

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (36)
- WMS (29)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |

Partneři webu

IT SYSTEM 5/2003


V minulém díle tohoto seriálu byla rámcově vymezena problematika Business Intelligence s konstatováním, že se jedná o proces transformace dat v obchodní informace. Dále byla věnována pozornost sběru dat a jejich přípravě. Cílem 2. dílu této série je podrobněji popsat krok, který jsme nazvali analýza dat (obr 1.) Kromě popisu základní postupů se zmíníme také o hlavních úskalích této fáze. Přestože by název dnešního dílu mohl vyvolat dojem, že se jedná o technologickou fázi, i pro tento krok platí, stejně tak jako pro celé řešení Business Inteligence, nutnost úzké vazby na obchodní cíle a procesy a z toho vyplývající součinnost.
Jako příklad si uveďme telekomunikační společnost, která se dnes pohybuje na vysoce konkurenčním trhu, který je již do značné míry pokryt. Tato situace nutí management modifikovat stávající marketingovou strategii. Hlavním cílem se stává udržet si stávající zákaznický kmen a systematicky jej rozšiřovat. Vzhledem k tomu, že obdobnou strategii uplatňují také ostatní hráči na trhu, je jedním z možných rozhodnutí jak čelit této situaci spuštění programu na potlačení odlivu stávajících zákazníků. Protože je známo, že odchod klienta je často otázkou několika dní a je doprovázen určitými měřitelnými změnami chování klienta, dostává analytické oddělení úkol najít takový model, který bude s vysokou pravděpodobností schopen identifikovat klienty, u kterých se začnou projevovat symptomy, které naznačují úmysl odejít. Úkolem není takovýto model pouze nalézt, ale především ověřit jeho účinek. V pozitivním případě společnost získává nástroj, který jí umožní získat několik cenných dní na to, aby klienta přiměla změnit jeho rozhodnutí. Proces dolování takovýchto informací je to, čemu se budeme v tomto díle věnovat. Tento proces se nazývá Data Mining.
Stanovení cílů
Stejně tak jako tomu bylo v uvedeném příkladu, nutným předpokladem, než začneme s vlastní analýzou dat, je mít definici obchodního cíle, který by měl být Data Miningovým projektem podpořen nebo přímo řešen. Typické obchodní cíle, které lze přímo podpořit Data Mining projekty, mohou být následující:
. optimalizace nákladů a zvýšení účinnosti marketingových kampaní,
. snížení nebo eliminace počtu rizikových zákazníků,
. zvýšení profitability stávajících zákazníků,
. křížový a následný prodej,
. udržení zákazníků,
. zlepšení spokojenosti zákazníků.

Business Intelligence II. díl:
Data Mining
Tomáš Bárta
V minulém díle tohoto seriálu byla rámcově vymezena problematika Business Intelligence s konstatováním, že se jedná o proces transformace dat v obchodní informace. Dále byla věnována pozornost sběru dat a jejich přípravě. Cílem 2. dílu této série je podrobněji popsat krok, který jsme nazvali analýza dat (obr 1.) Kromě popisu základní postupů se zmíníme také o hlavních úskalích této fáze. Přestože by název dnešního dílu mohl vyvolat dojem, že se jedná o technologickou fázi, i pro tento krok platí, stejně tak jako pro celé řešení Business Inteligence, nutnost úzké vazby na obchodní cíle a procesy a z toho vyplývající součinnost.
Jako příklad si uveďme telekomunikační společnost, která se dnes pohybuje na vysoce konkurenčním trhu, který je již do značné míry pokryt. Tato situace nutí management modifikovat stávající marketingovou strategii. Hlavním cílem se stává udržet si stávající zákaznický kmen a systematicky jej rozšiřovat. Vzhledem k tomu, že obdobnou strategii uplatňují také ostatní hráči na trhu, je jedním z možných rozhodnutí jak čelit této situaci spuštění programu na potlačení odlivu stávajících zákazníků. Protože je známo, že odchod klienta je často otázkou několika dní a je doprovázen určitými měřitelnými změnami chování klienta, dostává analytické oddělení úkol najít takový model, který bude s vysokou pravděpodobností schopen identifikovat klienty, u kterých se začnou projevovat symptomy, které naznačují úmysl odejít. Úkolem není takovýto model pouze nalézt, ale především ověřit jeho účinek. V pozitivním případě společnost získává nástroj, který jí umožní získat několik cenných dní na to, aby klienta přiměla změnit jeho rozhodnutí. Proces dolování takovýchto informací je to, čemu se budeme v tomto díle věnovat. Tento proces se nazývá Data Mining.
Stanovení cílů
Stejně tak jako tomu bylo v uvedeném příkladu, nutným předpokladem, než začneme s vlastní analýzou dat, je mít definici obchodního cíle, který by měl být Data Miningovým projektem podpořen nebo přímo řešen. Typické obchodní cíle, které lze přímo podpořit Data Mining projekty, mohou být následující:
. optimalizace nákladů a zvýšení účinnosti marketingových kampaní,
. snížení nebo eliminace počtu rizikových zákazníků,
. zvýšení profitability stávajících zákazníků,
. křížový a následný prodej,
. udržení zákazníků,
. zlepšení spokojenosti zákazníků.
|
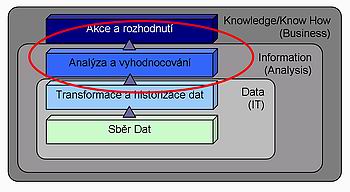
Obchodní cíle (Business Goals) jsou obvykle definovány obchodním jazykem, proto je nutné je transformovat do Data Mining cílů, které jsou formulovány technickým jazykem. Toto je důležitá úloha lidí stojících na rozhraní obchodu a IT, je to úloha datových analytiků. Zní-li například obchodní cíl "Zvýšit prodej stávajícím zákazníkům", mohl by cíl Data Miningu znít takto: "Najděte odpověď na otázku: U jaké skupiny zákazníků existuje vysoká pravděpodobnost, že si pořídí produkt X, a to na základě jejich demografických charakteristik (věk, plat, lokalita) a stavu jejich současného produktového portfolia, které využívají?"
Zachycení a popsání transparentní souvislosti mezi obchodními a Data Mining cíli je velice důležitým krokem takovýchto projektů a vynecháním tohoto kroku se vystavujeme riziku, že bude vynaloženo velké úsilí na získání správných odpovědí na špatné otázky.
Dalšími užitečnými výstupy této iniciální fáze Data Mining projektů by měly být:
. inventář potřebných a existujících zdrojů (lidských, datových, technologických atd.),
. Popis rizik a jejich případné ošetření,
. Projektový plán.
Výběr zdrojů dat a příprava pro modelování
Máme-li za sebou iniciální fázi a jsou-li jasně popsané Data Mining cíle je čas poohlédnout se po datech, která jsou centrálním vstupním aktivem pro jakékoli snažení v tomto směru. Tato fáze je mnohem jednodušší, vlastní-li společnost datový sklad, který obsahuje většinu potřebných dat. Pokud tomu tak není, je obvykle nutné jít pro data do několika datových zdrojů, ve kterých jsou data rozptýlena. Celá úloha přípravy dat tak může být násobně nákladnější a s nejvyšší pravděpodobností bude obnášet navíc úlohy jako:
. identifikace a výběr datových zdrojů,
. sběr a popis dat,
. ohodnocení a ověření dat z hlediska kvality, integrity atd.,
. čištění a konsolidace dat.
Data Mining většinou pracuje s klientskými daty, a proto se pro přehled zmiňme o základních typech dat, se kterými se pracuje:
. Demografická data - věk, bydliště, vzdělání, národnost, pohlaví, počet dětí atd.
. Behaviorální data - vystihují chování a zvyky zákazníka a jsou jimi například produktová struktura nebo nákupní košík, množství a objem provedených transakcí, využívané distribuční kanály atd.
Z našeho pohledu má každý typ dat různý charakter a má pro různé úlohy různou vypovídací schopnost.
Předpokládejme v tuto chvíli pro jednoduchost situaci, kdy má společnost datový sklad, který potřebná data obsahuje, a je úlohou datového analytika, aby identifikoval, která data budou pro následné modelování použita. Jinými slovy datový analytik musí na základě Data Mining cílů vytipovat, ve kterých atributech a datech, jež jsou k dispozici, je zakódovaná odpověď, kterou hledáme. Výsledkem je obvykle popis datové věty, podle které bude nutné připravit extrakt pro modelování.
Datová věta obvykle obsahuje desítky až stovky atributů. Zdaleka neplatí, že se jedná o pouhé "vykopírování" hodnot ze zdrojového systému, ale naopak při její konstrukci dochází k různým transformacím, např. k průměrování hodnot, normalizaci, výpočtům procent, výpočtům z několika zdrojových polí do jednoho, agregaci, doplnění chybějících a eliminaci extrémních hodnot atd. Správná konstrukce datové věty je nutnou podmínkou pro úspěch mise. Je také patrné, že nevystačíme s pouhou znalostí dat, ale je nutné znát velice dobře obchodní problematiku.
Máme-li definováno, jaká data budou pro modelování použita a jak se mají připravit, přechází úloha na čas do rukou IT specialistů, jejichž úkolem je získat ze systémů nebo datového skladu data v potřebné struktuře a formátu. Úlohu můžeme nazvat příprava datového extraktu nebo extrakce dat. Vlastní extrakt může mít různou podobu (textový soubor, databázová tabulka atp.), záleží na typu použitého DataMining software.
| |
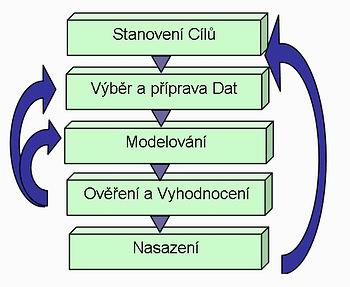
Modelování - Výstavba modelu a vyhodnocení
Máme-li připravena data, můžeme začít s vlastním modelováním, neboli výběrem,výstavbou a vyhodnocením výpočetních a statistických modelů k získání výsledků.
Prvním krokem je výběr modelovací techniky. Typicky se používají následující metody:
. regresní modely (lineární, nelineární),
. neuronové síťě,
. shlukové analýzy (clustering),
. rozhodovací stromy a expertní metody.
Je třeba mít na paměti, že každá modelovací metoda má jiné požadavky na formát a typ dat, a tudíž je dobré již v úvodu vytipovat, které metody budou použity. Pro jednu úlohu se může prověřovat několik metod a jejich kombinací. Z těchto a dalších důvodů je patrné, že Data Mining projekt může několikrát oscilovat mezi přípravou dat a modelováním, viz obr. Životní cyklus Data Mining porojektů.
Analytici následně v závislosti na vybrané metodě rozdělí data do 2 souborů/množin:
. Modelovací set - množina záznamů nad kterými se hledá a staví odpovídající model.
. Ověřovací set - množina záznamů nad kterými se model ověřuje.
Dále probíhá vlastní výstavba modelu, nebo-li nastavení parametrů a přizpůsobení modelovací metody datům, tak, aby "fungovala" na datech určených pro výstavbu modelu, tj na modelovacím setu. V tomto kroku kromě jiného analytik provádí:
. parametrizování a výstavbu modelů,
. vzájemné vyhodnocování a porovnávání nalezených modelů,
. redukci a vylučování proměnných, které jsou silně korelovány s jinými nebo nemají vliv na výsledek.
Rizikem tohoto kroku může být tzv. "overfitting", viz Základní pojmy.
Ověření modelu
Ověření modelu/modelů je zásadní zpětná vazba a kontrolní mechanizmus na cestě k našemu cíli. Jednoduše řečeno probíhá ověření modelu nad daty, která jsme před modelem dosud skrývali, tj. na ověřovacím setu.
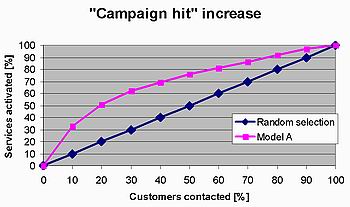
Dejme tomu, že naším DataMining cílem je na základě struktury vlastněných služeb a produktů konkrétního klienta "předpovědět", zda by klient kladně zareagoval na konkrétní nabídku služby X a aktivoval ji. Protože kampaň na stejnou nebo obdobnou službu již probíhala, máme k dispozici její výsledky, a tedy i data pro modelování a ověřování. Z předchozích kroků jsme se dopracovali k modelu, o kterém se domníváme, že by mohl být kandidátem pro tuto úlohu. Při ověřování budeme model konfrontovat s ověřovacími daty a porovnáme skutečnou reakci klientů s výsledky modelu. Vyhodnocení je možné následně provést pomocí tzv. decilové analýzy a jednoduše graficky vizualizovat, viz obr. 3. Interpretace grafu je v tomto případě taková, že v prvních 40 % klientů setříděných dle pravděpodobnosti (dle modelu) aktivace služby X sestupně bychom našli přibližně 70 % z těch, kteří si službu skutečně aktivovali.
| |
Nasazení
Nasazením se rozumí implementace modelu do rutinního provozu, včetně režimu údržby, monitoringu a aktualizace modelu. Vzhledem k tomu, že nasazení modelu může mít značný vliv na obchodní výsledky firmy, speciálně v oblasti modelů aplikovaných na posuzování rizika, je nutné při jeho nasazování postupovat se zvýšenou opatrností. Často užívanou metodou je systém champion versus challenger, viz Základní pojmy.
Je-li model nasazen, je nutné jej neustále monitorovat, vyhodnocovat jeho obchodní přínos a případně jej aktualizovat tak, jak získáváme další informace, které mohou zpřesňovat naše rozhodnutí.
Závěr
Závěrem je možné říci, že výše popsaný životní cyklus Data Mining projektů v sobě podchycuje metodiky a zkušenosti z různých zdrojů a stejně jako je tomu u jakýchkoli řešení patřících do kategorie BI, platí pro analýzu dat dvojnásob fakt, že ji nelze úspěšně provádět odtrženě od obchodního kontextu a obchodních cílů společnosti.
V oblastech, kde je získání nového zákazníka stále obtížnější a ztráta je zároveň stále stejně jednoduchá, v oborech, kde firmy potřebují statisíce zákazníků k tomu aby byly ziskové a současně chtějí každému poskytnout služby "na míru" a v době kdy se služby poskytují s minimálním anebo vůbec žádným fyzickým kontaktem dodavatele a zákazníka, který se stává pouhým statistickým údajem, přestává být analytický přístup k marketingu, vývoji produktů, k řízení rizik nebo k upevňování vztahu s klientem nadstandardem, ale stává nutností v boji o ekonomické přežití.
Ve zbývajících dílech se zmíníme o některých konkrétních aplikacích BI řešení v praxi.
Základní pojmy
Overfitting - zjednodušeně stav, kdy model nezachytil skutečné závislosti mezi daty, ale v podstatě se je "naučil nazpaměť". Výsledkem je, že nedokáže generalizovat a selhává na jakýchkoli jiných datech, než na modelovacích.
Champion vs. Challenger - metoda nasazování a ověřování nového rozhodovacího modelu (Challenger) proti původnímu (Champion). V principu jde o to, že část zákazníků je obsloužena modelem původním a část novým. Následně dochází k porovnání tam, kde modely reagovaly různě.
Autor článku, Tomáš Bárta, působí jako Project Manager ve společnosti NESS.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy




 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 1 | 2 | 3 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
IT Systems podporuje
Formulář pro přidání akce
Další vybrané akce