


- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (36)
- WMS (29)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (26)
- Řešení pro veřejný a státní sektor (27)
Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |

Partneři webu

ERP systémy, Plánování a řízení výroby, Cloud a virtualizace IT, Aktuality -> Podnikové aplikace a služby - 9. 11. 2020
Klíčem k digitalizaci výroby je přístup ke všem typům dat z různých zdrojů
-PR-
 Výroba a digitální svět se pomalu, ale jistě prolínají. Klíčem k flexibilní výrobě je sjednocený přístup k distribuovaným a heterogenním zdrojům dat. Dosáhnout toho lze unifikovanou datovou vrstvou, která vytvoří transparentní datový prostor nad všemi typy a zdroji dat, tedy jak z on-premise řešení, tak i cloudu.
Výroba a digitální svět se pomalu, ale jistě prolínají. Klíčem k flexibilní výrobě je sjednocený přístup k distribuovaným a heterogenním zdrojům dat. Dosáhnout toho lze unifikovanou datovou vrstvou, která vytvoří transparentní datový prostor nad všemi typy a zdroji dat, tedy jak z on-premise řešení, tak i cloudu.
Shromažďování a analýza dat, vyvození závěrů a reakce na ně. To je základ samoučících se systémů. Jsou základem pro transformaci z automatizovaného řízení výroby na autonomní výrobu. Cílem je zlepšit efektivitu využívaných zařízení a zprostředkovat přechod na digitalizovaný podnik. Jedním z příkladů může být obrábění. Procesem strojového učení lze vyhodnocovat kvalitu povrchu obráběného výrobku, algoritmy a dynamická pravidla následně doporučí změnu nastavení obrábění, nebo přímo provedou konkrétní akci: roztřídí výrobky, upraví následující výrobní kroky nebo optimalizují obráběcí proces. Aby toto fungovalo, musí podnik vytvořit digitální model výrobní logiky a zdrojů, a zpřístupnit jim příslušné parametry kvality a samotného procesu výroby. Porovnáváním procesních a kvalitativních parametrů je generován datový model, který umožní nepřetržitou kontrolu a optimalizaci výroby.
Koloběh dat mezi produkcí a centrálním řízením
Kvalita datových modelů závisí na množství a kvalitě „učebního materiálu“. Technikovi údržby může trvat roky, než bude znát přesné chování jednoho konkrétního CNC stroje, a bude schopen identifikovat chybu v zárodku, nebo chybám předcházet. Pokud se však podaří shromáždit zkušenosti ze stovek nebo tisíců podobných obráběcích strojů, tak je možné proces učení snížit na týdny nebo dny. Přitom čím přesnější jsou data k dispozici, tím rychlejší a lepší bude efekt učení. Tak se firmy mohou postarat o svou udržitelnou konkurenční výhodu. Nejsou to přitom jen data z výrobního procesu, která jsou relevantní pro trénink datového modelu. Do procesu totiž vstupují i další údaje, jako například naměřené hodnoty z obráběcího stroje (např. vibrace), informace o prostředí (např. vlhkost) a také logistické a obchodní parametry, např. z ERP systémů.
Natrénované datové modely, algoritmy a pravidla provádí analýzu dat a změny během výrobního procesu. To v některých situacích vyžaduje velmi nízkou dobu odezvy datového modelu. Z tohoto důvodu se analýza dat provádí obvykle ve výrobě v blízkosti strojů s využitím průmyslových edge systémů, které fungují jako rozhraní mezi výrobními a IT systémy. Díky těmto systémům jsou analýza a následné kroky provedeny na místě bez nutnosti přenosu dat do vzdálených datových center nebo cloudů, a také je zaručena nejvyšší možná stabilita celého procesu.
Výsledkem je permanentní koloběh dat mezi distribuovanými výrobními lokacemi a centrálními systémy. Datové moduly jsou kontinuálně vylepšovány v centrálním systému s pomocí dat, která jsou generována ve výrobě. Výroba naopak využívá natrénované datové modely, algoritmy a pravidla pro kontrolu produkčního procesu.
Důležité je vyvarovat se datovým ostrovům a závislostem
K vytvoření takovéhoto koloběhu v celém řetězci musí být data integrována vertikálně i horizontálně. Díky vertikální integraci se data ze strojů nebo systémů přenášejí do centralizované IoT nebo cloudové platformy. Může to být například teplota a míra vibrací s příslušným časovým razítkem, které jsou pravidelně odečítány a vizualizovány nebo zpracovávány v centrálním systému.
Výrobní společnosti přitom čelí těžkému rozhodnutí. Pokud používají IoT platformy různých výrobců, pak vytvářejí datové ostrovy, které ztěžují celkovou analýzu a řízení. Již existující komplexnost výroby se ještě více upevňuje nebo zvyšuje – vzniká typická tzv. „špagetová architektura“, v níž je několik různých databází, analytických nástrojů a aplikací křížově propojeno prostřednictvím individuálních rozhraní. Na druhou stranu, pokud se firmy spoléhají kvůli snížení složitosti pouze na jednu nebo několik cloudových platforem, závislost na těchto platformách se zvýší. Horizontální integrace dat může tyto problémy řešit. V takovém případě se data nepřenášejí do centrálního úložiště, ale jsou navzájem propojena prostřednictvím samostatné datové vrstvy.
Řízení datových toků s pomocí datové struktury
Datová struktura slučuje distribuované a heterogenní souborové systémy s pomocí abstrakce do jednoho jmenného prostoru. Výrobní podniky získají jednotný přístup k datům a souborům, které jsou dostupné širokému okruhu aplikací. Navíc organizuje koloběh dat a je uzlem, jehož prostřednictvím jsou do tohoto cyklu integrována výrobní místa, cloudové služby a partnerské společnosti jako dodavatelé nebo příjemci dat a analytických modelů.
S tímto přístupem lze vyřešit otázku složitosti, protože existuje konsolidovaný přístup k datům a interakce mezi aplikacemi, zdroji dat a databáze jsou organizovány přes jednotnou datovou vrstvu. Také řeší problém se závislostí, protože výrobní podnik kontroluje cyklus dat – ne externí platformy, které integrují zákazníky jako pavouk do jejich vlastní sítě. I při použití více externích platforem je zachována jednotnost datové architektury. Produkční společnost tak může snížit svou závislost prostřednictvím využití více dodavatelů, aniž by se musela obávat nadměrné složitosti nebo datových ostrovů.
Stavební bloky datové struktury
Datová struktura je založena na otevřené a transparentní architektuře. Její nejdůležitější součásti v rámci procesního řetězce jsou čtyři „A“:
- Akvizice: sběr dat probíhá s pomocí softwarových modulů, které přistupují k datům prostřednictvím aplikačních programovacích rozhraní. Může to být SQL databáze systému ERP, data senzorů CNC obráběcího stroje nebo NoSQL databáze cloudové aplikace. Softwarové moduly převádějí příslušné průmyslové protokoly na IP pakety a zachycují tak různé zdroje dat.
- Agregace: ne všechna zdrojová data jsou obvykle relevantní pro další zpracování. Proto se ukládají do tzv. data lake (datového jezera), které agreguje velké množství heterogenních dat souvisejících s výrobou tak, aby vznikla co největší databáze dat pro strojové učení. Na rozdíl od tradičního datového skladu lze datové jezero distribuovat do různých míst a prostředí – například do výroby, datových center nebo již zmíněných cloudových prostředí. Multi-tenantní platforma umožňuje kontrolovat, kteří uživatelé mají přístup ke kterým datům a jakým způsobem. Výhodou je, že distribuované datové jezero lze používat několika společnostmi, aniž by to ovlivnilo suverenitu dat zúčastněných společností.
- Analýza: prostřednictvím tzv. data taps (datových kohoutků) mohou datoví analytici získat přístup jak k aktuálním provozním datům, tak k distribuovanému datovému jezeru, a experimentovat s datovými modely, trénovat je, vylepšovat a průběžně aktualizovat. Pomocí analýzy toků dat v reálném čase jsou natrénované modely použity k monitorování senzorů probíhající produkce. Taková analytika je základem pro autonomní akce v provozu i pro střednědobé zásahy, jako je například prediktivní údržba.
- Akce: spouštějí se na základě algoritmů nebo obchodní logiky, jako například otevření servisního případu, pokud stroj z důvodu svého opotřebení nedodává požadovanou kvalitu. Na základě těchto znalostí lze upravovat následné procesy, aby se kvalita vrátila zpět do požadované tolerance.
Kontejnery jako technologický základ
V dnešní době jsou systémy poskytující datové struktury dostupné v podobě kontejnerů. Díky tomu lze takové systémy distribuovat a provozovat napříč výrobními a logistickými místy, datovými centry a cloudy jednotným způsobem. Kontejnery a orchestrace kontejnerů s Kubernetes jsou aktuálně preferovanou volbou pro vytváření distribuovaných a platformě nezávislých aplikací. Nabízí i možnost řešit otázku persistence dat v kontejnerovém a Kubernetes prostředí, a tak umožňuje provozovat v kontejnerech i monolitické nástroje. Neocenitelnou výhodou je poté homogenní prostředí s efektivitou a transparentností provozu.
Pokud se firma rozhodne vybudovat a používat takovou datovou strukturu, pak si musí odpovědět na otázku, zda koupit hotové řešení, nebo si jej postavit vlastními silami. K dispozici je totiž velké množství technologií a open source nástrojů, které mohou firmy použít k vybudování vlastní datové struktury. Alternativou jsou připravené komerční produkty, jako je například HPE Ezmeral Data Fabric. Jde o masivně škálovatelný, distribuovaný souborový systém, který poskytuje vysoký výkon pro správu datových objemů v řádu petabajtů. Je také základním kamenem systému HPE Ezmeral Container Platform, který je používán pro vybudování datových struktur s využitím kontejnerové technologie a ke správě kontejnerových Kubernetes prostředí. Tato platforma nabízí řešení pro analýzu distribuovaných zdrojů dat a také řešení pro persistentní ukládání dat v prostředí kontejnerů.
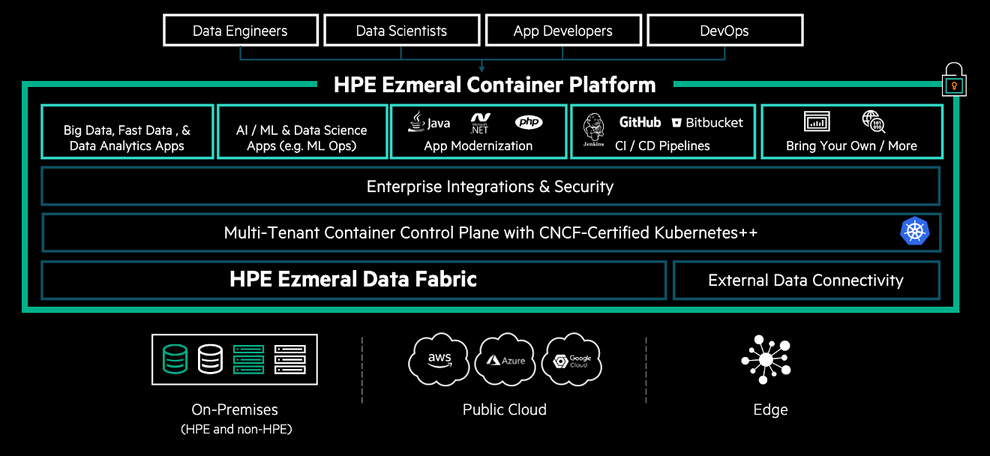
Závěrem
Správně nasazená datová struktura představuje datové centrum, které firmě umožňuje výměnu dat a řídí datové toky a datovou procesní logiku. Díky datovým strukturám mohou výrobní společnosti využít potenciál svých dat a využít jej pro zlepšení efektivity nebo vytvoření nové digitální platformy, která může poskytovat digitální služby svým zákazníkům. Kromě využití vlastních dat lze používat také jejich externí zdroje. Zapojeným stranám může naopak poskytnut řízený přístup k datům, což poskytne síťové efekty napříč společnostmi.
S tímto přístupem zůstávají společnosti nezávislé na centrálních IoT nebo cloudových platformách prostřednictvím decentralizované architektury, která je pod jejich vlastní kontrolou. Uplatnění lze pak nalézt nejen ve výrobních společnostech, ale také ve finančních oborech, pojišťovnách, vědeckých odděleních, farmacii, marketingových analýzách a mnoha dalších odvětvích moderního průmyslu a služeb.
 |
Vlastimil Čudek Autor článku je konzultantem ve společnosti HPE pro oblast New IT a jeho nasazení v praxi. Má dlouholeté zkušenosti s nasazováním nových IT trendů a technologií ve vývoji a výrobě high-tech produktů. |
Časopis IT Systems / Odborná příloha
Kalendář akcí
Formulář pro přidání akce
 RSS kanál
RSS kanál


IT Systems podporuje
Formulář pro přidání akce
Tvorba webových stránek Brno
RSS kanál
SystemNEWS (newsletter): Archiv | Inzerce | Přihlášení || SystemOnLine.cz: Kontakty | Inzerce