serveru 2005 do prostředí Excel 2007. Umožňuje práci se sofistikovanými algoritmy, strukturami a pohledy, které jsou součástí databázového stroje (který provádí většinu práce), kde zdrojem dat je tabulka Excel 2007. Tyto možnosti jistě ocení nejen datoví analytici, ale určitě najdou oblibu i mezi pokročilejšími uživateli, kteří potřebují z dat získat další, na první pohled neviditelné informace.
Databáze pro BI
Pokud se firma rozhodne pro centralizovaně koncipované BI řešení, prvním krokem je volba databázové platformy. Ta se volí podle několika kritérií, ovšem ten úplně nejzákladnější filtr by měl být nastaven. Pokud chcete databázi pro inteligentní řešení, i samotná databáze by nějakou svou intelegenci měla mít. Jinými slovy, nepořizujte si databázi, která vám umožní data pouze ukládat, pokud jdou vaše cíle dále a chcete s daty pracovat.Podle čeho tedy vybrat? Uveďme si několik hledisek, jak pohlížet na databázi s perspektivou BI platformy:
- Vše v jednom pro BI – v ideálním případě najděte databázi, která bude zároveň efektivním nástrojem pro datovou transformaci v heterogenních prostředích, plnohodnotným analytickým serverem poskytujícím i služby data miningu, nástrojem zajišťujícím celý životní cyklus report.
- Analytické služby databáze – databáze by měla pracovat s jediným nedělitelným modelem pro relační a multidimenzionální databázi, který zaručí vždy pravdivé odpovědi. Zároveň musí umět pracovat s nastavením pravidel pro KPI (key performance indicator). Důležitá je podpora real-time BI – všechny změny v primárních systémech jsou okamžitě zohledněny ve všech reportech a analýzách.
- Reporting – pokud jsme mluvili o podpoře celého životního cyklu reportu, pak se počítá jeho návrh, definice pravidel, komu, kdy a jakou formou a výsledná distribuce reportu. Řešení reportingu musí být připraveno pro nejnáročnější zákazníky s velkými počty současných přístupů k reportům.
- Data odkudkoliv, tj. integrace – databáze musí být platformou pro budování vysoce dostupných řešení pro datovou integraci, workflow a pro extrakci, transformaci a loading (ETL) dat do datových skladů. Součástí pokročilých platforem jsou připravené funkce pro transformaci dat z nejrůznějších datových zdrojů.
- Bezpečnost a dostupnost dat – data v analýzách bývají často to nejryzejší zlato firmy a jejich ztráta by mohla výrazně ovlivnit další existenci takového podniku. Proto je třeba dbát na samotnou spolehlivost DB platforem. Například uložení dat na více oddělených serverech zaručí dostupnost i při úplné zkáze, potom ale obnovení dat musí probíhat za plného provozu, bez nutnosti výpadků. Identifikace a autorizace uživatelů by měly splňovat nejvyšší požadavky na zabezpečení, pomoci proti zneužití může i šifrování databázových souborů.
- Plně kompatibilní s dalšími celky – můžete vyvinout sebelepší analytickou platformu, pokud však celé řešení a vlastní informace nezpřístupníte relevantním lidem, vaše práce byla zbytečná. Vámi zvolená databáze by tedy měla umožňovat integraci informací do běžného kancelářského prostředí nebo běžného internetového okna v rámci firemního intranetu. Zde platí, že čím jednodušší prostředek pro interpretaci informací to bude, tím úspěšněji bude řešení BI jako celek přijato.
Extrakce, transformace, nalití. Jak jednoduché...
Jak již bylo řečeno v popisu ideální databáze, k převodu dat do datového skladu se využívají ETL (extraction, transformation, loading) nástroje. Při popisu ETL začněme opět oficiální definicí: převod dat ze zdrojových datových struktur do cílových struktur datového repository. Existují dva základní typy procesů datové transformace – ETL a ELT. Prvním krokem je vždy extrakce dat ze zdrojových systémů. Úkolem ETL nástroje je vytáhnout v co nejkratší době – většinou bez jakýchkoli úprav – potřebná data ze zdrojových systémů (extraction) a uložit je do úložiště. Pak následuje fáze transformací (transformation), během které dochází k nejpodstatnější části celého řešení – k čištění dat (doplnění chybějících hodnot, odstranění překlepů, převedení na shodné formáty, napárování na jednotné číselníky/dimenze), datové konsolidaci (unifikaci hlavních entit – zákazníci, zaměstnanci, dodavatelé, partneři, produkty apod.) a výpočtu agregací dle hlavních entit. K čištění se používají inteligentní nástroje obsahující typické vzorky nečistot a často napojené na externí číselníky jmen, adres, titulů atp. Teprve takto připravená data můžeme nahrát do centrálního úložiště datového skladu (loading). Tam by již data měla být čistá, úplná, konzistentní, historizovaná, konsolidovaná.Analyzujte
Nejčastěji používaným pojmem v souvislosti s nástroji, jejichž hlavním účelem je pomoci uživatelům s rozborem existujících dat, jsou OLAP nástroje. Ty umožňují ad-hoc analýzy s přijatelnou rychlostí a dostatečně malým omezením rozsahu možných datových rozborů. Data pro účel analýzy musí být bezpodmínečně čistá a konsolidovaná. Technologie OLAP dává možnost prohlížet údaje o nákupech, prodejích apod. v rozpadu podle libovolné dimenze či kombinací více dimenzí (čas a produkt) a na libovolném stupni agregace (např. stát/region/okres/město/pobočka), a to v reálném čase bez nutnosti čekat na zdlouhavé procházení celé historie datového skladu. Tímto dostáváme do rukou výkonný analytický (a rovněž i reportovací) nástroj oblíbený zejména u manažerů. OLAP může být řešen tradiční cestou prostřednictvím klasických relačních databázových tabulek (tzv. ROLAP, relational OLAP), anebo s využitím technologie vícerozměrných datových krychlí (tzv. MOLAP, multidimensional OLAP), popřípadě kombinací obou (tzv. HOLAP, hybrid OLAP).Data mining pro pokročilé analýzy dat
Složitější vzorky chování, které již nejsme schopni prostřednictvím technologie OLAP detekovat, řešíme prostřednictvím technologií data miningu. Data mining se využívá zejména pro predikci (např. odhad budoucího chování klientů, tržeb, pohledávek), segmentaci (shlukování klientů s podobnými vlastnostmi) či pro popis dat. Mezi nejčastěji používané algoritmy predikce patří logistická či lineární regrese, metoda rozhodovacích stromů, neuronové sítě či v poslední době populární support vector machines. Ze shlukovacích algoritmů jsou to pak K-Means a EM clustering.Oba autoři působí ve společnosti Microsoft. Michal Hroch jako produktový manažer divize Server Platform, Pavel Cach je softwarovým architektem pro velké zákazníky.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce