

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce

| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEM 5/2002
Datawarehousing v bankovnictví
Jindřich Vavruška
Při debatě o přestávce jakéhosi bankovního semináře jsem s překvapením zjistil, že několik přítomných bankovních specialistů na informační technologie vesměs považovalo datový sklad za "nějakou databázi kam se přehrávají data." Ne, že by to nebyla pravda, ovšem přítomní pokládali za hlavní rys datového skladu hlavně jeho název a za hlavní kompetenci firem "prodávajících" řešení datawarehouse/datových skladů (tak trochu mezi řádky) jejich marketingovou zručnost.


Čím se tedy datové sklady liší od "běžné databáze"?
Specifika datového skladu
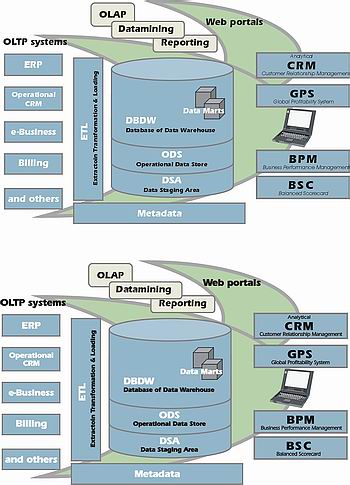
Datový sklad, na rozdíl od prvního dojmu, který ve vás vyvolá samotný termín, není jen sklad nějakých dat. Jeho architektura se liší od transakčních (OLTP) systémů, které jsou optimalizovány pro rychlé ukládání dat z transakcí.
Databáze datového skladu
Datový sklad je optimalizován na zpracování dotazů, zejména souhrnných, na velké množství dat. Rychlost dotazování zaručuje hvězdicová struktura databázového modelu s tabulkami dimenzí a tabulkami faktů. Datový sklad je aktualizován v pravidelných intervalech, v době, kdy k němu není uživatelům umožněn přístup (tzv. offline). Naproti tomu běžné databáze OLTP systémů jsou optimalizovány na zpracování velkého množství relativně malých transakcí (vkládání faktury do účetního systému), datový model je většinou poplatný třetí normální formě a jsou aktualizovány průběžně.
V databázi datového skladu rozlišujeme dva druhy tabulek: tabulky faktů, v nichž jsou uloženy hodnoty ukazatelů, a tabulky dimenzí.
Tabulky faktů jsou dynamické, s každou aktualizací v nich přibudou nové záznamy za uplynulé období (transakce, koncové stavy na účtech) a neprobíhá v nich operace update.
Tabulky dimenzí jsou v podstatě statické. Avšak v některých prvcích dimenzí může docházet k občasným změnám (např. přestěhování klienta). Při těchto změnách dochází k problémům v reportingu: jestliže se například klient Kraus přestěhoval z Prahy do Plzně, potřebujeme jej od určitého data vykazovat pod jeho novou pobočkou; zároveň musíme zajistit, aby data ze staré pobočky byla zachována. Jak kromě toho zajistíme "kontinuitu", tj. aby při zachování správné vazby klienta na starou i novou pobočku byla zachována i informace o tom, že se jedná stále o téhož klienta banky? Řešení závisí na konkrétní situaci - buď se vytvoří dvě propojené kopie prvku s uvedením data platnosti, nebo se použije poslední platný stav, a historie se zachytí v pomocné tabulce. Podobné problémy mohou vzniknout při změně organizační struktury. Co udělat, je-li v důsledku změny zaměření pobočka v Plzni přesunuta od 1.7.2001 z divize retailové sítě do divize středních podniků? V hierarchii pak existují dva podstromy, jeden s datem do června 2001, druhý platný od července 2001. Pro řešení těchto problémů s aktualizací dimenzí existuje metodika tzv. "slowly changing dimensions".
Čím se tedy datové sklady liší od "běžné databáze"?
Specifika datového skladu
Datový sklad, na rozdíl od prvního dojmu, který ve vás vyvolá samotný termín, není jen sklad nějakých dat. Jeho architektura se liší od transakčních (OLTP) systémů, které jsou optimalizovány pro rychlé ukládání dat z transakcí.
Databáze datového skladu
Datový sklad je optimalizován na zpracování dotazů, zejména souhrnných, na velké množství dat. Rychlost dotazování zaručuje hvězdicová struktura databázového modelu s tabulkami dimenzí a tabulkami faktů. Datový sklad je aktualizován v pravidelných intervalech, v době, kdy k němu není uživatelům umožněn přístup (tzv. offline). Naproti tomu běžné databáze OLTP systémů jsou optimalizovány na zpracování velkého množství relativně malých transakcí (vkládání faktury do účetního systému), datový model je většinou poplatný třetí normální formě a jsou aktualizovány průběžně.
V databázi datového skladu rozlišujeme dva druhy tabulek: tabulky faktů, v nichž jsou uloženy hodnoty ukazatelů, a tabulky dimenzí.
Tabulky faktů jsou dynamické, s každou aktualizací v nich přibudou nové záznamy za uplynulé období (transakce, koncové stavy na účtech) a neprobíhá v nich operace update.
Tabulky dimenzí jsou v podstatě statické. Avšak v některých prvcích dimenzí může docházet k občasným změnám (např. přestěhování klienta). Při těchto změnách dochází k problémům v reportingu: jestliže se například klient Kraus přestěhoval z Prahy do Plzně, potřebujeme jej od určitého data vykazovat pod jeho novou pobočkou; zároveň musíme zajistit, aby data ze staré pobočky byla zachována. Jak kromě toho zajistíme "kontinuitu", tj. aby při zachování správné vazby klienta na starou i novou pobočku byla zachována i informace o tom, že se jedná stále o téhož klienta banky? Řešení závisí na konkrétní situaci - buď se vytvoří dvě propojené kopie prvku s uvedením data platnosti, nebo se použije poslední platný stav, a historie se zachytí v pomocné tabulce. Podobné problémy mohou vzniknout při změně organizační struktury. Co udělat, je-li v důsledku změny zaměření pobočka v Plzni přesunuta od 1.7.2001 z divize retailové sítě do divize středních podniků? V hierarchii pak existují dva podstromy, jeden s datem do června 2001, druhý platný od července 2001. Pro řešení těchto problémů s aktualizací dimenzí existuje metodika tzv. "slowly changing dimensions".
| |
OLAP
Uživatelským rozhraním databáze datového skladu jsou OLAP (On Line Analytical Processing) nástroje. Ty zpravidla obsahují standardní sadu reportingových nástrojů (grafy, tabulky, možnosti filtrování, zvýraznění extrémů). Reporty jsou přitom interaktivní, klepnutím na prvek dimenze nebo fakt se zobrazí nový graf, týkající se jen poklepaného prvku (hierarchický rozpad, drill-down). Interaktivnost grafů podporuje přirozeným způsobem analytický přístup, kdy pátráme po anomáliích projevujících se na vyšším stupni agregace propadem do nižších úrovní.
I když je hvězdicové schéma pro tento typ dotazů velmi efektivní, objemy dat v datových skladech bývají tak obrovské, že dotazy do relační databáze nesplňují požadavky uživatelů na odezvu (podle průzkumů dotazy trvající nad jednu minutu vedou uživatele k tomu, že přejde k jiné činnosti). Proto OLAP nástroje předpočítávají agregace a ukládají je do pomocných struktur, tzv. kostek. Tyto struktury mohou mít formu agregačních tabulek přímo v databázi (mluvíme pak o ROLAPu, Relational On Line Analytical Processing), nebo proprietárních souborů (tzv. "čistý OLAP"). HOLAP (Hybrid On Line Analytical Processing) předpočítává jen některé agregace. Ostatní se buď počítají přímo z databáze, nebo, sofistikovaněji, počítají z jiných agregací. Kromě uživatelského rozhraní a strategií pro správu kostek poskytují OLAP nástroje i vhodnou abstrakci dimenzí a faktů (více uživatelskou, méně závislou na databázi) a různé strategie pro jejich správu.
Datamart
Datový sklad by měl v každém podniku být pouze jeden a měl by tvořit informační základnu pro všechny analytické aplikace. Je zdrojem číselníku produktů, časové, zákaznické a organizační dimenze a dalších dimenzí. Pro specializované analýzy, které dodávají datům obchodní hodnotu, se vyvíjejí datamarty, jakési "odvozené datové sklady". Datamart pro profitabilitu produktů může obsahovat zcela odlišná data a algoritmy než datamart pro profitabilitu zákazníků, nebo datamart pro vyhodnocování reklamních kampaní, jednotná základna však umožní dát tyto data do vzájemných souvislostí. Klíč a význam pobočky bude totiž stejný ve všech datamartech a bude tak sloužit k porovnání jednotlivých poboček mezi sebou z hlediska profitability zákazníka, produktů a reklamních kampaní.
Čistá a konzistentní data datového skladu jsou výborným zdrojem pro OLAP, datamining, nebo klasický statický reporting.
ETL
Datový sklad je plněn daty z OLTP systémů v pravidelných intervalech (denně, týdně, měsíčně) pomocí ETL skriptů (Extraction, Transformation, Loading). ETL nástroje efektivně řeší problémy jako nativní přístup k databázím různých výrobců, spojování tabulek z různých zdrojů, lookup (vyhledání neklíčového atributu tabulky podle klíčového, používáno u přiřazování klíčů dimenzí do tabulky faktů), složité transformace (nutné pro čištění dat a výpočty obchodních ukazatelů), normalizace a denormalizace dat, atd. Zpravidla obsahují vlastní procedurální jazyk i datové typy a používají na zdrojové i cílové databázi nezávislé datové struktury (hashovací tabulky, vyhledávací stromy).
Metadata
Datový sklad nelze omezovat jen na databázi, musíme do něj nutně začlenit i ETL procesy a OLAP. Údržba několika rozdílných nástrojů v zásadě sdílejících stejná data (přidání atributu v OLTP systému se projeví v ETL, databázi, OLAPu i v závislých datamartech) tak může být poměrně náročná. Každý z těchto stupňů obsahuje svůj vlastní způsob popisu dat (data o datech, metadata). Databáze mají systémový katalog, ETL nástroje popisy vstupních a výstupních polí a popisy transformací, OLAP nástroje popisy dimenzí a faktů. Společná, sdílená metadata by velmi ulehčila údržbu datového skladu. Jinou otázkou kolem metadat je popis dat v datovém skladu. Je přirozené, že pokud mají jiné aplikace využívat služeb datového skladu, musí být přesně popsáno a zveřejněno, co přesně datový sklad obsahuje, včetně vyčerpávajícího popisu obchodního významu atributu.
Návratnost investic
Datový sklad není jednolitý moloch, který je třeba budovat pět let. Datový sklad lze budovat po částech, které zahrnují ucelenou problematiku, a po dokončení jedné části lze pokračovat s využitím již vybudovaných komponent. Datový sklad může mít při správné metodice návrhu a implementace dílčích celků poměrně rychlou návratnost.
Přínosy technologií datového skladu v bankovní praxi
Konsolidace dat
Počet bankovních primárních OLTP systémů bývá vyšší než v jiných odvětvích. Vyplývá to z velkého počtu velmi různorodých produktů, pro něž je potřeba provozovat specifické systémy. Tyto specifické systémy pocházejí od různých výrobců a jsou různě staré. Ale má-li banka při jejich výběru šťastnou ruku, může se stát, že většina jich je provozovány na stejné platformě.
Konsolidovaná data pro povinné výkazy
Jakoby naschvál je potřeba do některých povinných výkazů použít zůstatky nebo částky transakcí, které nelze získat ze základního bankovního systému, protože v požadované struktuře tam prostě nejsou. Data ze speciálního systému, například pro obchodování s deriváty nebo systému pro podporu platebního styku, jsou zase v nějaké podobě obsažena v hlavním bankovním systému, a proto je potřeba zamezit duplicitám.
Správně navržené ETL procesy zajistí, že všechny potřebné zůstatky i objemy transakcí budou k dispozici v konzistentním stavu v datovém skladu. Z konzistentních dat je možné vytvářet nejen povinné výkazy, ale i podrobnější a pro vedení také mnohem zajímavější reporty pro management.
Reporting založený nad datovým skladem s sebou nese ještě jednu výhodu: v porovnání s "klasickým" přístupem vykazuje vyšší míru připravenosti na budoucí požadavky na výkazy, ať už se strany regulátora nebo vedení banky. Jak vypadá reakce na nový report v prostředí založeném na využití dat z transakčních systémů? Zpravidla se vytvoří nová, na míru šitá aplikace pro sběr a zpracování potřebných dat z existujících extraktů, případně se vytvoří nový extrakt pro chybějící data. Postupně tak vzniká složitý systém "každý s každým". Při použití datového skladu se lze plně spolehnout na již očištěná data a řešit pouze novou část. V bance s již vybudovaným datovým skladem znamenají nové požadavky pouze nadefinování nových reportů v již používaném OLAP nástroji namísto pracného získávání speciální aplikace pro nový druh reportu.
Identifikace klienta
V každém bankovním systému pro podporu specifického produktu je identifikován klient. Některé systémy používají zcela odlišná identifikační čísla, mají odlišnou strukturu klientských údajů a nezřídka obsahují i různé způsoby zápisu týchž dat (pořadí jméno/příjmení, překlepy, háčky/čárky, neprovedené aktualizace při změně jména apod.). Bohužel, tyto systémy nejsou nijak propojené a dotyčné produkty poskytují různá oddělení banky. Tak se často stává, že je velmi obtížné, ne-li nemožné, vůbec získat přehled o tom, které produkty klient využívá.
Tento problém se v datovém skladu řeší na úrovni ETL procesů. Dokonalé identifikace se dosahuje obtížně, mnohdy za podpory sofistikovaných softwarových produktů (Trilium). Vyčištění a správné propojení dat může být sice obtížné a relativně nákladné, ale přináší odměnu v podobě konzistentního a pravidelně aktualizovaného přehledu o klientech.
Alokace nákladů, activity based costing
Mezi účetními daty z hlavní knihy lze nalézt náklady na provoz jednotlivých systémů a oddělení, včetně odpisů, oprávek apod. Identifikace těchto nákladů v datovém skladu je základem k jejich smysluplnému rozdělení mezi aktivity přinášející zisk a prvním krokem ke zjištění skutečné ziskovosti transakcí, produktů i klientů. Informace o profitabilitě jsou velmi ceněné, ale získávány jsou velmi obtížně.
Řízení obchodní činnosti
Z důvodů bezpečnosti obsahuje téměř každá bankovní transakce údaje o tom, který pracovník transakci inicioval, zadal do systému, schválil, opravil chybu atd. Přenesení těchto dat do datového skladu otevírá možnost měřit výkonnost a kvalitu práce jednotlivých zaměstnanců. Díky konzistentnosti datového skladu lze tyto údaje navázat na tržby, resp. ziskovost jednotlivých transakcí. Tak bude možné hodnotit zaměstnance nejen podle počtu a objemu uzavřených obchodů, ale i podle zisku, který bance přinesl, a tím se vyhnout přehnanému odměňování pracovníků, kteří uzavírají obchody se ztrátovými klienty.
Mimo to je možné sledovat výkonnost či rizikovost jednotlivých produktů a optimalizovat alokaci kapitálu s cílem dosáhnout co nejvyšší ziskovosti a ROCE.
Analytické CRM
Korunou výše zmíněných použití datového skladu je jejich integrace v analytickém CRM.
Co se tím myslí? Customer Relationship Management neboli CRM zpravidla označuje systém pro řízení vztahů s klientem. Takový systém zahrnuje správu kontaktů, demografická data klienta, historii komunikace, informace o marketingových kampaních apod. Takový systém ale neobsahuje další důležité údaje: o tom, jaké produkty klient využívá, jaké jsou jeho průměrné zůstatky, obrat jednotlivých druhů produktů, kolik kreditních karet je vystaveno k jeho účtu atd. Bez těchto údajů mohou marketingové kampaně "cílené" na určitou demografickou skupinu být medvědí službou, pokud jsou v ní nabízeny některým klientů produkty, které již využívají nebo je naopak již několikrát odmítli.
Analytickým CRM nazýváme spojení výše popsaného operativního CRM s datovým skladem. Součástí analytického CRM může být takzvaný Exploratory Datamart, obsahující vybrané ukazatele, ve kterém se s použitím metod data miningu provádí segmentace klientů a vyhledávají se významné trendy. Pomocí výsledků data miningu lze vytvářet prediktivní modely chování klientů. Aplikací prediktivních modelů na data v analytickém CRM lze předpovídat náchylnost klientů ke koupi určitého produktu a ve vhodné chvíli individuálně oslovit klienta cílenou nabídkou, jejíž naděje na úspěch je řádově vyšší než u běžné marketingové kampaně.
Závěr
Ve finančních institucích není znalost technologie datových skladů obecně rozšířena. Její úspěšná aplikace předpokládá pochopení specifických rysů datawarehousingu jak se strany pracovníků IT, tak se strany analytiků a dalších uživatelů. Řešení některých informačních potřeb jinak než s využitím datového skladu je obtížné, nákladné a časově náročné, pokud je vůbec možné. Nad datovým skladem lze vybudovat celou škálu analytických aplikací, od prostého reportingu přes řízení ziskovosti až po analytické CRM a sofistikované metody předpovídání chování klientů. Datový sklad umožňuje efektivnější vývoj produktů, řízení obchodní činnosti a marketing.
Manažerský systém a datový sklad v IPB Pojišťovně
IPB Pojišťovna je jednou z pěti největších pojišťoven v České republice se sídlem v Pardubicích. Struktura poboček a kanceláří má celorepublikovou působnost a její nabídka zahrnuje životní pojištění, pojištění podnikatelských rizik, pojištění odpovědnosti za škodu způsobenou provozem vozidla, pojištění motorových vozidel, pojištění rodinných domů a domácností a cestovní pojištění.
V rámci projektu manažerského systému a datového skladu, který realizuje společnost ADASTRA - byly postupně zpracovány oblasti hrubé obchodní produkce, pojistného kmene, předpisů a plateb pojistného a likvidace pojistných událostí. Vývoj manažerského informačního systému pokračuje zpracováním dalších oblastí pojišťovací problematiky a produktů. Současně s dalším vývojem proběhl také pilotní projekt data-miningu.
Pro uživatele bez znalosti práce s databází umožňuje manažerský informační systém v IPB interaktivní přístup k dříve prakticky nedostupným datům. Pokročilí uživatelé oceňují řádové zrychlení svých analýz dříve prováděných přímo nad provozním systémem. Správci provozního systému zase vítají odlehčení jeho zátěže. Zavedením manažerského informačního systému odpadla nutnost neflexibilní distribuce rozsáhlých a nepřehledných tištěných sestav, které byly nahrazeny parametrizovatelnými reporty v elektronické formě. Zásadně se zlepšila informovanost poboček, které dříve dostávaly pouze neúplné informace a i ty se značným časovým zpožděním. Vývoj datového skladu má zpětný vliv na metodiku tvorby provozního systému a pozitivně tak ovlivňuje jeho informační hodnotu.
Pozn. red.: Autor článku, Jindřich Vavruška, pracuje jako konzultant ve společnosti ADASTRA, s.r.o.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 1 | 2 | 3 | 4 | 5 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce
| 26.6. | https://kybeon.moyazone.cz/konzultacni-hodiny/iso-certifikace-prakticky/... |
