

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Hlavní partner sekce

Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce

| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEMS 11/2014 , AI a Business Intelligence



Architektura Microsoft APS – Analytics Platform System

Architektura SAP HANA

Referenční architektura Oracle

Big Data architektura IBM

Teradata – Hadoop a datový sklad
Big data: Od velkých očekávání k praktickému využití
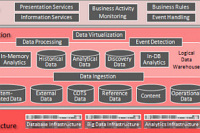 Růst zájmu o big data můžeme vysledovat zpět do let 2011-2012. Je spojen s nárůstem uživatelů sociálních sítí jako Facebook a Twitter a určitým přelomem ve změně jejich využívání. Zatímco před tímto obdobím byly velké sociální sítě používány spíše jednotlivci ke komunikaci mezi skupinami osob, nejčastěji mezi známými a přáteli, po roce 2010 dochází k velkému rozšíření firemní komunikace skrze tato media.
Růst zájmu o big data můžeme vysledovat zpět do let 2011-2012. Je spojen s nárůstem uživatelů sociálních sítí jako Facebook a Twitter a určitým přelomem ve změně jejich využívání. Zatímco před tímto obdobím byly velké sociální sítě používány spíše jednotlivci ke komunikaci mezi skupinami osob, nejčastěji mezi známými a přáteli, po roce 2010 dochází k velkému rozšíření firemní komunikace skrze tato media.
S rozvojem sociálních sítích se marketingové útvary začaly potýkat s problémy, jak zde vyhodnocovat a měřit přínosy kampaní a dalších marketingových aktivit. V tomto období tak dochází ke zvýšenému zájmu o technologie, které umožňují pracovat s nestrukturovanými a rychle se měnícími daty z těchto nových médií. Navíc je těchto dat, stejně jako uživatelů a aktivit na sociálních sítích, opravdu hodně a rodí se termín „big data“.
Pokud se podíváme na pravidelně aktualizované údaje zralosti jednotlivých technologií podle hodnocení analytické firmy Gartner, zjistíme, že technologie pro práci s velkými daty teprve v roce 2014 překonala vrchol „hype cyklu“ a začíná se dostávat do fáze, kdy dojde na jedné straně k vystřízlivění, ale také k nárůstu počtu reálných a prakticky využitelných aplikací a projektů, které budou s těmito daty pracovat.
Inflace velkých dat
Je třeba konstatovat, že v současné době dochází k nadměrnému používání tohoto termínu. Velké množství firem a projektů, pokud pracuje jen s trochu větším objemem dat, o sobě začíná prohlašovat, že pracuje v oblasti big data. Realita je ale daleko prozaičtější. Pouze velké množství údajů ještě big data projekt nedělá. Pokud máme data jasně popsaná, strukturovaná a definovaná, tak bychom správně neměli projekty mezi ty „velké“ řadit. Celá řada projektů, na kterých pracují například telekomunikační operátoři nebo banky, tak do kategorie velkých dat nespadá. Operátoři již po desetiletí zpracovávají obrovské objemy dat o telefonních hovorech, nově k tomu přidávají například anonymizované informace o pohybu mobilních telefonů. Nicméně zde se typicky jedná o velmi dobře popsanou a stálou množinu údajů, kterých je sice opravdu hodně a jejich zpracovávání je z mnoha hledisek náročné (rychlost, objem, požadavky na bezpečnost a anonymnost), ale o big data projekty se nejedná. Je prostě jen „in“ o projektu jako o projektu na big data hovořit, protože je to žádané, trendy, a někdy to může ve firmě pomoci k prosazení rozpočtu.
Je třeba také říci, že celá řada firem si již prošla určitým vystřízlivěním. Existovala populární představa marketingových oddělení, že když budeme detailně analyzovat názory, chování a komentáře zákazníků na sociálních sítích a internetu obecně, dostaneme návod, co přesně zákazníci chtějí a budou kupovat. Realita ale toto očekávání (alespoň prozatím) nenaplnila.
Kdy tedy velká data využít?
O big datech bychom měli hovořit, pokud například chceme analyzovat pohyb mobilních telefonů po silnicích a v případě vytvoření dopravní zácpy budeme v reálném čase hledat odpověď na to, o jakých tématech si lidé v této situaci vyměňují informace na sociálních sítích. S velkými daty pracujeme tedy dle definice v těch případech, pokud se jedná o data nestrukturovaná, obtížně definovatelná a rychle se měnící v čase. Jaké jsou v současnosti nejčastější big data projekty? Typicky se jedná o:
- Analýzy sociálních sítí a dopad na preferenci nákupů jednotlivých značek,
- práci s daty při sportovních utkáních, od Formule 1 po golf či tenis,
- identifikaci chování vedoucí ke změně operátora – od aktivity na sociálních sítích přes data o provozu,
- práce s hovory na různé helpdesky, analýza textů, hledání trendů a naopak propojování informací o potřebách uživatelů z různých prodejních kanálů – poboček, call center, webových stránek firmy.
Výčet určitě není úplný. Spíše jde o ilustraci témat, se kterými se v současnosti setkáváme nejčastěji. Je patrné, že se jedná o projekty velkých firem. To je spojeno i s aktuálními nároky na technologii potřebnou ke zpracování takových objemů a typů dat. Pokud se totiž neomezíme jen na pokusy a malé vzorky a chceme pracovat s celou zákaznickou bází, je architektura potřebná k těmto úkolům finančně dost náročná. Nicméně lze očekávat, že se v dalších letech tyto technologie stanou více dostupné i pro menší firmy.
Jak na to jdou velcí výrobci?
Nástrojem pro práci s velkými daty se postupem času stal Hadoop a jeho různé formy. Nespornou výhodou je, že pro různé menší projekty nebo testování můžeme využít open sourcové verze a distribuce a alespoň začít s malými náklady.
Určitou nevýhodou takového přístupu bude, že vytvoříme oblast, která bude zcela jiná, než ostatní strukturovaná data ve firmě. V posledních letech proto vidíme snahu velkých výrobců propojovat světy nestrukturovaných a strukturovaných dat a vytvořit univerzální architekturu, která by vyhovovala oběma částem a současně splňovala vysoké nároky na dostupnost a rychlost zpracování dat. Microsoft tak například uvedl na trh platformu APS, která spojuje právě Hadoop a SQL Parallel Data Warehouse. V konečném důsledku tedy umožňuje pracovat a analyzovat výstupy z práce s nestrukturovanými daty stejnými nástroji, jaké používáme pro dobře známý SQL server.

Architektura Microsoft APS – Analytics Platform System
Proti tomuto staví SAP důraz na zpracování všech typů dat v reálném čase a představuje platformu SAP HANA, která podporuje práci s různými zdroji dat a aplikacemi a umožňuje uživateli, aby zpracované informace i dále předal dalším aplikačním serverům.

Architektura SAP HANA
Když se podíváme na referenční architekturu dalšího velkého výrobce, Oracle, tak zjistíme, že je o něco obecnější, ale představuje velmi podobný princip jako předchozí dva – sjednocovat big data a databáze do takové architektury, která umožní jednotný pohled, analýzu a reporting výstupů z takto zpracovávaných datových zdrojů.

Referenční architektura Oracle
Velmi podobný přístup jako SAP publikuje firma IBM v architektuře Watson Foundations. I zde se strukturovaná a nestrukturovaná data slučují do jednotné architektury, IBM navíc přidává funkce prediktivní analýzy. Právě forecasting a modelování budoucích scénářů se stává předmětem soupeření a zaměřuje se na něj pozornost zákazníků.

Big Data architektura IBM
Poněkud upravený přístup vidíme na konceptu Teradata. Zde jsou nestrukturovaná data také zpracovávána prostřednictvím technologie Hadoop a pomocí vazby do datového skladu. Dosahujeme tím stejné výhody jako v předchozích případech, tedy nasazení stejných business intelligence nástrojů na oba typy dat. Navíc je zde možnost práce s externími developery, kterou hadoop umožňuje a jeho volnější začlenění do konceptu Teradata tuto spolupráci může ulehčovat.

Teradata – Hadoop a datový sklad
Nástroje existují. Potřebujete je?
Na těchto příkladech vidíme, že pro projekty s velkými daty existují platformy, které jsou komerčně aplikovatelné. Pro některé uživatele bude limitujícím faktorem cena a pak bude na místě zamyslet se nad cílem projektu a nad tím, jestli by nebylo možné obdobného nebo velmi podobného výsledku dosáhnout aplikací tradičnějších metod zpracovávání dat. Podle našich zkušeností se často původní big data projekt při střetu s realitou změní v práci s velkými objemy dat tradičními metodami. Ale to v žádném případě nemusí být na škodu. Dnešní IT prostředí ve firmách je pod stále větším tlakem dodávat výsledky rychle a levně. Pokud najdeme cestu, jak takové výsledky dodat pomocí často již existující architektury a známých nástrojů, tak můžeme významných úspor dosáhnout. A získat tak čas do doby, než se robustní nástroje pro big data projekty stanou finančně dostupnějšími. A to by při naplnění očekávání analýzy firmy Gartner mělo nastat v horizontu přibližně příštích pěti let.
 |
Petr Skokan Autor působí jako obchodní ředitel společnosti Intelligent Technologies. |
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 1 | 2 | 3 | 4 | 5 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce
| 26.6. | https://kybeon.moyazone.cz/konzultacni-hodiny/iso-certifikace-prakticky/... |
