




- Přehledy IS
- APS (22)
- BPM - procesní řízení (23)
- Cloud computing (IaaS) (9)
- Cloud computing (SaaS) (29)
- CRM (49)
- DMS/ECM - správa dokumentů (19)
- EAM (16)
- Ekonomické systémy (68)
- ERP (87)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (52)
- WMS (28)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (40)
- Dodavatelé CRM (36)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (80)
- Informační bezpečnost (42)
- IT řešení pro logistiku (46)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (26)
Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
Přihlaste se k odběru zpravodaje SystemNEWS na LinkedIn, který každý týden přináší výběr článků z oblasti podnikové informatiky | ||

| ||

Partneři webu

IT SYSTEMS 4/2023 , Plánování a řízení výroby , AI a Business Intelligence , CAD/CAM/CAE/PLM/3D tisk


Datová analytika a strojové učení v praxi
I. díl: Jak překonat úskalí nasazení datové analytiky s technologií strojového učení
Tomáš Čurda
 Dnes se firmy doslova topí v datech. Ta se sbírají rychleji, ve větším množství a ve více formátech než kdykoli předtím. Teoreticky by více dostupných informací mělo znamenat kvalifikovanější rozhodování. Skutečnost je však poněkud odlišná. Objem shromažďovaných dat a rychlost jejich sběru začíná lidem přerůstat přes hlavu a tradiční analytické techniky den ode dne pozbývají na užitečnosti. Otevírá se tedy spousta prostoru pro využití analytických modelů se strojovým učením (ML). Na druhou stranu ani jejich implementace není bez problémů. Výzkumy například zjistily, že jen asi 10 % vyvinutých funkčních modelů je skutečně nasazeno do praxe, a to zejména z důvodů nedostatečné komunikace a sdílení znalostí v projektových týmech.
Dnes se firmy doslova topí v datech. Ta se sbírají rychleji, ve větším množství a ve více formátech než kdykoli předtím. Teoreticky by více dostupných informací mělo znamenat kvalifikovanější rozhodování. Skutečnost je však poněkud odlišná. Objem shromažďovaných dat a rychlost jejich sběru začíná lidem přerůstat přes hlavu a tradiční analytické techniky den ode dne pozbývají na užitečnosti. Otevírá se tedy spousta prostoru pro využití analytických modelů se strojovým učením (ML). Na druhou stranu ani jejich implementace není bez problémů. Výzkumy například zjistily, že jen asi 10 % vyvinutých funkčních modelů je skutečně nasazeno do praxe, a to zejména z důvodů nedostatečné komunikace a sdílení znalostí v projektových týmech.
Tento článek si bere za cíl pomoci zejména novicům v oblasti Data Science a Machine Learning (DSML) porozumět většině úskalí, se kterými se typicky setkáváme při implementacích těchto technologií. Budeme se na problémy a možná řešení dívat jak optikou implementačních zkušeností a metodik, tak z pohledu softwarových platforem. Bavíme se o oboru, kterému se v angličtině říká Data Science, ale pro potřeby tohoto článku si dovolím častěji užívat jen „obyčejnější“ datová analytika. Taktéž zjednoduším označení rolí datových specialistů souhrnně na datový analytik či expert namísto původního jemnějšího dělení na Data Scientist, Data Engineer a Data Analyst. Dovolím si tímto článkem předat zkušenosti implementačních týmů společností RapidMiner a Altair, se kterými v Advanced Engineering spolupracujeme, a dále se odvolávat na průzkumy např. Forrester Consulting.
Proč byste se měli zabývat datovou analytikou
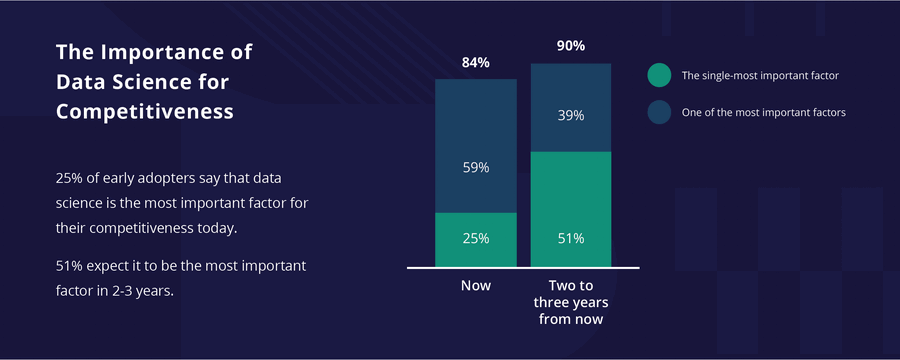
Připomeňme si na úvod poněkud zprofanovaný termín digitální transformace. Je to proces zavádění informačních technologií do celého podniku způsobem, který vám pomůže změnit způsob fungování firmy a vytvořit větší hodnotu pro vaše zákazníky. Tedy vše se točí kolem přínosů a kolem toho, že se firma chce strategicky zlepšovat, upevňovat své postavení na trhu nebo se stát leaderem svého oboru. A jak může v rámci firemní strategie pomoci právě Data Science? Datová věda je multidisciplinární přístup, který pomáhá společnostem využívat jejich stávající data k předpovědím toho, co se pravděpodobně stane v budoucnosti. Tedy firmy mají možnost například včas měnit objem výroby, měnit procesy, lépe vyhodnocovat rizika a chápat chování svých zákazníků. Potenciál je tedy zřejmý. Dokladem budiž zpětná vazba respondentů zahraničního průzkumu, kde asi 25 % firem, které datovou analytiku se strojovým učením již začaly využívat, ji berou za nejdůležitější faktor své konkurenceschopnosti. A dalších 50 % respondentů tohoto průzkumu si myslí, že tomu tak bude během už dvou tří let. Bez zajímavosti není, že pionýři využití strojového učení neboli early adopters mívají navíc téměř dvojnásobnou návratnost investic do datové analytiky ve srovnání s těmi, co začnou později.

Různé přístupy k nasazení
Pokud se rozhodnete, že chcete začít s pokročilými datovými analýzami, nabízejí se tři běžně využívané přístupy – outsourcing celé úlohy konzultační firmě, nábor datových specialistů do firmy a třetí cestou je vybudování know-how zejména u stávajících pracovníků.
Outsourcing zadání směrem ke konzultační firmě na první pohled dává smysl – konzultanti existují proto, aby pomohli zaplnit mezery v kompetencích a kapacitách svých klientů. Navíc mají ve své specializaci špičkové know-how. Pokud je však vaším strategickým cílem zlepšit datovou gramotnost v celém podniku a řešit postupně celou řadu případů použití, přinese spoléhání se výhradně na externí konzultanty řadu omezení. Specificky pro oblast strojového učení je zde problém údržby modelů. I ty nejrobustnější se stávají postupně nepřesnými a začínají dávat chybné předpovědi. Musí se o ně někdo nadále starat.
Druhým přístupem je nábor zkušených datových analytiků do vaší společnosti. Tato cesta může být dobrá, zejména pokud budete do týmu potřebovat lidi s hlubokou specializací v Data Science a se schopnostmi programování. Chybou ale často bývá, že firmy tyto specialisty nechají pracovat izolovaně od okolí, a tak neumožní, aby se datová analytika stala klíčovou kompetencí celé organizace. Problémem je bohužel i velký nedostatek takových lidí na trhu práce a jejich fluktuace. A podobně jako u prvního přístupu jejich obrovská neznalost řešené oblasti. Nelze například očekávat, že pro tyto datové experty bude snadné optimalizovat efektivitu nějakého výrobního procesu, pokud jej dostatečně nepochopí.
Třetí cestou je rozšiřování kompetencí stávajícího týmu o schopnost pracovat s daty. Mluvíme o interních odbornících na jednotlivé činnosti firmy, například o středním managementu či zkušených interních analyticích. Tito lidé se musí umět z povahy své práce rozhodovat, respektive činit vrcholovému vedení kvalifikovaná doporučení. Při využití DSML musí navíc ke své dosavadní práci přidat dílčí kompetenci datového analytika. Pokud chtějí potenciál těchto technologií využít, třeba i ve spolupráci s externími konzultanty, potřebují datovým modelům a procesu jejich tvorby dobře rozumět, být schopni na vývoji participovat a výsledky umět dále srozumitelně interpretovat. Současné technologie se snazším osvojením a intuitivnější prací již umí pomoci.
Cest je tedy více a možné jsou i kombinace, ale klíčem bude „nedrhnoucí“ komunikace v týmu a schopnost porozumět modelům a dosaženým výsledkům. Představte si následující situaci. V podstatě izolovaný tým specialistů-analytiků připraví model, třeba pomocí kódování v Pythonu nebo R, který bude správně navádět management společnosti ke strategické změně s dopadem mnoha milionů korun. Těžko si dovedete představit, že model bude nasazen, pokud analytický tým nebude umět tento model vysvětlit – jak vznikl, na základě jakých předpokladů a dat, jak funguje jeho algoritmus a s jakou pravděpodobností dosahuje prezentované přesnosti. Pokud všechny zainteresované strany, včetně managementu a vlastníků business procesů, nebudou od začátku vtaženi do projektu a dále nebudou mít k dispozici nástroje usnadňující vhled do modelů, je pravděpodobné, že se vyvinutý model octne na hromadě oněch 90 % nikdy nenasazených.
Porozumění v projektu, metodiky a zkušenosti
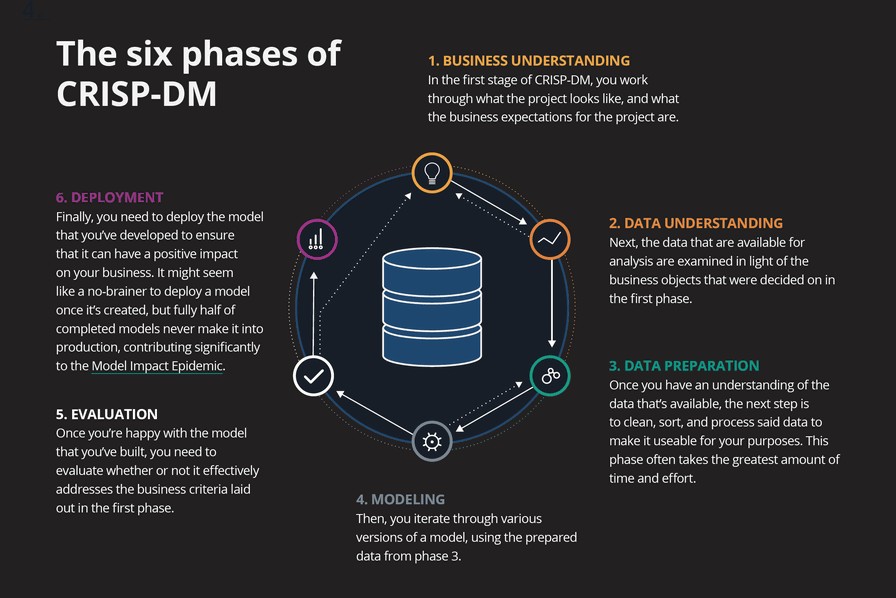
Projektový tým pro datovou analytiku sestává z odborníků na data, na IT infrastrukturu, na vlastní business i dalších. Tedy lidí s různým pohledem na věc. A pro porozumění mezi nimi je třeba nalézt správný „jazyk“, typicky vhodnou projektovou metodiku. Asi nejrozšířenější je CRISP-DM (cross-industry standard process for data mining). Pomůže porozumět fázím vývoje, společným cílům i vyhodnocení. V tomto článku nemáme prostor se jí zabývat detailněji, ale připomeňme si alespoň, jak definuje jednotlivé fáze projektu:
1. Business Understanding
Nejprve se zabývejte tím, jaká jsou obchodní očekávání projektu. Datoví analytici často považují za hlavní problém projektu strojové učení – ale pravda je, že vše musí být zaměřeno na businessové problémy. Dejte prostor business analýze a nespěchejte. Pokud v této fázi příliš rychle přejdete k návrhu řešení, hrozí, že problémy vyřešíte nevhodně třeba tím, že budete vynucovat řešení pomocí strojového učení tam, kde se vůbec nehodí. Mohli byste také zcela minout zacílení na obchodní problém a vytvořit něco naprosto neužitečného.
2. Data Understanding
Prozkoumejte data, která máte k dispozici, jejich dostupnost v agregované či zdrojové podobě, dále přístupová práva, frekvenci jejich aktualizace a podobně.
3. Data Preparation
Vyčištění, třídění a zpracování dat je nejpracnější fáze projektu. Datoví analytici by měli úzce spolupracovat s business specialisty, aby datový profil byl úplný, hutný a data pro model řádně vyčištěná. Tak bude model plně reprezentativní, ale nebude obsahovat zbytečný šum.
4. Modeling
Připravte a zvažte různé verze modelů na základě dat připravených z předchozí fáze. Následně validujte a porovnávejte jejich kvalitativní parametry.
5. Evaluation
Jakmile jste spokojeni s vytvořeným modelem, který jste vytvořili, musíte vyhodnotit, zda účinně splňuje obchodní kritéria stanovená ve fázi Business Understanding.
6. Deployment
Nakonec je třeba vyvinutý model nasadit do produkce, aby měl reálně pozitivní dopad na vaše podnikání. Mohlo by se zdát, že nasazení modelu po jeho vytvoření je samozřejmostí, ale jak už bylo zmíněno výše, opak je pravdou.
Pojďme se, v rámci rozsahu tohoto článku, dále podívat na několik typických problémů, úskalí a potažmo nejlepších zkušeností, které vedou k jejich řešení – alespoň podle výše zmíněných implementačních týmů.

Schopnost „prodat“ výsledky své práce
Datoví experti si musí být vědomi, že zásadní je prodat své metody všem zainteresovaným stranám. Pokud je nepřesvědčíte, nikdy se modely nedostanou do produkce. Zůstaňte u jednoduchosti. Všechny koncepty strojového učení můžete vysvětlit jednoduše pomocí algoritmu rozhodovacího stromu. Rozhodně se nesnažte, minimálně na začátku, vykládat například teorie neuronových sítí. Velmi důležité je naopak jasně vysvětlit, jak budou vypadat výsledky, jakou formou budou prezentovány (interaktivní dashboard, týdenní report, součást webových stránek apod.) a jaký budou mít dopad. A nezapomeňte komunikovat hodnotu vašeho projektu už od samého začátku.
Definování hledaného cíle analýzy
Definice hledaného cíle analýzy (tzv. label) je formulováním otázky, kterou chcete „položit“ vašim datům. Jakmile v tom budete mít jasno, ujistěte se, že váš cíl splňuje tři základní požadavky.
Za prvé, cíl musí odpovídat potřebám podniku. I pokud řešíte pilotní projekt, je lepší přemýšlet o ověření přínosu než o ověření konceptu (proof-of-concept). V této fázi je důležité získat důkaz, že projekt může pro firmu vytvořit hodnotu, tedy že váš cíl přímo souvisí s jejími potřebami (proof-of-value).
Za druhé, cíl musí existovat. Jsou situace, kdy není možné cíl reálně změřit. Představte si například, že ve vaší továrně je technologie, která se jen málokdy dostane do havarijního stavu. Když se tak stane, stojí vás to hodně peněz. Ale k havárii došlo asi jen třikrát za posledních deset let. Ač se jedná o cíl, který je očividný a závažný, s tak malým množstvím událostí je mimořádně obtížné natrénovat přesný model a pro predikci havárie tedy DSML není vhodné. Na druhou stranu můžete pro DSML najít jiné cílové funkce pro těžko měřitelné jevy. Můžete pro měření použít třeba lidský úsudek. Klasickým příkladem je analýza sentimentu nějakého textu, kdy se jako trénovací data používají lidská hodnocení, zda je komentář pozitivní, nebo negativní.
A za třetí, hledaný cíl musí být použitelný. I ten nejlepší algoritmus strojového učení nepomůže, pokud poznatky, které z něj získáte, nejsou použitelné v praxi. Musíte být schopni odpovědět na otázku: Jaké opatření bych ve firmě podnikl, kdybych to mohl předvídat?
Ale překvapivě, ne nutně potřebujete dokonale přesný cíl. Je potřeba si uvědomit, že žádné měření není bezchybné. I když čtete data z měřicího přístroje, třeba voltmetru, i ta mají svoji nepřesnost, se kterou nadále musíte počítat. I když budete mít cíl založený jen na lidském úsudku, jako například zmíněné hodnocení sentimentu textu, můžete postavit funkční model. Jen je třeba si uvědomit, že nepřesnost cíle musíte zohlednit při stanovení přesnosti vašeho modelu.
Jakmile je obchodní problém jasně definován, je úkolem datového experta přiřadit problém metodě datové vědy. V ideálním případě chtějte problém transformovat na problém supervised learning, tedy „učení s učitelem“. Například v problému kategorizace to znamená, že již znáte kategorie, do kterých chcete, aby váš algoritmus data roztřídil. Případy použití modelu „bez učitele“ je mnohem obtížnější optimalizovat, protože neposkytují kvalitativní měřítko, na jehož základě byste mohli model vyhodnotit a vyladit.
Alternativní možností je změnit řešený problém na problém s učením (supervized) a namísto kategorizace jej považovat za problém cílení (targeting problem): chcete předpovědět, zda si někdo koupí nějaký produkt, nebo ne. Tomuto postupu se říká segmentation by one.
Co je dostatečně kvalitní model a co je „úspěch“ projektu
Častou chybou v této fázi projektu je, že vezmete své datové experty, předáte jim nějaká data a pošlete je na několik týdnů pracovat. Přitom očekáváte, že výsledkem jejich snažení bude model, který bude možné vcelku snadno nasadit do produkce. Bohužel tento v praxi běžný postup je spíše receptem na katastrofu. Pouze když víte, čeho chcete dosáhnout, můžete si odpovědět, zda jste daný problém vyřešili, nebo ne. Musíte si položit otázku: Jak změřím kvalitu vyvinutého algoritmu?
Zaměřme se nyní ne na matematické metriky, ale na vztah k podnikání. Ukažme si to na příkladech. Řešíme regresní úlohu a chceme předpovědět počet kusů objednaného zboží našimi zákazníky, abychom mohli s předstihem zabalit objednané položky. Přecenění poptávky znamená připravit příliš mnoho balení, která zůstanou ležet na skladu. Podcenění objednávek ale znamená zpoždění v dodávkách. Obchodní dopady, a tedy i náklady spojené s oběma předpověďmi se liší. To je rozdíl od typických statistických ukazatelů výkonnosti, jakými jsou RMSE nebo R², které předpokládají, že úlohy jsou symetrické.
Pro úlohy klasifikace jsou dokonalým příkladem domácí zdravotní testy. „Self-test“, který falešně předpoví, že máte danou nemoc (falešně pozitivní výsledek), vyvolá potřebu rozsáhlejších a dražších následných testů. Tyto testy pak správně určí, že danou nemoc nemáte. Druhým typem chyby je situace, kdy výsledky testu ukazují, že danou nemoc nemáte, přestože ji ve skutečnosti máte (falešně negativní výsledek). V tomto případě nesprávný výsledek zabrání správné a včasné léčbě, což může způsobit vážné poškození zdraví, nebo dokonce smrt pacienta. Opět, běžné míry klasifikační přesnosti, jakými jsou skóre F1 a AUC, předpokládají, že falešně pozitivní a falešně negativní výsledky jsou stejně závažné.
Řešením je tedy stanovení výkonnostní metriky založené na hodnotě, které bude co nejvíce odpovídat obchodnímu problému identifikovanému v první fázi projektu. Tady může pomoci i samotný softwarový nástroj. Např. řešení RapidMiner je průkopníkem přístupu k vytváření modelů založených na ekonomických hodnotách tím, že poskytuje způsoby, jak zohlednit náklady a přínosy. To pomáhá určit nejlepší model pro daný případ použití, a to nejen na základě statistické a matematické přesnosti modelu, ale také na základě dopadu, který budou mít předpovědi modelu na vaše hospodářské výsledky.
A kdy je náš projekt úspěšný? Často se doporučuje, že tehdy, jakmile model generuje „slušné hodnoty“. V praxi vznikla spousta modelů, které mohly ušetřit statisíce dolarů ročně a které nebyly nasazeny, protože tým datových expertů byl přesvědčený, že ještě nejsou dokonalé. Jak ale definovat tuto slušnou hodnotu? Proto si potřebujete definovat kritéria úspěchu na začátku projektu. Pokud víte, jaká je vaše prahová hodnota, a dosáhnete jí, můžete vývoj přerušit a model nasadit. Nebo můžete nasadit první verzi a paralelně budete pokračovat v dalším zdokonalování tohoto modelu.
Jako výchozí hodnotu (baseline) můžete použít jakékoli aktuálně nasazené řešení anebo tzv. „naivní řešení“. Výchozí hodnotou může být například regrese vypočítaná v MS Excel a bude to skvělé. Máte totiž s čím porovnávat. Pokud žádné stávající řešení nemáte, můžete se porovnat s většinovou třídou v klasifikačním problému, s průměrem v regresním problému nebo historickou poptávkou ve scénáři předpovědi poptávek.
Data
Popularita umělé inteligence způsobila problémy vyplývající z toho, jak se na práci datových expertů dívají ostatní. Ti obvykle mají představu, že projekt vypadá asi takto: Vhodíme data do modelu pro Deep Learning a problém se sám vyřeší. Bohužel to tak nefunguje. Než datoví experti začnou modelovat, potřebují kvalitně připravená data pro daný úkol. Jedná se o vytvoření tzv. profilu, kdy vytváříte jednořádkovou reprezentaci pro každého zákazníka (nebo každý stroj, aktivum apod.). Tento profil by měl být „úplný“ a „hutný“. Úplný (complete) znamená, že data obsahují všechny možné informace, které mohou algoritmu pomoci při předpovědích. Hutný (dense) znamená, že jste dosáhli úplnosti s nízkým počtem jednotlivých atributů. Obtížnost dosažení správné rovnováhy mezi úplností a hutností činí z kroku přípravy dat jednu z nejtěžších činností v Data Science.
Dále budete řešit přístupy (přístupová práva), dostupnost (zda můžete data zpracovat v reálném čase nebo v dávkovém režimu, a s jakou frekvencí aktualizace), a samozřejmě datové typy a formáty. Nás budou nejčastěji zajímat surová zdrojová (raw) data, často v podobě záznamů s povahou časových řad (time series). Často se setkáme s tím, že tato data máme k dispozici v datových skladech, ale již agregovaná. To je dobré pro prototypování, ale na druhou stranu agregace vždy znamenají určitou ztrátu informací oproti zdrojovým (surovým) datům. Chcete-li tedy ve svém projektu získat co nejlepší výsledky, je důležité získat přístup k podkladovým datům a použít je pro trénování a vyhodnocování modelů.
Jakmile máme přístup k datům, následuje čištění dat. Jak asi tušíte, data vždy obsahují chyby. Jsou neúplná, nekonzistentní, obsahují lidské chyby nebo duplicity. Často existují technicky zřejmé způsoby, jak data vyčistit. Ale existuje spousta „šumu“ a chyb, pro jejichž identifikaci a čištění potřebujeme informace a nápady business specialistů, kteří jejich významu rozumí. Proces čištění a přípravy dat patří mezi nejpracnější fáze projektu, proto je třeba včas si udělat představu, kolik budeme na tento proces potřebovat času.
Jak vám pomůže vhodná softwarová platforma
Dále budeme uvažovat, že firma si jako strategickou cestu k pokročilým analýzám zvolí variantu, kdy bude stavět know-how na vlastních lidech, tedy bude rozšiřovat kompetence vlastníků business procesů z pohledu práce s daty. Nebude se ani bránit konzultační výpomoci zvenčí, ale vždy bude chtít zůstat plným vlastníkem datových modelů, udržovat je funkční a provozovat je na interní SW/HW infrastruktuře.
Pokračování příště
Ing. Tomáš Čurda, Ph.D.
Autor článku je Business Development Manager společnosti Advanced Engineering, s. r. o.
Autor článku je Business Development Manager společnosti Advanced Engineering, s. r. o.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.










