

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEM 11/2003
CRM a segmentace dat
Část 1: Cesta k rozhodnutí o CRM
Martin Šály
Flexibilita a přesnost rozhodovacího procesu závisí na neustálém přílivu kvalitních dat, schopnosti jejich sofistikované analýzy. V tomto kontextu je kladem důraz na analytickou část CRM, která s využitím technik data mining podporuje schopnost provádět série predikcí v reálném čase, měřit a vyhodnocovat zpětnou vazbu a úspěšnost obchodních kampaní i kvality prediktivních modelů.


Naplnit CRM systém analytickými informacemi o zákazníkovi znamená dodat mu tak zvanou Customer Intelligence. Tedy hluboký vhled do struktury a chování zákazníka a integrace tohoto vhledu s kontaktním CRM tak, aby bylo možné ovlivnit chování zákazníka v okamžiku interakce s ním. Odkud ta kvalitní data pro analýzu brát? Hovoříme o datech na úrovni zákazníka, agregovaných z dat transakční úrovně, o všech druzích demografických dat a dalších derivovaných datových elementech. V tomto kontextu vystupuje do popředí pojem segmentace. V tomto článku budeme pod tímto pojmem většinou hovořit o segmentaci zákazníků, to znamená rozčlenění zákazníků na podskupiny, které jsou s ohledem na kritéria segmentace vnitřně relativně homogenní a mezi sebou poměrně heterogenní. Segmentace však zdaleka nepředstavuje pouze segmentaci zákazníků. Segmentovat lze například telefonní hovory podle jejich typů, stroje podle druhů údržby atd. Segmentaci je vhodné chápat primárně jako obchodní úlohu, nikoli „analytické zadání“.
Segmentaci zákazníků dnes využívá každá významnější společnost pro roztřídění zákazníků do podskupin, pro které se sjednocují obchodní a marketingové postupy. Příkladem jednoduchého členění zákazníků banky je jejich rozdělení na privátní klientelu, realizující nejvyšší obraty a zisky, a masový trh, členěný dále na malé/střední podniky a fyzické osoby. K rozhodnutí, že nejcennější privátní klientela bude obsluhována primárně individuálními bankéři a masový trh bude cenovou politikou veden k využití levnějších elektronických kanálů s podporou obchodních balíčků, nejsou jistě nutné pokročilé datové analýzy. Jestliže ale například zvažujeme právě návrh jednotlivých balíčků, může být užitečné rozdělení zákazníků podle více než jedné charakteristiky týkající se způsobu obsluhy.
Pro úvahy o možnosti nabídky úvěrových produktů by mohlo být zajímavé například porovnat zákazníky podle dvou charakteristik:
· průměrná výše zůstatku na všech běžných účtech,
· průměrná výše obratu.
Pokud bychom charakteristiky všech zákazníků vykreslili na plošný diagram (například osa x: výše zůstatku; osa y: výše obratu), mohli bychom ve výsledném „mraku“ bodů hledat několik intervalů na osách x a y, které by nám ve své kombinaci dávaly rozčlenění zákazníků do čtyř, šesti apod. podskupin. Řekněme však, že bychom do našich analýz chtěli zakomponovat ještě další segmentační proměnnou a segmentovat zákazníky podle tří kategorií:
· průměrná výše zůstatku na všech běžných účtech,
· růměrná výše obratu,
· trend obratu na účtech za posledních 12 měsíců.
Ručně-vizuální postup, který je pro jednu nebo dvě segmentační proměnné odůvodnitelný, je zde již prakticky nepoužitelný. Právě v této situaci se uplatňuje data mining s nabídkou technik shlukování (clustering). Shlukovací techniky umožňují po zadání i většího počtu segmentačních proměnných najít shluky (clusters), které odpovídají „nejlepším možným“ segmentům.
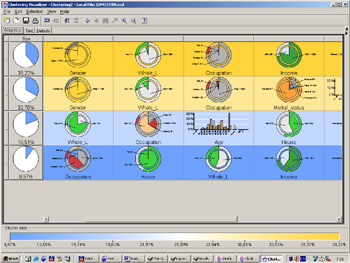
Obr. 1: Shlukovácí diagram (Cluster Description) – v řádcích jsou jednotlivé clustery. V prvním sloupci je uvedena velikost daného clusteru (včetně grafického znázornění). V dalších sloupcích je pak rozložení hodnot jednotlivých atributů v daných clusterech. Dané grafy ukazují vždy rozložení daného atributu uvnitř clusteru (např. výsečové grafy) a dále pro porovnání rozložení toho samého atributu v celém základním souboru (např. na kruhu kolem výsečového grafu). Tím lze určit, jak moc je tento atribut dobrý v odlišení clusteru od celého souboru. Vezměme si jako příklad třetí cluster, jehož velikost je 18,51 % velikosti celého souboru. První uvedený atribut je Whole_L s možnostmi Yes (Ano) – zelená část a No(Ne) – bílá část. V clusteru značně převažuje hodnota Yes (výsečový graf uvnitř), zatímco v celém souboru (kruh okolo výsečového grafu) převažuje bílá, tedy hodnota No. Druhý atribut je Occupation. V daném clusteru převažují důchodci (hodnota Ret) – asi dvě třetiny celého clusteru oproti několika málo procentům v celém souboru. 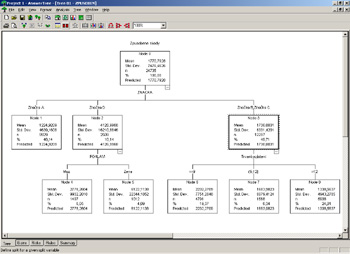
Obr. 2: Rozhodovací strom – způsobené škody v rámci celkového počtu 24 735 pojištěných vozů činí v průměru 1 770 Kč na jednu pojistku. Tyto škody se značně liší v jednotlivých segmentech. Například u majitelů vozu značky A je průměrná výše způsobených škod 1 224 Kč, u vozů značky D je to 4 126 Kč a u dvojice značek B a C to podobné tj.1 730 Kč. U majitelů značky D výše škody dále závisí na pohlaví. Škoda způsobená ženami je průměrně 6 122 Kč a škoda způsobená muži je průměrně 2 778 Kč. U vozů značek B a C má dále rozhodující vliv doba trvání pojištění. Je-li doba trvání pojištění do 9 měsíců (včetně), pak je průměrná způsobená škoda 2 332 Kč, je-li mezi 9 a 12 měsíci, pak je průměrná způsobená škoda 1 683 Kč a konečně pro smlouvy pro vozy této skupiny, které trvají více než rok, je průměrná způsobená škoda 1 338 Kč.
Naplnit CRM systém analytickými informacemi o zákazníkovi znamená dodat mu tak zvanou Customer Intelligence. Tedy hluboký vhled do struktury a chování zákazníka a integrace tohoto vhledu s kontaktním CRM tak, aby bylo možné ovlivnit chování zákazníka v okamžiku interakce s ním. Odkud ta kvalitní data pro analýzu brát? Hovoříme o datech na úrovni zákazníka, agregovaných z dat transakční úrovně, o všech druzích demografických dat a dalších derivovaných datových elementech. V tomto kontextu vystupuje do popředí pojem segmentace. V tomto článku budeme pod tímto pojmem většinou hovořit o segmentaci zákazníků, to znamená rozčlenění zákazníků na podskupiny, které jsou s ohledem na kritéria segmentace vnitřně relativně homogenní a mezi sebou poměrně heterogenní. Segmentace však zdaleka nepředstavuje pouze segmentaci zákazníků. Segmentovat lze například telefonní hovory podle jejich typů, stroje podle druhů údržby atd. Segmentaci je vhodné chápat primárně jako obchodní úlohu, nikoli „analytické zadání“.
Segmentaci zákazníků dnes využívá každá významnější společnost pro roztřídění zákazníků do podskupin, pro které se sjednocují obchodní a marketingové postupy. Příkladem jednoduchého členění zákazníků banky je jejich rozdělení na privátní klientelu, realizující nejvyšší obraty a zisky, a masový trh, členěný dále na malé/střední podniky a fyzické osoby. K rozhodnutí, že nejcennější privátní klientela bude obsluhována primárně individuálními bankéři a masový trh bude cenovou politikou veden k využití levnějších elektronických kanálů s podporou obchodních balíčků, nejsou jistě nutné pokročilé datové analýzy. Jestliže ale například zvažujeme právě návrh jednotlivých balíčků, může být užitečné rozdělení zákazníků podle více než jedné charakteristiky týkající se způsobu obsluhy.
Pro úvahy o možnosti nabídky úvěrových produktů by mohlo být zajímavé například porovnat zákazníky podle dvou charakteristik:
· průměrná výše zůstatku na všech běžných účtech,
· průměrná výše obratu.
Pokud bychom charakteristiky všech zákazníků vykreslili na plošný diagram (například osa x: výše zůstatku; osa y: výše obratu), mohli bychom ve výsledném „mraku“ bodů hledat několik intervalů na osách x a y, které by nám ve své kombinaci dávaly rozčlenění zákazníků do čtyř, šesti apod. podskupin. Řekněme však, že bychom do našich analýz chtěli zakomponovat ještě další segmentační proměnnou a segmentovat zákazníky podle tří kategorií:
· průměrná výše zůstatku na všech běžných účtech,
· růměrná výše obratu,
· trend obratu na účtech za posledních 12 měsíců.
Ručně-vizuální postup, který je pro jednu nebo dvě segmentační proměnné odůvodnitelný, je zde již prakticky nepoužitelný. Právě v této situaci se uplatňuje data mining s nabídkou technik shlukování (clustering). Shlukovací techniky umožňují po zadání i většího počtu segmentačních proměnných najít shluky (clusters), které odpovídají „nejlepším možným“ segmentům.
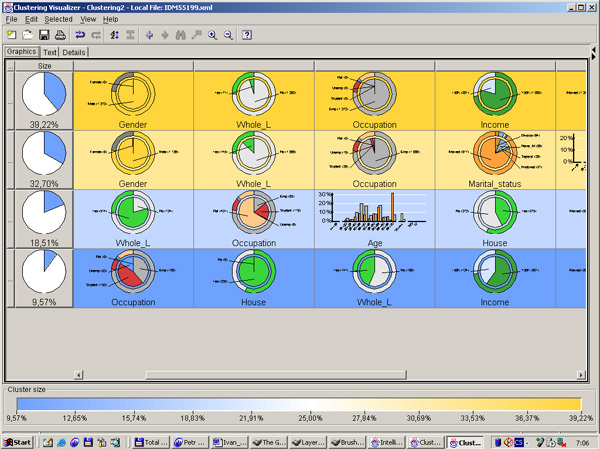
Obr. 1: Shlukovácí diagram (Cluster Description) – v řádcích jsou jednotlivé clustery. V prvním sloupci je uvedena velikost daného clusteru (včetně grafického znázornění). V dalších sloupcích je pak rozložení hodnot jednotlivých atributů v daných clusterech. Dané grafy ukazují vždy rozložení daného atributu uvnitř clusteru (např. výsečové grafy) a dále pro porovnání rozložení toho samého atributu v celém základním souboru (např. na kruhu kolem výsečového grafu). Tím lze určit, jak moc je tento atribut dobrý v odlišení clusteru od celého souboru. Vezměme si jako příklad třetí cluster, jehož velikost je 18,51 % velikosti celého souboru. První uvedený atribut je Whole_L s možnostmi Yes (Ano) – zelená část a No(Ne) – bílá část. V clusteru značně převažuje hodnota Yes (výsečový graf uvnitř), zatímco v celém souboru (kruh okolo výsečového grafu) převažuje bílá, tedy hodnota No. Druhý atribut je Occupation. V daném clusteru převažují důchodci (hodnota Ret) – asi dvě třetiny celého clusteru oproti několika málo procentům v celém souboru.
Počet segmentů
Některé ze segmentačních algoritmů umožňují navrhnout optimální počet segmentů v určitém rozsahu, jiné vyžadují pevně zadat počet segmentů předem. Automatizované nalezení počtu segmentů může být sice vhodné pro první přiblížení, v praxi však často dochází k ruční korekci počtu segmentů. Dostáváme se k hlavnímu kritériu úspěšnosti segmentace. Dobrá segmentace je obchodně užitečná. Pokud rozdělením původně jednoho segmentu „Profitabilní“ vzniknou dva nové segmenty „Profitabilní s malým rizikem“ a „Profitabilní s vyšším rizikem“, bude se nejspíše jednat o užitečné rozčlenění. Budeme-li počet segmentů dále zvyšovat, může se ukázat, že při příliš velkém počtu segmentů již další rozčleňování neukáže žádné obchodně zajímavé odlišnosti, nebo je počet zákazníků v některém shluku je již natolik malý, že využití takovéhoto segmentu rovněž postrádá marketingově-obchodní smysl.
Obchodní motivace pro segmentaci
Uvedli jsme, že obecnou motivací k segmentaci zákazníků je jejich rozčlenění na vnitřně homogenní a navzájem heterogenní podskupiny pro cílení obchodního a marketingového přístupu. Nyní uveďme několik konkrétnějších přístupů k segmentaci zákazníků:
1. Hodnotová segmentace zákazníků
Segmentačními proměnnými jsou ukazatele hodnoty zákazníka. Podrobnější popis přesahuje rozsah tohoto článku. Uveďme zde alespoň to, že hodnota zákazníka může být měřena například kritérii tržba, profit, riziko, loajalita nebo obsluha. V případě některých kritérií (tržba) hodnoty lze nalézt proměnné, které budou vystupovat přímo jako segmentační, v případě jiných kritérií (loajalita) se hledají takové proměnné nebo jejich kombinace, které v dostatečné míře dané kritérium vyjadřují.
Hodnotová segmentace je účelným prvním krokem pro iniciální rozčlenění portfolia zákazníků na hlavní skupiny (popřípadě ověření takového již existujícího rozdělení) a bývá doplňována dalšími analýzami, například níže uvedenou behaviorální segmentací.
2. Behaviorální segmentace zákazníků
V tomto přístupu k segmentaci se pokoušíme primárně odhlédnout od hodnoty zákazníka a zaměřujeme se na jeho „chování“, čímž míníme například počet, druh a způsob použití jednotlivých produktů. Například u telekomunikační společnosti můžeme jako segmentační proměnné pro behaviorální segmentaci použít:
· procento lokálních volání,
· procento vnitrostátních volání,
· procento mezinárodních volání,
· procento volání na mobilní telefony.
Behaviorální segmentaci není vždy účelné oddělovat od segmentace hodnotové; výhodná je jejich kombinace. Například po celkové hodnotové segmentaci zákazníků lze na vybrané podskupiny uplatnit segmentaci behaviorální.
3. Segmentace zákazníků pro odhalení nestandardního chování
Tento typ segmentace se využívá pro analýzu a detekci podvodného chování nebo pro detekci rizika určitého druhu. Zatímco pro uvedené dva druhy segmentací je typický relativně malý počet segmentů (nejčastěji 6 až 15), aby pro obchodně-marketingové účely byl jejich počet zvládnutelný, zde se často pracuje s větším množstvím segmentů a hledají se spíše menší, neobvykle se chovající skupiny zákazníků.
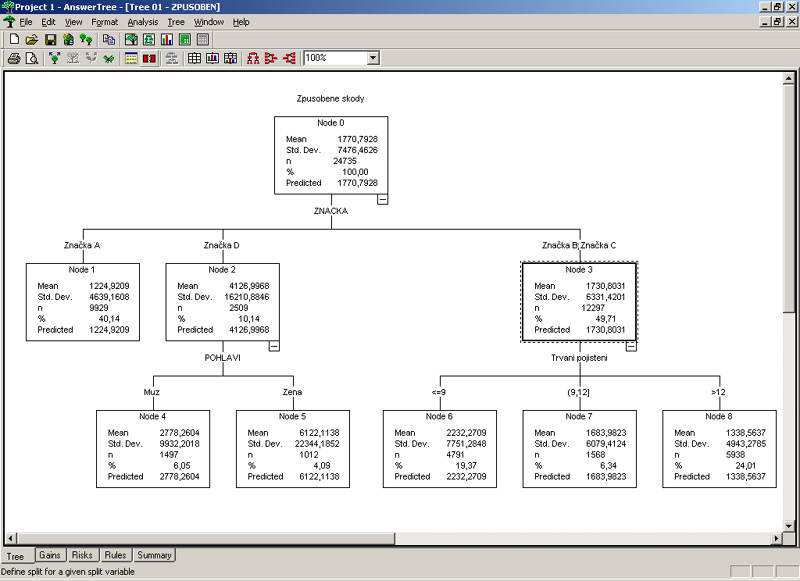
Obr. 2: Rozhodovací strom – způsobené škody v rámci celkového počtu 24 735 pojištěných vozů činí v průměru 1 770 Kč na jednu pojistku. Tyto škody se značně liší v jednotlivých segmentech. Například u majitelů vozu značky A je průměrná výše způsobených škod 1 224 Kč, u vozů značky D je to 4 126 Kč a u dvojice značek B a C to podobné tj.1 730 Kč. U majitelů značky D výše škody dále závisí na pohlaví. Škoda způsobená ženami je průměrně 6 122 Kč a škoda způsobená muži je průměrně 2 778 Kč. U vozů značek B a C má dále rozhodující vliv doba trvání pojištění. Je-li doba trvání pojištění do 9 měsíců (včetně), pak je průměrná způsobená škoda 2 332 Kč, je-li mezi 9 a 12 měsíci, pak je průměrná způsobená škoda 1 683 Kč a konečně pro smlouvy pro vozy této skupiny, které trvají více než rok, je průměrná způsobená škoda 1 338 Kč.
Obchodní využití výsledků segmentace
Výše uvedená kritéria jsou nutnou, ale nepostačující podmínkou „dobré“ segmentace. Hlavním kritériem je již zmíněná „obchodní užitečnost“. Výsledky segmentace profilují, tj. popíší se všechny zajímavé odchylky segmentačních proměnných od průměrného rozložení v celé množině případů. V rámci popisu segmentů se zahrnou i zajímavé odchylky proměnných, které nebyly zvoleny jako segmentační. Výsledky profilování vedou k označení segmentů krátkým výstižným názvem a výsledná vyprofilovaná segmentace musí projít obchodní oponenturou. Není-li shledána „dobrou“, iterativně se optimalizuje.
Uveďme některé základní příklady obchodního použití výsledků segmentace:
· úvodní nalezení typologií zákazníků,
· rozdělení zákazníků podle hodnoty pro stanovení obecného obchodního přístupu,
· hledání potenciálu cross-sell, segmentace se posléze doplňuje dalšími technikami (například analýzou nákupního košíku),
· sledování změn chování zákazníků – segmentační model se periodicky skóruje a sledují se migrační proudy mezi jednotlivými segmenty.
Příklad – Segmentace OPV
V letošním roce je hodně diskutovaní otázka povinného ručení v souvislostí s deregulaci sazeb pojištění OPV, která proběhla v minulém roce. Pojišťovny hledají nejoptimálnější sazby OPV, což se neobejde bez analýzy údajů o pojištěncích a jejich „škodních případech“, které v minulých letech pojišťovny nashromáždily.
Pojišťovny hledají odpověď na otázky:
· Jak optimalizovat výši sazeb povinného ručení?
· Kteří klienti jsou nejvíce rizikoví?
· U kterých klientů je naopak nejmenší pravděpodobnost pojistné události?
· Existuje segment klientů, který bychom raději neměli pojišťovat?
Požadavek na optimální výši sazby pro každého klienta, respektive skupiny klientů vede v praktickém obchodním životě na segmentační úlohu. To znamená rozdělit klienty na základě jejich charakteristik a atributů pojištěného vozidla do rozumného počtu segmentů (skupin), pro něž budou určené odpovídající sazby OPV. Stanovovat sazbu pro každého klienta individuálně by sice teoreticky bylo také možné, ale prakticky velmi náročné. Problémem plně individuálního přístupu je kromě technické a organizační složitosti, také obtížná marketingová podpora takového pojistného produktu.
Jak určit optimální segmenty? Řešení je ve využití dat o pojištění za minulé roky. Většina pojišťoven disponuje údaji o pojistných smlouvách a pojistných událostech minimálně za jeden až dva roky. Tyto data je možné využít pro analýzu optimálního nastavení sazeb. Zdálo by se, že nejjednodušší je vytvořit sady reportů a s jejich pomocí pak analytici budou hledat vliv charakteristik klienta a pojištěného vozidla na výši škody – rizikovost.
Problémem je, jak klasickými reporty prozkoumat všechny možné kombinace sledovaných atributů, jimiž jsou například věk klienta, jeho pohlaví, podnikání, značka vozu, provedení vozu, objem, výkon, hmotnost či způsob použití vozidla.
Řešení je v segmentaci s nasazením dalšího typu data mining technik využívajících řídicí proměnnou, například techniky rozhodovacího stromu. Ilustrační obrázek představuje výsledek data mining – zobrazení metody rozhodovací strom. Tato metoda umožňuje rychlou a správnou identifikaci hledaných segmentů. Pojistní analytici mohou velice rychle rozpoznat struktury a kombinace faktorů ovlivňujících rizikovost, a to do hloubky, která byla dříve jen těžko představitelná. Navržené sazby potom mohou přesně odrážen vývoj na trhu a specifika českých podmínek povinného ručení.
Autor článku, Martin Šály, pracuje jako Data Mining Manažer ve společnosti Adastra Corporation.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce