

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce

| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

IT SYSTEMS 3/2013 , AI a Business Intelligence , Banky a finanční organizace


Odhalte podvody v pojišťovně
 Hodně slýcháme o detekci podvodů ve všech oblastech finančních služeb. Výrazy jako prediktivní modely, pokročilé statistické analýzy, sofistikované dataminingové algoritmy nalezneme v každé hodnotné marketingové prezentaci fraud detection systému. Jde o zázračné black boxy, které se samy naučí, jak takový podvod vypadá, a pak s elegancí Sherlocka Holmese vypátrají a označí hříšníky v téměř reálném čase.
Hodně slýcháme o detekci podvodů ve všech oblastech finančních služeb. Výrazy jako prediktivní modely, pokročilé statistické analýzy, sofistikované dataminingové algoritmy nalezneme v každé hodnotné marketingové prezentaci fraud detection systému. Jde o zázračné black boxy, které se samy naučí, jak takový podvod vypadá, a pak s elegancí Sherlocka Holmese vypátrají a označí hříšníky v téměř reálném čase.
Pravděpodobně se mnohým z vás stalo, že jste se pokoušeli koupit zájezd pro celou rodinu a zaplatit ho platební kartou on-line. Za pár minut volá vyděšený pracovník call centra vaší banky a zeptá se, zda jste to skutečně vy, kdo se pokouší zaplatit tuto horentní částku. Vy ho ujistíte, že ano, a pak spokojeně usínáte s dobrým pocitem, že vaše peníze jsou v bezpečí a někdo tam daleko na ně dohlíží. Jde o zázrak, nebo je to skutečné tak snadné?
Z pohledu banky nebo pojišťovny si musíme uvědomit, že fraud detection systém není nic jiného než chytrý vyhledávač anomálií nebo shod se známými vzory, který by měl k této činnosti využít všechny dostupné informace. V praxi neexistují řešení, která jakmile vybalíme z krabice, začnou sama pracovat. V ideálním případě je nutné využít všech stávajících vědomostí o vašem byznysu a zkombinovat je s efektivním IT produktem pro vytvoření komplexního, a hlavně užitečného fraud detection systému.
Pojišťovny sdružené v České asociaci pojišťoven prověřovaly v roce 2012 přes šest tisíc podezřelých pojistných událostí a prokázaly pojistné podvody za více než jednu miliardu korun. Celková prokázaná hodnota pojistných podvodů odhalená pojišťovnami v loňském roce narostla meziročně o 27 procent. Největší nárůst ve výši prokázaných hodnot zaznamenaly pojišťovny v oblasti pojištění majetku a odpovědnosti (30 %). Specialisté pojišťoven odhalili v této oblasti podvody za více než 560 milionů korun.
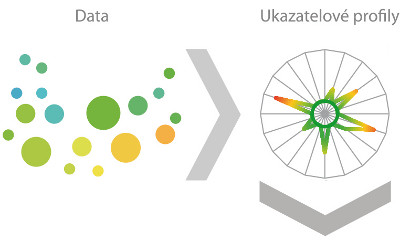
Vyhledávání známých vzorů podvodů je možné nad daty, u kterých jsme na dostatečně velkém vzorku schopni jasně odlišit podvody od korektních případů. Potom je už musíme „jen“ prohnat chytrými algoritmy strojového učení a po nezbytném čase ladění získáme klasifikátor (systém, který s určitou pravděpodobností rozeznává podvody, tj. identifikuje hledané entity). Problém je, že tento přístup není možné použít pro všechny typy dat. V mnoha oblastech nemáme k dispozici předem jasně rozlišená korektní a podvodná data, na kterých by se systém mohl učit, a proto se musíme více spoléhat na starou dobrou statistiku. Když se člověk pokouší identifikovat podvod, nebo podezřelé entity mezi několika příklady, intuitivně se soustřeďuje na ty vybočující od průměru. Situaci komplikuje jen fakt, že informací o entitě je obvykle velké množství a lidská mysl není schopná tyto informace pojmout a komplexně zhodnotit. Tento přirozený způsob je možné pojmout algoritmicky a při chytře nadefinovaném datovém modelu získáme ohromné možnosti, jak naše data využít a sofistikovaně vyhledávat ty anomálie, které jsou objektem našeho zájmu.
Příklad místo řečí
Řekněme, že naším cílem je výběr pěti poboček ze sta, na které se má zaměřit kontrola. Logickým krokem je v tomto případě seřadit všechny pobočky dle stupně „podezřelosti“ a zaměřit naší pozornost na pět nejhorších. Zní to jednoduše, ale jak správně tyto pobočky ohodnotit a následně seřadit? Je horší, když má pobočka A o třicet procent více zrušených účtů než průměr, nebo že má pobočka B o třicet procent více nesplacených úvěrů než průměr, anebo že pobočka C má o patnáct procent vyšší oba ukazatele? Evidentně to závisí ještě na dalších aspektech.
Jak se vypořádat s realitou, když těchto ukazatelů je několik desítek až stovek, jsou navzájem propojené a k tomu v čase proměnné? Při hledání odpovědi na tuto otázku se můžeme inspirovat výzkumem provedeným na jihokorejských univerzitách a testovaném na datech jihokorejské Health Insurance Review Agency. Na základě této studie byl navržen a testován komplexní hodnotící systém, který je schopný dle definovaných ukazatelů (jednotkové náklady, počet zrušených účtů na zaměstnance atd.) ohodnotit jakékoliv entity (pobočky, klienty atd.) dle míry odlišnosti od ostatních a vysvětlit, které ukazatele primárně přispěly do vypočteného hodnocení. Samozřejmostí je porovnávání jednotlivých ukazatelů v čase, protože abnormální růst je často dobrým vodicím znakem pro nekorektní chování. Entity jsou pak seřazeny dle dosažených výsledků a rozděleny do skupin dle míry anomálie. Grafické zobrazení profilů entit napomáhá identifikovat příčiny vysokého skóre, takže kontrolní nebo revizní pracovník hned porozumí hodnocení dané entity.
Boris Grekov
Autor působí jako externí konzultant ve společnosti GEM System.


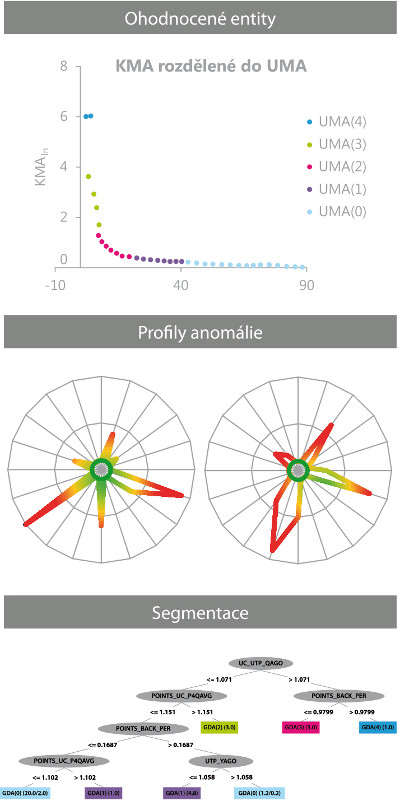
Popis hodnotící metody
Základem je definice ukazatelů, pro které platí následující pravidlo: čím je ukazatel vyšší, tím spíše se jedná o podezřelé chování. Pro jednotlivé ukazatele se pak v rámci relevantní skupiny spočítají průměry a nadprůměrné hodnoty se statisticky vyhodnotí vzhledem k variabilitě, přičemž hodnoty dále od průměru mají větší vliv, tudíž jejich míra anomálie je vyšší. Výsledným produktem je vážený součet individuálních měr anomálií, který vytváří výslednou kompozitní míru anomálie (KMA). Vzhledem k faktu, že ne všechny ukazatele mají stejný vliv na podezřelé chování, je dalším důležitým aspektem relativní váha ukazatelů. Ta se v první fázi stanovuje manuálně na základě expertních odhadů a postupem času je automaticky přizpůsobována dle zpětné vazby od uživatelů. Entity jsou dále pomocí clusteringu rozděleny do pěti skupin dle logaritmu úrovně míry anomálie (UMA). Skupina 4 pak obsahuje nejpodezřelejší entity, na které by se měla zaměřit kontrola. V mnoha případech nás taky zajímá jemnější segmentace v rámci skupin dle hodnot ukazatelů. Proto je v poslední fázi vytvořen rozhodovací strom, který entity zařadí do skupin, ovšem dle původních hodnot ukazatelů, nikoli mír anomálie. To vytvoří segmenty entit s podobným chováním, a kontrola pak může být lépe cílená.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.
Časopis IT Systems / Odborná příloha
Archiv časopisu IT Systems



 Oborové a tematické přílohy
Oborové a tematické přílohy



 Kalendář akcí
Kalendář akcí
Formulář pro přidání akce


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 1 | 2 | 3 | 4 | 5 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce
| 26.6. | Certifikace ISO prakticky |