

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Hlavní partner sekce

Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEMS 11/2006 , AI a Business Intelligence
 Také vám vadí vysoké pojistné vašeho auta? Máte pocit, že vy jen platíte a zároveň slyšíte o těch „šikovnějších“, kteří dokáží na nehodě vydělat, či ji dokonce záměrně zinscenovat? Bohužel je tomu tak, že při placení pojistného jsou v něm kalkulovány i neoprávněné výplaty pojistného, a tím pádem je pojistné vyšší, než by mohlo být. Naštěstí se technologie mění a pojišťovny s nimi. Pojišťovny implementují a neustále vylepšují inteligentní systémy, které dokáží identifikovat podezřelé případy a následně se s nimi vypořádat. Díky tomu dokáží pojišťovny zlevnit své pojistné a mohou tak být konkurenceschopnější při nasazování svých sazeb.
Také vám vadí vysoké pojistné vašeho auta? Máte pocit, že vy jen platíte a zároveň slyšíte o těch „šikovnějších“, kteří dokáží na nehodě vydělat, či ji dokonce záměrně zinscenovat? Bohužel je tomu tak, že při placení pojistného jsou v něm kalkulovány i neoprávněné výplaty pojistného, a tím pádem je pojistné vyšší, než by mohlo být. Naštěstí se technologie mění a pojišťovny s nimi. Pojišťovny implementují a neustále vylepšují inteligentní systémy, které dokáží identifikovat podezřelé případy a následně se s nimi vypořádat. Díky tomu dokáží pojišťovny zlevnit své pojistné a mohou tak být konkurenceschopnější při nasazování svých sazeb.


Proto se pojišťovny neobejdou bez kvalitních procesů podporovaných inteligentním systémem pro detekci pojistných podvodů. Podvody mohou být páchány jak pojistníky, tak zaměstnanci (zejména likvidátory), nebo nejčastěji oběma stranami zároveň. Další formou podvodu je zneužití systému provizí – existují obchodní modely kdy externí prodejce dostává za realizaci stejného obchodního případu vyšší provizi než zaměstnanec pracující na přepážce. Pokud se zaměstnanec a prodejce domluví a realizují všechny výnosné obchodní případy prostřednictvím prodejce, jedná se z hlediska finanční instituce o podvod, který způsobuje významné ztráty.
Pojišťovny však dnes nejsou vůči těmto podvodům zcela bezbranné. Existují systémy, které mohou podvody detekovat, a často jim i zabránit. Konkrétní aplikace fraud management systémů jsou tak různorodé, jak různorodé jsou podvody samotné. Všechny ale pracují na principech využívajících podobné postupy.
Druhou cestou je vytvářet prediktivní modely na základě dostatečně velkého množství dat popisující historii a chování na úrovni jednotlivých klientů či pojistných událostí. Tato technika vychází z principů data miningu a opírá se o klasifikační modely (rozhodovací stromy, neuronové sítě, logistická regrese, support vector machines a další). Prediktivní modely mohou najít i skryté závislosti v datech, které nejsou explicitně známy, a tudíž nemohou být přepsány ve formě expertních pravidel. Na druhé straně může být problémem (hlavně při zavádění systému) nedostatek relevantních dat pro vytváření modelů.
Který z přístupů je výhodnější? Na tuto otázku neexistuje jednoznačná odpověď, záleží na podmínkách pro vytváření systému (kvalita dat, integrace informačních systémů, doménová znalost expertů a další). Pokud se podíváme na počty nasazení jednotlivých systémů, zjistíme převahu pravidlových systémů, i když dataminingové systémy jejich náskok stahují. Výhodou dataminingových systémů je jejich schopnost „učit se“ v čase. Na základě průběžného vyhodnocování úspěšnosti svých vlastních předpovědí (porovnáním předpovědi a reality) jsou schopny automaticky měnit parametry svého modelu tak, aby docházelo k neustálému zvyšování úspěšnosti. Nevýhodou se jeví relativně komplikované nastavení a netransparentnost vazby mezi vstupy a výstupy. Zjistit, proč systém vyhodnotil chování jako podezřelé, je pro normálního smrtelníka neřešitelný úkol. Z výše uvedených důvodů se v poslední době začíná objevovat trend hybridních systémů, které kombinují oba přístupy.
Při použití prediktivní metody identifikace podvodu se ale může stát, že za rizikového je označen zákazník, pro něhož je chování běžně charakterizované jako potenciálně rizikové jednáním běžným. Proto je vhodné, aby predikce rizikovosti každého chování byla doplněna o informaci, jak je toto chování standardní z hlediska konkrétního zákazníka či zástupce pojišťovny. Chování, které je obecně považováno za rizikové, avšak pro daného zákazníka či zástupce typické, pak nebude považováno za potenciální podvod. Navíc i nové typy podvodů, s nimiž systém ještě nemá zkušenost, a prediktivní model je tedy nemůže odhalit, často poruší typické chování zákazníka nebo zástupce, a budou tak vyhodnoceny jako potenciální podvod. Typické chování každého zákazníka či zástupce je uloženo v takzvaných profilech. Kombinací obecné míry rizikovosti se specifickou mírou standardnosti chování pro daného zákazníka a zástupce pojišťovny lze dosáhnout nejlepších výsledků při detekci podvodu a vyhnout se falešným poplachům.
Vlastní nasazení fraud management systému je velmi jednoduché. Aktuální data o projednávané pojistné události se aplikují na vytvořený model rizikového chování. Ten určí rizikové skóre daného případu. Skóre případu pak indikuje váhu, s jakou je daný případ rizikový, a podle nastavených kritérií je podrobněji zkoumán, zda se nejedná o podvod.
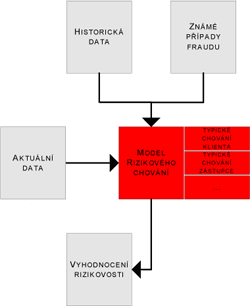
Obr. 1: Zjednodušené schéma fungování fraud management systému
Popsané metody vyhodnocování podezřelých pojistných událostí jsou aplikovatelné na různé typy podvodů. Například při identifikaci podvodů se sledují následující ukazatele.
Pojišťovny sledují typ škody, její okolnosti ve vztahu k lokálním podmínkám, jako třeba počasí v dané době a místě, likvidátora, pojištěnce, další účastníky škodní události a jejich vztah k pojištěnci, dobu vyřízení, kvalitu dokumentace škody, frekvenci škodních událostí a výši dané škody. Dále se sleduje, zda škodní událost nenásleduje těsně po uzavření smlouvy, případně před zaplacením pojistného, po dodatečném připojištění, zda se neobjevuje opakovaná výplata na jeden účet a další.
Banka při odhalování podezřelých transakcí sleduje, zda se jedná o první nákup, kolik transakcí udělal zákazník v posledních 30 dnech, zda se shoduje adresa, na kterou se doručuje zboží a na kterou se zasílá účet, existence IP adresy, ze které je objednávka provedena, typ nakoupeného zboží a jeho množství, žádost o expresní doručení zboží. Podobně banka sleduje u kreditních karet typická místa použití, typické pořizované zboží, frekvenci použití, výši částky transakce, čas transakce, nezdařené autorizace transakcí a další ukazatele.
Nižší pojistné s fraud managementem
Jan Kout
Také vám vadí vysoké pojistné vašeho auta? Máte pocit, že vy jen platíte a zároveň slyšíte o těch „šikovnějších“, kteří dokáží na nehodě vydělat, či ji dokonce záměrně zinscenovat? Bohužel je tomu tak, že při placení pojistného jsou v něm kalkulovány i neoprávněné výplaty pojistného, a tím pádem je pojistné vyšší, než by mohlo být. Naštěstí se technologie mění a pojišťovny s nimi. Pojišťovny implementují a neustále vylepšují inteligentní systémy, které dokáží identifikovat podezřelé případy a následně se s nimi vypořádat. Díky tomu dokáží pojišťovny zlevnit své pojistné a mohou tak být konkurenceschopnější při nasazování svých sazeb. Proč systémy na odhalování podvodů?
Pojistné podvody trápí v nějaké míře každou pojišťovnu na světě. Podle vyjádření odborné veřejnosti až 15 % nahlášených všech pojistných událostí je podvodných. Asi největším lákadlem pro pojistný podvod jsou události spojené s pojištěním motorových vozidel. Je uváděno, že až 20 % pojistných událostí tohoto typu je v České republice podvodných. Při vyplácení pojistného okolo dvaceti miliard korun ročně to znamená, že na pojistné podvody připadají čtyři miliardy korun! Jen poměrně malou část se podaří odhalit a většina je neoprávněně vyplacena.Proto se pojišťovny neobejdou bez kvalitních procesů podporovaných inteligentním systémem pro detekci pojistných podvodů. Podvody mohou být páchány jak pojistníky, tak zaměstnanci (zejména likvidátory), nebo nejčastěji oběma stranami zároveň. Další formou podvodu je zneužití systému provizí – existují obchodní modely kdy externí prodejce dostává za realizaci stejného obchodního případu vyšší provizi než zaměstnanec pracující na přepážce. Pokud se zaměstnanec a prodejce domluví a realizují všechny výnosné obchodní případy prostřednictvím prodejce, jedná se z hlediska finanční instituce o podvod, který způsobuje významné ztráty.
Pojišťovny však dnes nejsou vůči těmto podvodům zcela bezbranné. Existují systémy, které mohou podvody detekovat, a často jim i zabránit. Konkrétní aplikace fraud management systémů jsou tak různorodé, jak různorodé jsou podvody samotné. Všechny ale pracují na principech využívajících podobné postupy.
Principy fraud management systému
V zásadě existují dva rozdílné přístupy k vytváření fraud management systému. Je možné systém vytvořit na základě expertních pravidel, která popisují zvýšená rizika podvodu. Expertní pravidla jsou vytvářena na základě expertních znalostí a zkušeností. Při vytváření takového systému hrají klíčovou roli znalosti a zkušenosti zaměstnanců pojišťoven, kteří dokáží identifikovat podezřelé indicie. Hlavní výhodou tohoto přístupu je jasná transparentnost mezi vstupy a výstupy odrážející zkušenost ve formě srozumitelných pravidel.Druhou cestou je vytvářet prediktivní modely na základě dostatečně velkého množství dat popisující historii a chování na úrovni jednotlivých klientů či pojistných událostí. Tato technika vychází z principů data miningu a opírá se o klasifikační modely (rozhodovací stromy, neuronové sítě, logistická regrese, support vector machines a další). Prediktivní modely mohou najít i skryté závislosti v datech, které nejsou explicitně známy, a tudíž nemohou být přepsány ve formě expertních pravidel. Na druhé straně může být problémem (hlavně při zavádění systému) nedostatek relevantních dat pro vytváření modelů.
Který z přístupů je výhodnější? Na tuto otázku neexistuje jednoznačná odpověď, záleží na podmínkách pro vytváření systému (kvalita dat, integrace informačních systémů, doménová znalost expertů a další). Pokud se podíváme na počty nasazení jednotlivých systémů, zjistíme převahu pravidlových systémů, i když dataminingové systémy jejich náskok stahují. Výhodou dataminingových systémů je jejich schopnost „učit se“ v čase. Na základě průběžného vyhodnocování úspěšnosti svých vlastních předpovědí (porovnáním předpovědi a reality) jsou schopny automaticky měnit parametry svého modelu tak, aby docházelo k neustálému zvyšování úspěšnosti. Nevýhodou se jeví relativně komplikované nastavení a netransparentnost vazby mezi vstupy a výstupy. Zjistit, proč systém vyhodnotil chování jako podezřelé, je pro normálního smrtelníka neřešitelný úkol. Z výše uvedených důvodů se v poslední době začíná objevovat trend hybridních systémů, které kombinují oba přístupy.
Při použití prediktivní metody identifikace podvodu se ale může stát, že za rizikového je označen zákazník, pro něhož je chování běžně charakterizované jako potenciálně rizikové jednáním běžným. Proto je vhodné, aby predikce rizikovosti každého chování byla doplněna o informaci, jak je toto chování standardní z hlediska konkrétního zákazníka či zástupce pojišťovny. Chování, které je obecně považováno za rizikové, avšak pro daného zákazníka či zástupce typické, pak nebude považováno za potenciální podvod. Navíc i nové typy podvodů, s nimiž systém ještě nemá zkušenost, a prediktivní model je tedy nemůže odhalit, často poruší typické chování zákazníka nebo zástupce, a budou tak vyhodnoceny jako potenciální podvod. Typické chování každého zákazníka či zástupce je uloženo v takzvaných profilech. Kombinací obecné míry rizikovosti se specifickou mírou standardnosti chování pro daného zákazníka a zástupce pojišťovny lze dosáhnout nejlepších výsledků při detekci podvodu a vyhnout se falešným poplachům.
Vlastní nasazení fraud management systému je velmi jednoduché. Aktuální data o projednávané pojistné události se aplikují na vytvořený model rizikového chování. Ten určí rizikové skóre daného případu. Skóre případu pak indikuje váhu, s jakou je daný případ rizikový, a podle nastavených kritérií je podrobněji zkoumán, zda se nejedná o podvod.
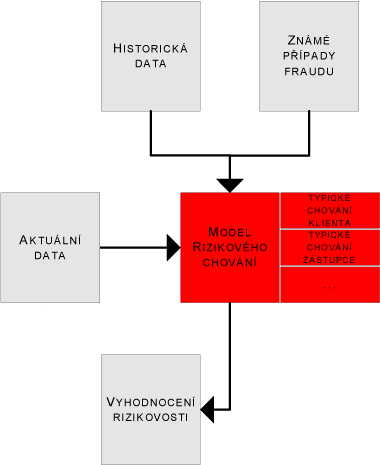
Obr. 1: Zjednodušené schéma fungování fraud management systému
Více dat více ví
Klíčovým měřítkem kvality systému pro detekci podvodů je úplnost a přesnost prediktorů (vstupů), které systém používá. Opomenutí podstatného prediktoru velmi zásadně snižuje úspěšnost detekce podvodu. Prediktory jsou vždy specifické pro danou problémovou oblast. Identifikace optimální množiny prediktorů je iterativní proces, kterého se nutně účastní odborník na obchodní problematiku a specialista na data mining. Předchozí zkušenost těchto expertů s podobnou aplikací je velmi prospěšná, protože zpravidla významně urychlí dosažení optimálního řešení.Popsané metody vyhodnocování podezřelých pojistných událostí jsou aplikovatelné na různé typy podvodů. Například při identifikaci podvodů se sledují následující ukazatele.
Pojišťovny sledují typ škody, její okolnosti ve vztahu k lokálním podmínkám, jako třeba počasí v dané době a místě, likvidátora, pojištěnce, další účastníky škodní události a jejich vztah k pojištěnci, dobu vyřízení, kvalitu dokumentace škody, frekvenci škodních událostí a výši dané škody. Dále se sleduje, zda škodní událost nenásleduje těsně po uzavření smlouvy, případně před zaplacením pojistného, po dodatečném připojištění, zda se neobjevuje opakovaná výplata na jeden účet a další.
Banka při odhalování podezřelých transakcí sleduje, zda se jedná o první nákup, kolik transakcí udělal zákazník v posledních 30 dnech, zda se shoduje adresa, na kterou se doručuje zboží a na kterou se zasílá účet, existence IP adresy, ze které je objednávka provedena, typ nakoupeného zboží a jeho množství, žádost o expresní doručení zboží. Podobně banka sleduje u kreditních karet typická místa použití, typické pořizované zboží, frekvenci použití, výši částky transakce, čas transakce, nezdařené autorizace transakcí a další ukazatele.
Konkurence se už bojí
Všechny aplikace fraud management systému mohou pojišťovnám, bankám a dalším společnostem přinést výrazné úspory. Obvyklým výsledkem nasazení typizovaného fraud management systému je snížení objemu podvodů o 60 až 90 %. Následně lze optimalizací a doladěním použitých prediktorů dosáhnout dalšího snížení podvodů o dalších 60 až 90 % z již snížené výše. Mnohé české finanční instituce si tuto příležitost uvědomují a systémy detekce podvodů postupně budují. Tyto systémy však neznamenají „jen“ omezení ztrát. Pokud bude na trhu několik pojišťoven nabízejících srovnatelné produkty, dlouhodobě nejlepší podmínky mohou nabídnout ty pojišťovny, které mají možnost výrazně omezit zneužití pojištění. A právě to znamená výraznou konkurenční výhodu.Autor působí jako data mining manager ve společnosti Adastra.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | 1 | 2 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce