


- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (36)
- WMS (29)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce

| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEMS 3/2005

Metadata a datové sklady
S metadaty je to jako s metafyzikou. Filozofové tento termín používají také velmi volně. Obvykle ve významu lidského tázání do oblastí, které leží za hranicí fyziky – v původním významu přírody (řecká předpona „meta“ znamená „za“). Historka, která se váže ke vzniku tohoto slova, je příznačná. Prý to bylo tak, že když se Aristotelovy spisy o první filozofii dávaly do knihovny, Andronikos Rhodský je zařadil do police za knihy o přírodě (meta ta fysika).


S metadaty v organizacích je to podobně. Poprvé se s tímhle slovem setkáte ve chvílích, kdy je třeba o datech něco zjistit, a ono to nějak nejde. Například ve velké organizaci chcete zavést novou verzi staršího systému. Aplikaci před pěti lety napsal velmi šikovný programátor. Od té doby funguje skvěle. Jenže... kolega programátor už v té organizaci rok nepracuje. Psaní technické dokumentace ho moc nebavilo. Vlastně se ani moc neví, kdo aplikaci přesně využívá a jaká jsou její rozhraní k jiným systémům. V takové situaci začne pátrání hodné kvalit Sherlocka Holmese: Kde jenom je ta dokumentace? Máme nějaký datový model? Jací uživatelé a kdy systém používají? Jaké další systémy si berou z této aplikace data? Nejobvyklejší popis toho, co znamená slovo metadata, je: jsou to data o datech. Podobně jako s metafyzikou - nejdřív máme data, a pak o nich nějak mluvíme. Jsou to například informace o názvech sloupců v tabulkách a datových typech. V relačních databázích existuje celá řada způsobů, jak se k takovým informacím dostat. Mohou to být systémové tabulky, pohledy, uložené procedury, které uživateli na jeho dotaz vrátí kompletní popis dané entity, ať již jde o tabulku, pohled, proceduru, uživatele, nebo jiný objekt v databázi. Práce s tímto typem metadat je naprosto běžná. Historicky sahá k počátkům sedmdesátých let minulého století v souvislosti s datovými slovníky mainfraimových systémů. Pak nastoupily nástroje typu CASE, které fakticky pracují na úrovni metadat. Jejich hlavní výhoda spočívá v tom, že umí metadata formulovat v jazyku příslušného databázového stroje, a tedy po namodelování struktury databáze její objekty vytvořit třeba v prostředí Oracle, Microsoft, MySQL, Interbase, nebo úplně jiném. O metadatech se však dá uvažovat v širším kontextu než jenom jako o datových modelech. Nejvýstižnější metafora je tato: kdyby metadata byla románem, řekla by nám příběh celého systému od začátku až do konce. Datový sklad představuje systém, kde je problematika metadat patrná asi nejlépe.
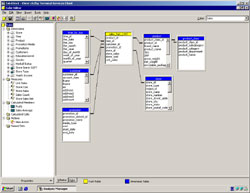
Grafická reprezentace metadat OLAP kostky
Povědomí o datových skladech je dnes poměrně velké, hlavní motivací pro budování centrálního úložiště dat bývá velké množství heterogenních systémů v organizaci. Typickým příkladem může být například telekomunikační firma, která má údaje o konkrétních zákaznících rozptýleny v mnoha systémech: v billingu vidí oceněné hovory, v mediaci má detailní informace o volání, v systému pro vymáhání pohledávek informaci o nezaplacených platbách, v systému call centra informace o zákazníkových kontaktech či stížnostech a v mnoha dalších systémech podporujících další služby informace o jejich využívání. Pro konkrétní informaci - např. najdi mi seznam všech osob, které jsou pro nás ziskové, v posledních třech měsících volaly do Německa, mají aktivovaný roaming a neposílají platby opožděně - by bylo třeba položit dotazy do několika systémů. Každý z nich však může být na jiné platformě, má jiné datové struktury, takže každý takový dotaz by musel vytvořit jiný člověk. Výsledky všech těchto dotazů by se pak musely sjednotit. Jde-li řádově o stovky tisíc dat na výstupu, je takový postup prakticky nerealizovatelný, protože v požadovaném čase danou odpověď není schopen dát, nemluvě o finančních nákladech. Datový sklad takovou situaci řeší tím, že data zpřístupní uživatelům na jednom místě. Pro koncové uživatele těch míst může být i víc (jednotlivé data marty), ale všechna mají shodnou technologii, shodný nástroj, kterým se k datům dá přistupovat a shodný popis. Totiž metadata ve stejném formátu. Podíváme-li se na situaci z ještě větší blízkosti, těch míst, která vyžadují nějaký popis metadaty, je více. Základní složkou datového skladu je relační databáze, která složí k uložení dat. Už na tomto místě, alespoň z pohledu datového skladu, nastává problém. Standardní popis metadat je nedostačující - přestože je datový model v případě vhodně zvolených jmenných konvencí srozumitelný (víme, co je dimenze či faktová tabulka, víme, která tabulka a jak udržuje historii). Ze skutečnosti, že k relační vrstvě přistupují koncoví uživatelé (obvykle ti, kteří vyžadují data na velmi detailní úrovni pro své analýzy), vyplývá, že je nutná dokumentace toho, co která tabulka fakticky obsahuje. Uvažme například tabulku, která se jmenuje D_Zakaznik. Je zákazníkem ten, komu se fakturuje? Je jím ten, kdo využívá nějakou konkrétní službu? Je jím ten, kdo fyzicky vlastní telefon? Z pohledu každého oddělení tomu bývá většinou jinak, avšak datový sklad je v organizaci zpravidla jenom jeden.
Data do datového skladu putují z primárních systémů. Využívá se přitom datových pump psaných v procedurálním SQL jazyce nebo specializovaných nástrojů pro ETL procesy (extraction, transformation, loading). Transformace jsou někdy triviální - přenos dat v poměru 1:1 z primárního systému. Někdy jsou netriviální, ba dokonce velmi komplikované. Typickými operacemi jsou: náhrada klíčů (lookup), agregace, spojení většího množství tabulek, doplňování chybějících údajů implicitními hodnotami, validace údajů vůči referenčním číselníkům, případě jejich obohacení o další data. Většina používaných nástrojů obsahuje podporu pro správu metadat ETL procesů, nicméně opět se zde objevuje stejný problém jako v předchozím případě. Datové transformace v ETL procesech nejsou pouze technickým převodem dat jednoho systému do druhého, ale obsahují v sobě (často i komplikovanou) logiku, kterou požadují koncoví uživatelé. Tato logika vychází z nějakého reálného důvodu. Důvod, proč se má dát při validaci údajů přednost jednomu systému před druhým, může být třeba v tom, že při pořizování dat v jednom případě je požadován občanský průkaz, zatímco v druhém případě nikoliv. Uživatelskou vrstvu datového skladu představují dotazovací nástroje, které umožňují generovat reporty, nebo zpřístupňují data pro komplikované analýzy. V případě reportů se kromě popisu toho, jak je report sestaven a co která hodnota fakticky znamená, objevuje ještě požadavek na další informace (metadata): Kdy byl report sestaven? Z jaký dat? (Tj. jak je starý snímek z primárního systému, kdy proběhla poslední ETL transformace a s jakým výsledkem, které primární systémy poskytly data a které ne atp.) V případě OLAP nástrojů vstupují do hry ještě popisy a význam vypočítaných ukazatelů a vypočítaných prvků v dimenzích. Typicky jde o hodnoty různých průměrů, agregací (YearToDate, MonthToDate), porovnávání s odpovídajícími časovými úseky předcházejících let (může jít o kalendářní nebo fiskální období) nebo uživatelsky definované množiny prvků (všechny produkty našeho oddělení, deset nejziskovějších zákazníků). Metadat je kolem datového skladu prostě hodně. Existují specializované nástroje pro jejich správu. Podpora technických metadat, jako jsou datové modely, fyzická realizace transformací, definice vypočtených ukazatelů, lze z příslušných systémů většinou získat, častokrát i v definovaných standardech (zde už můžeme mluvit o metametadatech). Problémem však často zůstává správa byznys metadat, tedy věcného popisu datových entit, důvodů pro konkrétní transformace či vzorce na úrovni OLAPu. A největší výzvou je vazba těchto business metadat s metadaty technickými, která jim odpovídají. Tato vazba je však nutná proto, abychom mohli sledovat celý příběh datového skladu. Bez jeho znalosti je těžké řešit úkoly, jako jsou datová kvalita, impact analýza nebo kvalitní reporting.
Autor článku, Mgr. Marek Polášek, je generálním ředitelem společnosti Adastra Apliqua.
S metadaty v organizacích je to podobně. Poprvé se s tímhle slovem setkáte ve chvílích, kdy je třeba o datech něco zjistit, a ono to nějak nejde. Například ve velké organizaci chcete zavést novou verzi staršího systému. Aplikaci před pěti lety napsal velmi šikovný programátor. Od té doby funguje skvěle. Jenže... kolega programátor už v té organizaci rok nepracuje. Psaní technické dokumentace ho moc nebavilo. Vlastně se ani moc neví, kdo aplikaci přesně využívá a jaká jsou její rozhraní k jiným systémům. V takové situaci začne pátrání hodné kvalit Sherlocka Holmese: Kde jenom je ta dokumentace? Máme nějaký datový model? Jací uživatelé a kdy systém používají? Jaké další systémy si berou z této aplikace data? Nejobvyklejší popis toho, co znamená slovo metadata, je: jsou to data o datech. Podobně jako s metafyzikou - nejdřív máme data, a pak o nich nějak mluvíme. Jsou to například informace o názvech sloupců v tabulkách a datových typech. V relačních databázích existuje celá řada způsobů, jak se k takovým informacím dostat. Mohou to být systémové tabulky, pohledy, uložené procedury, které uživateli na jeho dotaz vrátí kompletní popis dané entity, ať již jde o tabulku, pohled, proceduru, uživatele, nebo jiný objekt v databázi. Práce s tímto typem metadat je naprosto běžná. Historicky sahá k počátkům sedmdesátých let minulého století v souvislosti s datovými slovníky mainfraimových systémů. Pak nastoupily nástroje typu CASE, které fakticky pracují na úrovni metadat. Jejich hlavní výhoda spočívá v tom, že umí metadata formulovat v jazyku příslušného databázového stroje, a tedy po namodelování struktury databáze její objekty vytvořit třeba v prostředí Oracle, Microsoft, MySQL, Interbase, nebo úplně jiném. O metadatech se však dá uvažovat v širším kontextu než jenom jako o datových modelech. Nejvýstižnější metafora je tato: kdyby metadata byla románem, řekla by nám příběh celého systému od začátku až do konce. Datový sklad představuje systém, kde je problematika metadat patrná asi nejlépe.
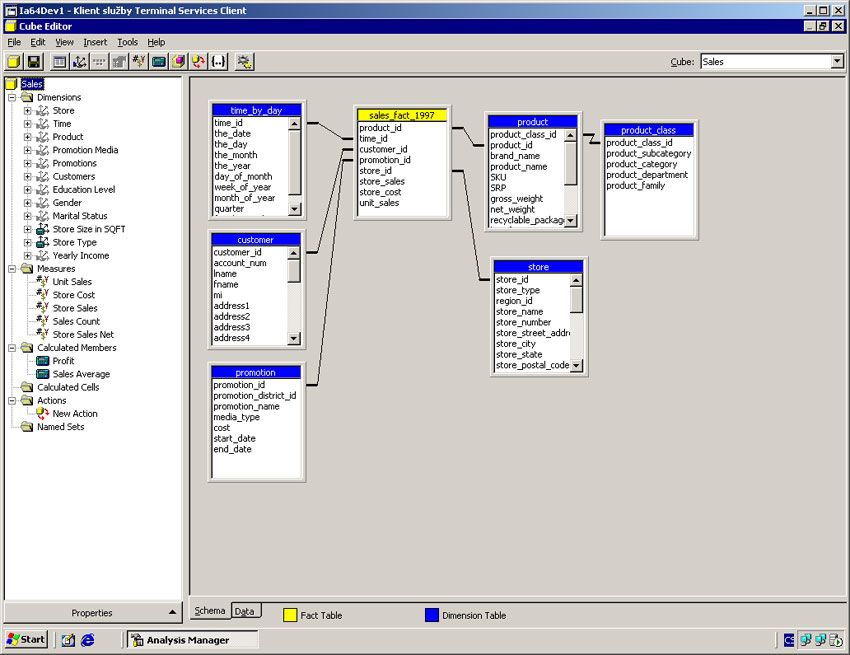
Grafická reprezentace metadat OLAP kostky
Povědomí o datových skladech je dnes poměrně velké, hlavní motivací pro budování centrálního úložiště dat bývá velké množství heterogenních systémů v organizaci. Typickým příkladem může být například telekomunikační firma, která má údaje o konkrétních zákaznících rozptýleny v mnoha systémech: v billingu vidí oceněné hovory, v mediaci má detailní informace o volání, v systému pro vymáhání pohledávek informaci o nezaplacených platbách, v systému call centra informace o zákazníkových kontaktech či stížnostech a v mnoha dalších systémech podporujících další služby informace o jejich využívání. Pro konkrétní informaci - např. najdi mi seznam všech osob, které jsou pro nás ziskové, v posledních třech měsících volaly do Německa, mají aktivovaný roaming a neposílají platby opožděně - by bylo třeba položit dotazy do několika systémů. Každý z nich však může být na jiné platformě, má jiné datové struktury, takže každý takový dotaz by musel vytvořit jiný člověk. Výsledky všech těchto dotazů by se pak musely sjednotit. Jde-li řádově o stovky tisíc dat na výstupu, je takový postup prakticky nerealizovatelný, protože v požadovaném čase danou odpověď není schopen dát, nemluvě o finančních nákladech. Datový sklad takovou situaci řeší tím, že data zpřístupní uživatelům na jednom místě. Pro koncové uživatele těch míst může být i víc (jednotlivé data marty), ale všechna mají shodnou technologii, shodný nástroj, kterým se k datům dá přistupovat a shodný popis. Totiž metadata ve stejném formátu. Podíváme-li se na situaci z ještě větší blízkosti, těch míst, která vyžadují nějaký popis metadaty, je více. Základní složkou datového skladu je relační databáze, která složí k uložení dat. Už na tomto místě, alespoň z pohledu datového skladu, nastává problém. Standardní popis metadat je nedostačující - přestože je datový model v případě vhodně zvolených jmenných konvencí srozumitelný (víme, co je dimenze či faktová tabulka, víme, která tabulka a jak udržuje historii). Ze skutečnosti, že k relační vrstvě přistupují koncoví uživatelé (obvykle ti, kteří vyžadují data na velmi detailní úrovni pro své analýzy), vyplývá, že je nutná dokumentace toho, co která tabulka fakticky obsahuje. Uvažme například tabulku, která se jmenuje D_Zakaznik. Je zákazníkem ten, komu se fakturuje? Je jím ten, kdo využívá nějakou konkrétní službu? Je jím ten, kdo fyzicky vlastní telefon? Z pohledu každého oddělení tomu bývá většinou jinak, avšak datový sklad je v organizaci zpravidla jenom jeden.
Data do datového skladu putují z primárních systémů. Využívá se přitom datových pump psaných v procedurálním SQL jazyce nebo specializovaných nástrojů pro ETL procesy (extraction, transformation, loading). Transformace jsou někdy triviální - přenos dat v poměru 1:1 z primárního systému. Někdy jsou netriviální, ba dokonce velmi komplikované. Typickými operacemi jsou: náhrada klíčů (lookup), agregace, spojení většího množství tabulek, doplňování chybějících údajů implicitními hodnotami, validace údajů vůči referenčním číselníkům, případě jejich obohacení o další data. Většina používaných nástrojů obsahuje podporu pro správu metadat ETL procesů, nicméně opět se zde objevuje stejný problém jako v předchozím případě. Datové transformace v ETL procesech nejsou pouze technickým převodem dat jednoho systému do druhého, ale obsahují v sobě (často i komplikovanou) logiku, kterou požadují koncoví uživatelé. Tato logika vychází z nějakého reálného důvodu. Důvod, proč se má dát při validaci údajů přednost jednomu systému před druhým, může být třeba v tom, že při pořizování dat v jednom případě je požadován občanský průkaz, zatímco v druhém případě nikoliv. Uživatelskou vrstvu datového skladu představují dotazovací nástroje, které umožňují generovat reporty, nebo zpřístupňují data pro komplikované analýzy. V případě reportů se kromě popisu toho, jak je report sestaven a co která hodnota fakticky znamená, objevuje ještě požadavek na další informace (metadata): Kdy byl report sestaven? Z jaký dat? (Tj. jak je starý snímek z primárního systému, kdy proběhla poslední ETL transformace a s jakým výsledkem, které primární systémy poskytly data a které ne atp.) V případě OLAP nástrojů vstupují do hry ještě popisy a význam vypočítaných ukazatelů a vypočítaných prvků v dimenzích. Typicky jde o hodnoty různých průměrů, agregací (YearToDate, MonthToDate), porovnávání s odpovídajícími časovými úseky předcházejících let (může jít o kalendářní nebo fiskální období) nebo uživatelsky definované množiny prvků (všechny produkty našeho oddělení, deset nejziskovějších zákazníků). Metadat je kolem datového skladu prostě hodně. Existují specializované nástroje pro jejich správu. Podpora technických metadat, jako jsou datové modely, fyzická realizace transformací, definice vypočtených ukazatelů, lze z příslušných systémů většinou získat, častokrát i v definovaných standardech (zde už můžeme mluvit o metametadatech). Problémem však často zůstává správa byznys metadat, tedy věcného popisu datových entit, důvodů pro konkrétní transformace či vzorce na úrovni OLAPu. A největší výzvou je vazba těchto business metadat s metadaty technickými, která jim odpovídají. Tato vazba je však nutná proto, abychom mohli sledovat celý příběh datového skladu. Bez jeho znalosti je těžké řešit úkoly, jako jsou datová kvalita, impact analýza nebo kvalitní reporting.
Autor článku, Mgr. Marek Polášek, je generálním ředitelem společnosti Adastra Apliqua.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.












| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |