

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce

| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEM 7-8/2003

Business Intelligence IV. díl
- Customer Churn/Attrition Management
Markéta Kaiserová
Data->Information->Knowledge->Decision


V minulém článku naší série o Business Intelligence byla vysvětlena problematika cíleného marketingu. Dotkli jsme se zejména aplikace datamingových metod v této oblasti. Dalším příkladem využití dataminingu je Customer Churn. V tomto díle podrobněji popíšeme na příkladu banky, jakým způsobem využít dataminigové postupy pro včasné odhalení odchodu zákazníků ke konkurenční bance. Vzhledem k tomu, že se jedná o poslední díl naší série, v závěru jsme připravili shrnutí toho nejpodstatnějšího z pohledu BI.
Customer Churn, Churn/Attrition management
Ve světě rostoucí konkurence a zvyšujícího se důrazu na profitabilitu se stává odchod zákazníků (Customer Churn) významným ukazatelem zdraví společnosti. Odchod zákazníků může pro společnost znamenat citelné snížení zisků a nárůst nákladů při hledání nových klientů.
Jak ovšem identifikovat profitabilní nebo potencionálně profitabilní klienty? Kdy k odchodu klientů dochází? Jaké jsou signály jejich možného odchodu? Znát odpovědi na tyto a další otázky je zpravidla výrazným, ne-li vítězným náskokem před konkurencí.
Cílem Churn/Attrition Managementu je rozpoznání takových stávajících zákazníků, kteří by mohli v blízké budoucnosti odejít ke konkurenční společnosti. Nalezení modelu odhadujícího pravděpodobnost odchodu zákazníka je úlohou, kde je možné použít BI (konkrétně datamining).
Cílem Churn/Attrition Managementu je rozpoznání takových stávajících zákazníků, kteří by mohli v blízké budoucnosti odejít ke konkurenční společnosti. Nalezení modelu odhadujícího pravděpodobnost odchodu zákazníka je úlohou, kde je možné použít BI (konkrétně datamining).
V minulém článku naší série o Business Intelligence byla vysvětlena problematika cíleného marketingu. Dotkli jsme se zejména aplikace datamingových metod v této oblasti. Dalším příkladem využití dataminingu je Customer Churn. V tomto díle podrobněji popíšeme na příkladu banky, jakým způsobem využít dataminigové postupy pro včasné odhalení odchodu zákazníků ke konkurenční bance. Vzhledem k tomu, že se jedná o poslední díl naší série, v závěru jsme připravili shrnutí toho nejpodstatnějšího z pohledu BI.
Customer Churn, Churn/Attrition management
Ve světě rostoucí konkurence a zvyšujícího se důrazu na profitabilitu se stává odchod zákazníků (Customer Churn) významným ukazatelem zdraví společnosti. Odchod zákazníků může pro společnost znamenat citelné snížení zisků a nárůst nákladů při hledání nových klientů.
Jak ovšem identifikovat profitabilní nebo potencionálně profitabilní klienty? Kdy k odchodu klientů dochází? Jaké jsou signály jejich možného odchodu? Znát odpovědi na tyto a další otázky je zpravidla výrazným, ne-li vítězným náskokem před konkurencí.
Cílem Churn/Attrition Managementu je rozpoznání takových stávajících zákazníků, kteří by mohli v blízké budoucnosti odejít ke konkurenční společnosti. Nalezení modelu odhadujícího pravděpodobnost odchodu zákazníka je úlohou, kde je možné použít BI (konkrétně datamining).
Cílem Churn/Attrition Managementu je rozpoznání takových stávajících zákazníků, kteří by mohli v blízké budoucnosti odejít ke konkurenční společnosti. Nalezení modelu odhadujícího pravděpodobnost odchodu zákazníka je úlohou, kde je možné použít BI (konkrétně datamining).
| |
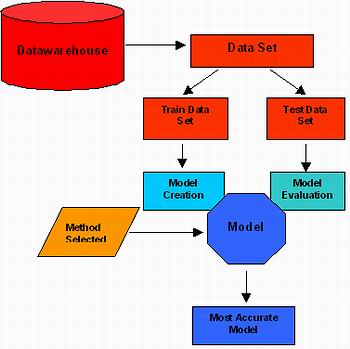
Řešení pro Customer Churn v bance
Pojďme se nyní podrobněji podívat na problém rozpoznání zákazníků, kteří by mohli v budoucnosti odejít ke konkurenční bance. Úvodem je potřeba říci, že řešení tohoto typu jsou v praxi vytvářena na míru konkrétního finančního ústavu a jsou vedena jako projekt, který můžeme rozdělit do následujících dílčích kroků:
. stanovení obchodního cíle řešení Customer Churn, definice výchozích podmínek,
. vytvoření klientsky orientované báze zkoumaných dat,
. tvorba modelu odchozího zákazníka a jeho implementace,
. využití/nasazení modelu.
Stanovení obchodního cíle řešení Customer Churn
Tato fáze řešení obsahuje zpracování studie, která se snaží popsat pravděpodobné chování zákazníků se sklonem k odchodu.
Cílem typického příkladu může být zjištění počtu klientů, kteří každý měsíc odchází z naší banky a kolika procenty se podílejí na zisku banky, a zároveň určení časového období, kdy klient vykazuje modelové chování směřující k odchodu z banky, tj. vytipování vhodného období a klientů pro oslovení.
Klíčovou úlohou v rámci této faze je vydefinování atributů, které budeme v rámci stanoveného cíle sledovat. V případě banky jsou vhodnými atributy například pokles zůstatků, transakcí, rušení trvalých příkazů na účtech atd. Za odchozího klienta můžeme považovat toho, který uzavřel všechny své účty. Vzorec chování, který vede k tomuto stavu, se budeme se snažit nalézt na datech s 12 měsíční historií. Nyní jsme zhruba popsali obsah iniciální studie, která je zpravidla v průběhu projektu dále doplňována o nové kvalifikační skutečnosti.
Vytvoření klientsky orientované báze zkoumaných dat
Stručně řečeno, by se dala tato fáze také popsat tak, že jejím cílem je získat tabulku s mnoha sloupci, přičemž jeden řádek v tabulce bude reprezentovat popis jednoho klienta a ve sloupcích budou uvedeny atributy, které jsme definovali v úvodní studii, tj.demografická data klienta a atributy popisující jeho chování prostřednictvím využívaných produktů a služeb (behaviorální data).
Pro vytvoření celkové báze zkoumaných dat je nutným předpokladem dostupnost historie veškerých dat, která v našem příkladě obnáší celý jeden rok. Cíl se zdá v tuto chvíli poměrně jednoduchý a zřejmý, ale v praxi se ukazuje, že tato část je časově značně náročná. Integrace zákaznických dat je klíčovým aspektem celého procesu a ovlivňuje kvalitu výsledné analýzy. Z tohoto důvodu je potřeba získat přesný a unifikovaný pohled na zákazníky celé banky.
Pro jednoduchost předpokládejme, že data budeme vybírat z již vytvořeného datového skladu, který obsahuje agregovaná data za několik let.
Nyní máme kompletní datovou množinu pro vytvoření modelu. V dalším kroku je potřeba provést kontrolu dat, zda v nich nejsou chyby, ošetřit hodnoty mimo přijatelný rozsah a chybějící hodnoty. V tomto kroku již můžeme použít dataminingové metody pro čištění a opravu spojitých nebo diskrétních hodnot.
Tvorba modelu odchozího zákazníka
Hlavním cílem v tomto kroku je získat hlavní atributy, které nejvíce ovlivňují zkoumanou proměnnou. Takto získaná množina atributů bude sloužit k nalezení modelu pro predikci Customer Churn.
Nejdříve provedeme výběr vzorku testovacích dat. Pro vývoj modelu náhodně vybereme data z té části klientů, která obsahuje vysoce rizikové zákazníky. Jinými slovy, vybereme zákazníky, jejichž pravděpodobnost odchodu z banky je co největší. Tzn., že zkoumaná proměnná pro náš model bude množinou několika podmínek. Definice tedy může znít: "hledáme proměnné, jejichž důsledkem je stav, kdy klient vykazuje úbytek zůstatku na účtech vyšší než 60 % nebo stav, kdy klient uzavřel všechny své účty".
Na testovací vzorek dat aplikujeme některý z prediktivních modelů. Pro řešení úlohy predikce odchodu zákazníků zmiňme modely založené na logistické regresi, neuronovou síť, kalasifikační stromy apod. Na trhu v dnešní době existuje dostatečné množství dataminingových nástrojů, které poskytují širokou škálu modelů, které jsou jednoduše aplikovatelné bez nutnosti znalosti technických detailů.
Ve fázi vývoje modelu je vhodné použít několik modifikací modelů a ověřit vzájemně jejich výsledky. Můžeme například změnit počet proměnných, které budeme jednotlivými modely zkoumat. Smyslem variací modelů je zajistit jejich robustnost a vyloučit závislost na vzorku zkoumaných dat (overfitting).
Pro ověřování modelů můžeme použít celou řadu metod založených na převzorkování, použití alternativních setů dat atd.
Pokud jsme vytvořili model a otestovali jeho platnost na testovacím vzorku dat, je nyní nutné provést jeho otestování na ostatních datech, a ověřit tak jeho obecnou platnost.
Pokud prokážeme robustnost a nezávislost na validačním vzorku dat, můžeme přistoupit k nasazení modelu do provozu.
Využití modelu
Tato fáze je rovněž důležitou součástí celého procesu sledování odlivu klientů. Výsledky, které nám model poskytuje, můžeme použít při realizaci cílených marketingových kampaní (viz. předchozí díl našeho seriálu) majících za cíl zvýšit věrnost zákazníků. Optimálně se modely pro Customer Churn stávají součástí automatizovaného nástroje pro vedení kampaní, který na základě generování událostí řídí aktivity, které se mají v tom kterém případě podniknout.
Znalost modelování odchodu zákazníků umožňuje také bance ověřovat cenovou politiku svých produktů a služeb. Například může banka zkoumat reakci klientů při zvýšení debetní úrokové sazby u vybraných produktů banky.
Výsledky modelování nám rovněž umožňují lépe porozumět klientům banky. Na výsledcích modelu můžeme provést segmentaci zákazníků, a získat tak charakteristiky loajálního zákazníka nebo naopak identifikovat vlastnosti zákazníka, který pravděpodobně zamýšlí odejít ke konkurenci.
Shrnutí
Toto byl poslední díl miniseriálu o Business Inteligence, jehož cílem bylo představit celkovou problematiku Business Intelligence (BI) z pohledu IT. Vedle problematiky terminologie se celý seriál věnoval spíše základním principům a postupům. Využijme tohoto závěru ke shrnutí toho nejdůležitějšího.
Business Intelligence je proces přeměny firemních dat na informace využitelné v rámci obchodní strategie společnosti. Jako takový nemůže tento proces fungovat bez znalosti obchodních cílů a směrování společnosti. Jedná se o proces značně komplexní, který vyžaduje spolupráci jak technických, tak obchodních složek firmy a rovněž se neobejde bez metodické a poměrně robustní technologické podpory. Náročnost tohoto procesu může být na straně druhé vyvážena přínosy, které lze ze získaných informací vytěžit. Ať už se jedná o hmotné přínosy v podobě vyšších tržeb z křížového či následného prodeje, nižších nákladů spojených se získáváním nových nebo udržením stávajích klientů, nižší ztráty plynoucí ze sníženého odlivu profitabilních klientů nebo o přínosy nehmotné plynoucí z lepší znalosti klientů, z úzké spolupráce mezi klíčovými útvary společnosti, vzájemného sdílení know-how či zlepšeného vnímání společnosti jejími klienty.
Pokud vás termíny jako data mining, prektivní model či událostmi řízený marketing už nepřivádí do rozpaků, pak naše snaha přiblížit tuto problematiku splnila svůj cíl. A pokud vás naše série zaujala natolik, že jste se rozhodli dozvědět více a pro svou společnost v tomto směru "něco udělat", pak přejeme vašim záměrům i úsilí hodně úspěchů.
Základní pojmy
Churn/Attrition management - systém řízení odlivu/udržení zákazníků.
Logistická regrese - statistická metoda, kdy hledáme funkci vyjadřující vztah mezi nezávislými proměnnými a výslednou závislou predikovanou proměnnou.
Neuronová síť - metoda, která minimalizuje chyby mezi vstupními a vzorovými hodnotami. Jedná se o iterační metodu, kdy po každé iteraci dochází k úpravám původních vah podle změřené chyby (učící se síť). Proces končí v okamžiku, kdy se dosáhne předem určené minimální chyby.
Klasifikační strom - metoda, která třídí data do skupin či větví tak, aby došlo k nejsilnější separaci hodnot závislé proměnné.
Autorka článku, Markéta Kaiserová, působí jako Business Consultant ve společnosti Ness Czech.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy




 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 1 | 2 | 3 | 4 | 5 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
IT Systems podporuje
| 11.6. | ManageEngine User Conf 2026 Praha |
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce
| 10.6. | Novicom cyber security workshop: Síť pod kontrolou... |
| 10.6. | Webinář - Creo 13 - Představení novinek |
| 26.6. | https://kybeon.moyazone.cz/konzultacni-hodiny/iso-certifikace-prakticky/... |
