

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

PříLOHA 6/2003


Současnost bychom spíše než jako "informační revolucí" měli nazývat dobou "datové exploze". Je totiž zásadní rozdíl mezi tím, mít nahromaděná množství dat a mít k dispozici informaci použitelnou k rozhodování. Jsme stále ještě daleko ideálu informační společnosti "mít správnou informaci ve správný čas na správném místě", a to i přes obrovský rozvoj informačních technologií v posledních letech.
Každá organizace dnes disponuje v historii nebývalým množstvím dat, buď bylo jejich zdrojem tzv. ruční pořízení (např. ekonomický informační systém) nebo jsou výsledkem automatického sběru dat (např. data ze systémů řízení technologických procesů). V přeneseném smyslu slova můžeme říci, že tato data mohou tvořit základ určité "paměti" organizace. Podobně jako inteligentní jedinec má schopnost optimalizovat své chování využitím zapamatovaných informací, tak je také třeba hledat způsoby, jak využít informace nacházející se v "paměti" organizace. Je zřejmé, že činnost vedoucí k využití nahromaděných dat má mnoho aspektů zasahujících do celé řady oborů. Kromě otázek technických, ekonomických a organizačních nesmí být opomíjeny ani otázky etické a právní.
Jak ale vypadá stav "paměti" dnešní typické organizace? Jádrem informačního systému (IS) bývá transakční systém (On-Line Transactional Processing - OLTP) pokrývající v minimálním případě finanční systém, běžně pak celou řadu dalších agend. OLTP systém můžeme charakterizovat z pohledu "paměti" organizace jako:
. paměť relativně dlouhodobou (ze zákona je nutné archivovat transakce řádově léta),
. paměť těžce dostupnou (OLTP systémy jsou optimalizovány na zpracování transakcí, přístup k historickým datům je velmi obtížný),
. paměť nekonzistentní (je typické, že během "života" IS dochází ke změnám způsobu zobrazení identických skutečností v OLTP systému, výměně technologií a dodavatelů jednotlivých subsystémů),
. paměť s exponenciálně rostoucím objemem uložených dat (odhaduje se, že celosvětově se objem OLTP dat zdvojnásobí každých 18 až 24 měsíců).

Data a informace
Business intelligence, ROLAP a open source v prostředí středních podniků
Michal Dovrtěl
Současnost bychom spíše než jako "informační revolucí" měli nazývat dobou "datové exploze". Je totiž zásadní rozdíl mezi tím, mít nahromaděná množství dat a mít k dispozici informaci použitelnou k rozhodování. Jsme stále ještě daleko ideálu informační společnosti "mít správnou informaci ve správný čas na správném místě", a to i přes obrovský rozvoj informačních technologií v posledních letech.
Každá organizace dnes disponuje v historii nebývalým množstvím dat, buď bylo jejich zdrojem tzv. ruční pořízení (např. ekonomický informační systém) nebo jsou výsledkem automatického sběru dat (např. data ze systémů řízení technologických procesů). V přeneseném smyslu slova můžeme říci, že tato data mohou tvořit základ určité "paměti" organizace. Podobně jako inteligentní jedinec má schopnost optimalizovat své chování využitím zapamatovaných informací, tak je také třeba hledat způsoby, jak využít informace nacházející se v "paměti" organizace. Je zřejmé, že činnost vedoucí k využití nahromaděných dat má mnoho aspektů zasahujících do celé řady oborů. Kromě otázek technických, ekonomických a organizačních nesmí být opomíjeny ani otázky etické a právní.
Jak ale vypadá stav "paměti" dnešní typické organizace? Jádrem informačního systému (IS) bývá transakční systém (On-Line Transactional Processing - OLTP) pokrývající v minimálním případě finanční systém, běžně pak celou řadu dalších agend. OLTP systém můžeme charakterizovat z pohledu "paměti" organizace jako:
. paměť relativně dlouhodobou (ze zákona je nutné archivovat transakce řádově léta),
. paměť těžce dostupnou (OLTP systémy jsou optimalizovány na zpracování transakcí, přístup k historickým datům je velmi obtížný),
. paměť nekonzistentní (je typické, že během "života" IS dochází ke změnám způsobu zobrazení identických skutečností v OLTP systému, výměně technologií a dodavatelů jednotlivých subsystémů),
. paměť s exponenciálně rostoucím objemem uložených dat (odhaduje se, že celosvětově se objem OLTP dat zdvojnásobí každých 18 až 24 měsíců).
| |
Vyhledávání znalostí v databázích
Jestliže lze OLTP systém přirovnat k nervovému systému organizace, pak dobře navržený datový sklad (Data Warehouse - DW) může představovat její "paměť". Ani nervový systém, ani paměť však samy o sobě nestačí k tomu, aby organismus byl schopen optimalizovat své chování. K tomu je třeba mít schopnost zapamatované informace analyzovat a učit se z jejich historie. Analogicky v případě organizace je třeba mít k dispozici takové nástroje, které by umožnily objevit v datech informaci pomáhající optimalizovat rozhodování odpovědných pracovníků na všech úrovních řízení. Mluvíme zde o hledání znalostí v databázích (Knowledge Discovery in Databases - KDD). KDD je mezioborová disciplína, zahrnující použití statistických metod, vizualizace dat, expertních systémů, technologie databází, metod strojového učení a v neposlední řadě nástrojů pro tzv. On-Line Analytical Processing (OLAP). KDD lze chápat jako "proces netriviálního objevování implicitních, dopředu neznámých a potenciálně použitelných znalostí v datech" [1]. Proces KDD můžeme rozdělit na několik fází:
. selekce dat,
. příprava dat (čištění dat, transformace, kontrola kvality),
. objevování znalostí,
. prezentace znalostí.
Požadavky na systém business intelligence
Pokroky v oblasti informačních technologií umožňují snadnější a rychlejší přístup uživatelů ke stále větším objemům dat a současně činí distribuci informací levnější. Tento vývoj bude mít smysl a přinese také odpovídající ekonomické efekty jen tehdy, pokud bude následován odpovídajícím pokrokem v oblasti metod analýzy dat a metodologií jejich implementace. Uživatelé požadují přístup k věcně správným, aktuálním a snadno a jednoznačně interpretovatelným informacím.
Pro potřeby moderního řízení se ukazují jako nedostatečné schopnosti klasických exekutivních a manažerských informačních systémů nabízejících pouze statické agregované přehledy podle neměnných kritérií. Praxe si na technologiích vynucuje možnost plynule a interaktivně strukturovat analýzy od podnikových přehledů až na úroveň operativních detailů, studovat souvislosti dat na různých agregačních úrovních a provádět ad-hoc analýzy.
Nutností se stává také možnost sdílení informací, týmové spolupráce při práci s informací a snadná publikovatelnost výstupů. Tyto požadavky však činí projekty business intelligence stále dražšími, obtížněji implementovatelnými a hůře udržovatelnými. Jednoduše řečeno, výše popsané skutečnosti vytváří tlak na zvyšování celkové ceny za vlastnictví aplikace (Total Cost of Ownership - TCO).
| |
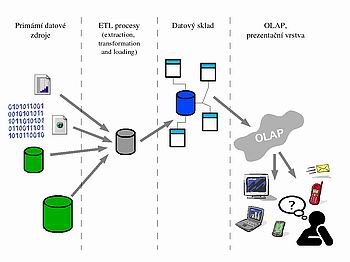
Architektura systému business intelligence
V obecném schématu architektury systému business inteligence lze rozlišit tři základní subsystémy (obr. 1), v podstatě odpovídající základním fázím procesu KDD. Systém tzv. ETL procesů (extraction, transformation and loading) slouží k extrakci dat z primárních systémů, jejich úpravám, kontrole a zajištění kvality dat. ETL procesy také provádí zavedení dat do specializovaného uložiště, optimalizovaného pro co nejefektivnější možnost analýzy dat. Prezentační vrstva pak zajišťuje interakci uživatele se systémem.
Takto pojatý systém může být technicky realizován nejrůznějšími způsoby a technologiemi. Pro malá řešení jsou populární nejrůznější nástroje kategorie tzv. "desktop OLAP", kde jsou všechny uvedené subsystémy implementovány jako jedna aplikace (nebo několik modulů) určená k instalaci přímo na osobním počítači uživatele. Výhodou podobných systémů je snadná instalace a rychlá implementace jednoduchých analýz, problémem bývá zajištění dalšího rozvoje systému, který již z principu má omezenou škálovatelnost (max. objem zpracovaných dat je určen parametry osobního počítače uživatele) a vede k decentralizovaným, obtížně administrovatelným řešením. Pro uvedené nevýhody nástroje této kategorie prakticky ve větších projektech nenajdeme.
Velké projekty business intelligence využívají výhradně vícevrstvé architektury s jedním centrálním úložištěm dat - datovým skladem. Tento koncept usnadňuje administraci systému, zabezpečuje jeho škálovatelnost a v neposlední řadě důsledná centralizace garantuje tzv. "jednotnou verzi pravdy" pro celou organizaci.
Otázkou je, zda v prostředí střední firmy převáží výše popsané výhody rychlého nasazení systému kategorie tzv. "desktop OLAP", nebo zda tato zdánlivá výhoda bude později draze vykoupena problémy dalšího rozvoje takto koncipovaného systému. Zkušenost ukazuje, že i v prostředí středně velkých organizací lze zcela přirozeně těžit z robustně navrženého vícevrstvého systému opírajícího se o centrální datový sklad. Je jen třeba volit adekvátní technologie tak, aby řešení splňovalo ekonomické požadavky (minimalizace TCO) pro dané datové objemy, doby odezvy a parametry spolehlivosti, aby v maximální míře využívalo stávající infrastruktury informačního systému a aby optimálně využívalo hardware datového skladu a aplikačních serverů.
| |
Relační model datového skladu
V posledním desetiletí se objevila řada prací, které si kladly za cíl vyřešit způsob ukládání dat v DW tak, aby tento tvořil "paměť" konzistentní a snadno dostupnou (na rozdíl od OLTP systému). Kromě speciálních multidimenzionálních databází zde nachází široké uplatnění systémy založené na obecném relačním modelu.
Teoretické základy budování datových skladů podali W. H. Inmon [2] a R. Kimball [3], který přibližuje základní postupy dimenzionálního modelování relačních datových skladů a postupy generování analytických SQL dotazů na řadě příkladů datových modelů z nejrůznějších oborů lidské činnosti. Ralph Kimball také definuje základní požadavky jak na relační systémy řízení báze dat (Relational Data Base Management Systém - RDBMS) a rozšíření SQL jazyka, tak na OLAP nástroje.
V konceptu tzv. "pravého" relačního OLAP systému (dále ROLAP - Relational On-Line Analytical Processing) jsou sekvence SQL dotazů generovány tak, aby převážná část zátěže zpracování ležela na RDBMS serveru. OLAP server přijme požadavek na analytický výstup od OLAP klienta specifikovaný jazykem využívajícím objektů popsaných na tzv. sémantické vrstvě datového skladu. Popis této vrstvy (tedy popis transformací OLAP objektů na objekty, se kterými pracuje RDBMS) je uložen v databázi metadat. OLAP server s pomocí informací uložených v databázi metadat sestaví sekvenci SQL dotazů tak, aby celé zpracování proběhlo (s využitím vnořených dotazů a dočasných tabulek) na straně serveru RDBMS. Výhodou tohoto postupu je eliminace přenosu větších objemů dat mezi jednotlivými vrstvami architektury.
Obecně lze říci, že využití relačního systému řízení báze dat (RDBMS - Relational Data Base Management systém) přináší výhodu flexibility datového modelu DW, možnost jeho efektivní optimalizace i pro velmi komplexní úlohy a možnost snadného provádění ad-hoc analýz. Nevýhodou může být vyšší zátěž RDBMS a s tím spojená delší doba odezvy. Moderní ROLAP systémy jsou proto vybavovány systémem vyrovnávacích pamětí (cache), které zásadním způsobem zvyšují propustnost systému i při velkých objemech zpracovávané informace, komplexních datových modelech a velkých počtech uživatelů.
Možnosti využití "open source" technologií
Přestože koncept "open source" software je starý již desítky let, do povědomí veřejnosti a komerčního využití se dostal až v souvislosti s rozvojem operačního systému Linux v posledních letech. Dnes prožíváme období, kdy se "open source" technologie rychle rozšiřují i mimo své tradiční oblasti uplatnění (web a internetové technologie, akademická půda, tiskové a souborové servery).
Lze říci, že pro vybudování robustního business intelligence systému na bázi "open source" software jsou již ve vyzrálé podobě k dispozici všechny technologické komponenty se zřejmými výhodami "open source" konceptu jak pro kvalitu software a jeho bezpečnost, tak pro ekonomiku řešení a ochranu investice zákazníka (otevřený systém snižuje jeho závislost na jednom dodavateli, zákazník má plná práva k disponování zdrojovými kódy systému). Otázkou je, jaká bude celková cena za vlastnictví (TCO) tak komplexního systému, jakým systém business intelligence bezesporu je.
Jak bylo již zmíněno v IT Systemu 3/2003 v rozhovoru na téma "open source pro budování datových skladů", iniciovala společnost Insight Strategy "open source" projekt BEE [4], který zastřešuje vývoj technologií zaměřených na podporu implementace projektů business intelligence ve středních firmách. V rámci projektu je řešena metodologie optimálního uložení dat s ohledem na jejich analytickou výtěžnost, je vyvíjena infrastruktura pro ETL (extrakce a transformace dat, plnění datového skladu) a vícevrstvá aplikace pro analytické reportování (využívající tenkého klienta a WEB technologie). Architektura řešení je založena na metodologii ROLAP s cílem ekonomicky efektivně pokrýt projekty o objemu dat do 50 GB s využitím "open source" technologií na platformě Linux/Intel. Produkty vytvořené v rámci projektu BEE jsou publikovány paralelně pod GPL licencí [5] a komerční licencí společnosti Insight Strategy.
| |
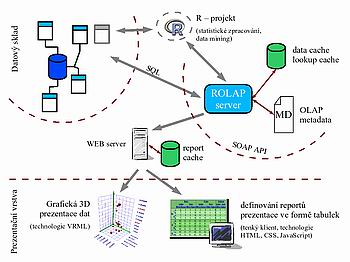
Technologie pro analytické reportování
V rámci projektu BEE je vyvíjena vícevrstvá aplikace pro analytické reportování (obr. 2). Přístup prostřednictvím tenkého klienta (WEB browser) je vhodný zejména pro tzv. "business" uživatele, kterým lze připravit potřebné reporty a zajistit k nim snadný přístup (včetně například vzdáleného přístupu pro mobilní uživatele). Jako primární uživatelské rozhraní je navržen WEB portál umožňující definování analytických reportů, jejich formátování a prezentaci.
Využití statistického software projektu "R" [6] umožňuje analytikům použít širokou škálu pokročilých statistických metod a metod pro dolování dat (data mining). Součásti projektu "R" jsou vyvíjeny na nejvýznamnějších světových akademických pracovištích zabývajících se uvedenou problematikou a jsou publikovány pod GPL licencí. Grafické knihovny projektu "R" jsou také využity pro generování kvalitní tzv. "statistické" i "obchodní" grafiky.
Použité technologie (XML, HTML, CSS a JavaScript) mají minimální nároky na síťovou infrastrukturu a zaručují snadnou administraci celého prostředí. Celý systém je důsledně internacionalizován (interně využívá kódování UTF-8) a umožňuje každému uživateli nezávislou volbu lokalizace jak uživatelského rozhraní, tak i pojmenování objektů a vlastních dat. ROLAP server zpřístupňuje své služby přes standardní aplikační rozhraní SOAP pro potenciálně širokou škálu dalších klientských aplikací.
Užitečnou pomocnou metodou pro analýzu vícerozměrných dat je interaktivní zobrazení dat v třírozměrném prostoru (tyto metody bývají zahrnovány do oblasti vizuálního data miningu). Možnost interaktivní manipulace s 3D prezentací usnadňuje uživateli pochopení struktury dat, popřípadě trendů jejich vývoje. Pro popis 3D scény je využito jazyka VRML, který je vhodný pro distribuci zobrazení v síťovém prostředí. Jazyk VRML jako uznávaný standard organizace W3C zaručuje možnost zobrazení scény na nejrůznějších platformách prostřednictvím různých typů VRML prohlížečů. Scénu je možno také prohlížet přímo z prostředí WEB prohlížeče doplněného o vhodný VRML plug-in modul.
Technologie zvolená pro projekt Bee během důkladného testování typovými úlohami prokázala dostatečný výkon a spolehlivost pro nasazení v prostředí středně velkých organizací při zachování dobrých ekonomických parametrů řešení. Výhodou je možnost v maximální možné míře využít stávající technické infrastruktury a díky důsledné optimalizaci RDBMS minimalizovat náklady na hardware datového skladu.
Použitá platforma díky své modulárnosti a škálovatelnosti umožňuje efektivní rozvržení projektu do jednotlivých etap a tak optimálně rozložit a zhodnotit nutné investice i zapojení vnitřních zdrojů odběratele. Otevřenost systému a využití standardních technologií (XML, SOAP API) zaručuje jeho snadnou integraci s technologiemi třetích stran.
Použitá literatura
[1] Fayyad, U. M. - Piatetsky-Shapiro, G. a kol.: Advances in Knowledge Discovery and Data Mining. Cambridge MA, 1996
[2] Inmon, W. H.: Building the Data Warehouse. John Willey & Sons, New York 1996
[3] Kimball, R.: Data Warehouse Toolkit. John Willey & Sons, New York 1996
[4] WWW stránky projektu "The BEE Project"
[5] GNU General Public License
[6] WWW stránky projektu "R"
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce