

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce

| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

Jaké ponaučení si vzít z výpadků Cloudflare?
Multi-cloud může pomoci, ale není to všelék
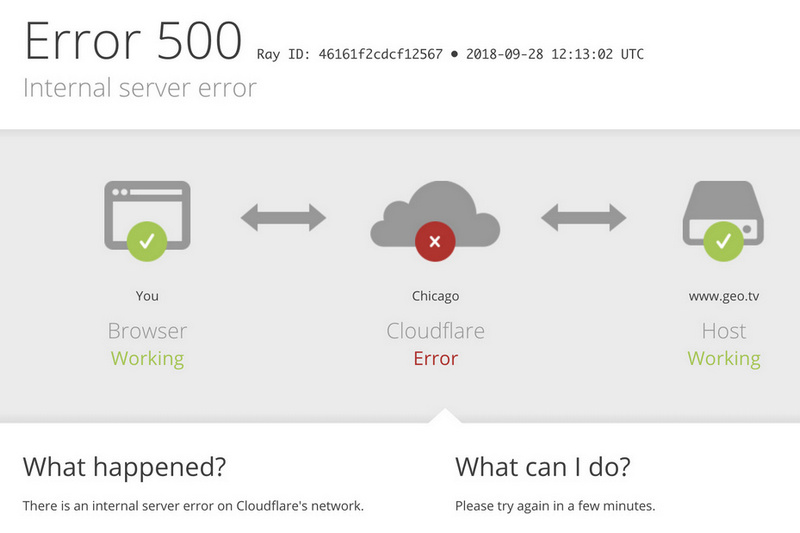 Hned dva globální výpadky služby Cloudflare v nedávné době opět ukázaly, že ani největší světoví hráči nejsou imunní vůči interním chybám. V obou případech šlo o konfigurační změny, které se rozšířily na celou síť dřív, než se projevil problém – klasický failure mode distribuovaných systémů.
Hned dva globální výpadky služby Cloudflare v nedávné době opět ukázaly, že ani největší světoví hráči nejsou imunní vůči interním chybám. V obou případech šlo o konfigurační změny, které se rozšířily na celou síť dřív, než se projevil problém – klasický failure mode distribuovaných systémů.


Kdo to pocítil nejvíc?
Výpadky služby Cloudflare, které nastaly 18. listopadu na cca 5,5 hodiny a 5. prosince na cca 25 minut nejvíce zasáhly e-shopy a SaaS služby s vysokou závislostí na real-time dostupnosti. Podle našich interních dat jsme u některých klientů zaznamenali 100% nedostupnost po dobu incidentu. U větších e-shopů to může znamenat ztráty v řádu desítek tisíc korun za minutu – konkrétní čísla se ale dramaticky liší podle segmentu, marže a denní doby. Finanční sektor a kritická infrastruktura byly zasaženy méně, většinou díky existujícím multi-vendor řešením a přísnějším regulatorním požadavkům.
Dopad každého výpadku se zvyšuje
Podle reportu Parametrix vzrostl počet kritických incidentů u top 3 cloud providerů (AWS, Azure, GCP) o 18 % v roce 2024 oproti 2023. Důležité ale je, že současně dramaticky roste objem služeb běžících v cloudu a závislost na něm – takže relativní spolehlivost se nemusí zhoršovat tak výrazně, jak absolutní čísla naznačují. Co se ale určitě zhoršuje, je dopad každého jednotlivého výpadku, protože více byznysu závisí na méně providerech.
Multi-cloud může pomoci, ale není to všelék
Klientům, pro které takový výpadek představuje citelné ztráty, doporučujeme zvážit aktivní multi-CDN/multi-cloud strategii. Je ale fér říct, co to obnáší:
- Vyšší provozní náklady – platíte za redundanci, kterou většinu času nevyužijete. U menších projektů může roční cena multi-CDN setupu převýšit očekávané ztráty z výpadků.
- Komplexita – debugování problémů napříč providery je výrazně těžší. Potřebujete lidi, kteří rozumí více platformám, a unified monitoring, který není triviální postavit.
- Nové failure modes – multi-cloud setup může selhat koordinovaně (společná závislost na DNS, certifikátech, nebo třeba na tom samém podmořském kabelu). Přidáváte resilience, ale také nové vektory selhání.
Co má smysl pro koho?
- Pro velké e-shopy a SaaS s vysokými náklady na výpadek (řádově statisíce Kč/hodinu a více) dává smysl investovat do aktivního multi-CDN s automatickým failoverem a hybridního modelu s lokálním DC jako fallbackem.
- Pro střední projekty může být rozumnější pasivní připravenost – mít otestovaný plán B, který aktivujete manuálně, místo plně automatizovaného (a drahého) řešení.
- Pro menší projekty je často nejefektivnější přijmout, že občasný výpadek je součást života, a investovat spíš do rychlé komunikace se zákazníky a kompenzačních mechanismů.
Vendor-neutrální nástroje pomáhají, ale nejsou magie
Kubernetes, HAProxy, Nginx nebo BGP routing skutečně usnadňují přenositelnost a snižují vendor lock-in. Zároveň ale přinášejí vlastní provozní komplexitu – Kubernetes cluster vyžaduje netriviální expertízu a sám o sobě může být zdrojem výpadků. Cílem by nemělo být „zbavit se závislostí" (to nejde), ale vědomě si vybrat, na čem závisíte, a mít plán pro případ selhání.
Závěr
Kdo dnes spoléhá pouze na jednoho globálního poskytovatele, přijímá riziko, že jeho další výpadek bude i vaším výpadkem. Jestli je to akceptovatelné riziko, záleží na konkrétním byznysu. Důležité je, aby to bylo vědomé rozhodnutí, ne jen důsledek setrvačnosti.
 |
Jan Skalla Autor článku působí na pozici Innovation Tech Lead ve společnosti MasterDC. |

Časopis IT Systems / Odborná příloha
Kalendář akcí
Formulář pro přidání akce
RSS kanál


| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 1 | 2 | 3 | 4 | 5 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce
| 26.6. | https://kybeon.moyazone.cz/konzultacni-hodiny/iso-certifikace-prakticky/... |
