


- P�ehledy IS
- APS (20)
- BPM - procesn� ��zen� (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - spr�va dokument� (20)
- EAM (17)
- Ekonomick� syst�my (68)
- ERP (79)
- HRM (27)
- ITSM (6)
- MES (32)
- ��zen� v�roby (36)
- WMS (29)
- Dodavatel� IT slu�eb a �e�en�
- Datov� centra (25)
- Dodavatel� CAD/CAM/PLM/BIM... (39)
- Dodavatel� CRM (33)
- Dodavatel� DW-BI (50)
- Dodavatel� ERP (71)
- Informa�n� bezpe�nost (50)
- IT �e�en� pro logistiku (45)
- IT �e�en� pro stavebnictv� (26)
- �e�en� pro ve�ejn� a st�tn� sektor (27)
Hlavn� partner sekce

Tematick� sekce
 ERP syst�my CRM syst�my Pl�nov�n� a ��zen� v�roby AI a Business Intelligence DMS/ECM - Spr�va dokument� HRM/HCM - ��zen� lidsk�ch zdroj� EAM/CMMS - Spr�va majetku a �dr�by ��etn� a ekonomick� syst�my ITSM (ITIL) - ��zen� IT Cloud a virtualizace IT IT Security Logistika, ��zen� sklad�, WMS IT pr�vo GIS - geografick� informa�n� syst�my Projektov� ��zen� Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP syst�my CRM syst�my Pl�nov�n� a ��zen� v�roby AI a Business Intelligence DMS/ECM - Spr�va dokument� HRM/HCM - ��zen� lidsk�ch zdroj� EAM/CMMS - Spr�va majetku a �dr�by ��etn� a ekonomick� syst�my ITSM (ITIL) - ��zen� IT Cloud a virtualizace IT IT Security Logistika, ��zen� sklad�, WMS IT pr�vo GIS - geografick� informa�n� syst�my Projektov� ��zen� Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBran�ov� sekce
| P�ihlaste se k odb�ru newsletteru SystemNEWS, kter� ka�d� t�den p�in�� v�b�r �l�nk� z oblasti podnikov� informatiky | |
 | |

Partne�i webu

IT SYSTEMS 7-8/2024 , CRM syst�my , AI a Business Intelligence


Segmentace z�kazn�k� a churn anal�za
Milan Machalec
 O standardn�ch �loh�ch a projektech v oblasti data science (DS), mezi n� pat�� i segmentace z�kazn�k� a churn anal�za, bylo ji� naps�no mnoho. V�t�inou se v�ak jedn� o obecn� obchodn� formulace a m�lokdo u� v�, co v�echno se ve skute�nosti skr�v� za samotnou realizac� takov�ho komplexn�ho DS projektu, jak� je jeho �asov� n�ro�nost a co v�echno mus� datov� v�dec, nebo postaru datov� analytik, �e�it a s ��m se mus� popasovat. DS projekty mohou m�t mnoho spole�n�ho, av�ak ka�d� realizace je specifick� a vy�aduje individu�ln� p��stup, aby byly spln�ny po�adavky zadavatele. Pro p�edstavu si postup realizace DS projektu p�edstav�me na p��kladu telekomunika�n� spole�nosti (TS). Postupovat budeme v jednotliv�ch f�z�ch podle metodologie CRISP-DM.
O standardn�ch �loh�ch a projektech v oblasti data science (DS), mezi n� pat�� i segmentace z�kazn�k� a churn anal�za, bylo ji� naps�no mnoho. V�t�inou se v�ak jedn� o obecn� obchodn� formulace a m�lokdo u� v�, co v�echno se ve skute�nosti skr�v� za samotnou realizac� takov�ho komplexn�ho DS projektu, jak� je jeho �asov� n�ro�nost a co v�echno mus� datov� v�dec, nebo postaru datov� analytik, �e�it a s ��m se mus� popasovat. DS projekty mohou m�t mnoho spole�n�ho, av�ak ka�d� realizace je specifick� a vy�aduje individu�ln� p��stup, aby byly spln�ny po�adavky zadavatele. Pro p�edstavu si postup realizace DS projektu p�edstav�me na p��kladu telekomunika�n� spole�nosti (TS). Postupovat budeme v jednotliv�ch f�z�ch podle metodologie CRISP-DM.
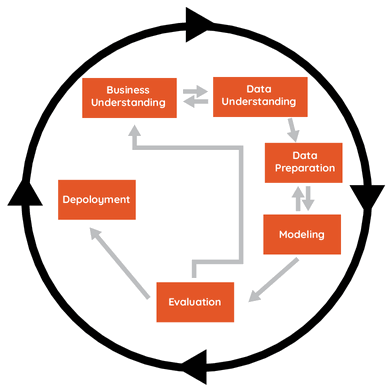
Obr. 1: Sch�ma metodologie CRISP-DM
1. f�ze: Business Understanding
Z osobn�ho setk�n� se z�stupci TS vyplynulo, �e maj� z�jem realizovat personalizovan� marketingov� kampan� zam��en� na skupiny klient� podle jejich vyu�it�ho objemu dat, provolan�ch minut a po�tu odeslan�ch textov�ch zpr�v za posledn� t�i m�s�ce. Pro �e�en� �lohy tedy bude vytvo�en segmenta�n� model, jeho� �kolem bude rozd�lit klienty do n�kolika skupin podle zvolen�ch charakteristik tak, aby si klienti v jedn� skupin� byli podobn� a naopak z rozd�ln�ch skupin byli odli�n� vzhledem ke zvolen�m charakteristik�m. Na ka�dou skupinu pak budou moci b�t vytv��eny specializovan� c�len� marketingov� kampan� (kompetence TS). Po�aduje se tak� naj�t optim�ln� mal� po�et skupin a popsat jejich charakteristiku. Za�azov�n� klient� do skupin bude prob�hat m�s��n� a z�rove� se budou sledovat p�echody klient� mezi skupinami oproti p�edchoz�mu m�s�ci. Na m�s��n� b�zi se bude tak� sledovat zastoupen� jednotliv�ch skupin a kvalita segmenta�n�ho modelu v �ase. V�sledky budou ka�d� m�s�c zobrazov�ny a aktualizov�ny v p�ehledn�m reportu. Notifikace o aktualizaci reportu bude zas�l�na na vybran� e-mailov� adresy.
D�le TS chce realizovat reten�n� kampan� zam��en� na sn�en� odchodu klient� ke konkurenci, konkr�tn� u klient�, u kter�ch je m�s�c do konce smlouvy a je vysok� pravd�podobnost, �e b�hem t�� m�s�c� po jej�m skon�en� podaj� ��dost o p�enos ��sla k jin�mu oper�torovi. Pro tento ��el bude vytvo�en churn model na z�klad� historick�ch dat o chov�n� klient�. Z n�ho budeme moci identifikovat a popsat charakteristiky, kter� zvy�uj� nebo sni�uj� pravd�podobnost p�enosu ��sla, a tedy kte�� klienti a jejich ��sla jsou nejv�ce rizikov�. Na rizikov� klienty budou pravideln� vytv��eny reten�n� kampan� a model bude implementov�n do intern�ho syst�mu (kompetence TS), aby prodejce mohl p�i komunikaci s klientem vid�t jeho rizikovost ve form� barevn�ho semaforu. Na m�s��n� b�zi bude prob�hat sk�rov�n� vytvo�en�m churn modelem, sledov�n� jeho kvality a m�ry odchodu klient� (churn rate). V�sledky budou ka�d� m�s�c zobrazov�ny a aktualizov�ny v p�ehledn�m reportu, v�etn� notifikace o jeho aktualizaci, kter� bude zas�l�na na vybran� e-mailov� adresy.
P�i realizaci projektu se spolupracuje s experty TS. V �vodn�ch dvou f�z�ch pracovn�ci poskytuj� podrobn� informace o procesech a datech, kter�mi disponuj�, v�etn� zp�sobu jejich ukl�d�n� a popisu. �asov� n�ro�nost t�to f�ze je odhadov�na na 5 MD (�lov�kodn�).
2. f�ze: Data Understanding
TS disponuje mno�stv�m datov�ch zdroj�, kter� lze vyu��t p�i budov�n� churn modelu a p�i v�po�tu pot�ebn�ch charakteristik pro segmenta�n� model. Jedn� se o datov� zdroje s identifika�n�mi a sociodemografick�mi �daji o klientech, informace o kontaktech s TS, vyu��v�n� hlasov�ch, datov�ch, textov�ch a dal��ch slu�eb, pohybu na webu a vyu��v�n� port�lu nebo aplikace, podrobn� popis cel� historie klient� v�etn� jejich produkt�, faktur, upom�nek atd.
Sezn�mili jsme se s daty, jejich strukturou a v�znamem jednotliv�ch atribut�. Zjistili jsme rozsah dat, zp�sob jejich ukl�d�n�, typ prom�nn�ch a jejich k�dov�n�, ��seln�ky. Provedl se datov� audit. �asov� n�ro�nost 20 MD.
3. f�ze: Data Preparation
�asov� nejn�ro�n�j�� f�ze pokr�vaj�c� v�echny �innosti pot�ebn� k vytvo�en� fin�ln� datov� matice, kter� vstupuje do modelov�n�. Vzhledem k potenci�lu dal��ch �loh do budoucna, pravideln�mu m�s��n�mu sk�rov�n�, vyu��v�n� dat v reportech a integraci se vytvo�il DS datov� sklad, kter� je pravideln� aktualizov�n na m�s��n� b�zi. P�i tvorb� a aktualizaci datov�ho skladu se z datov�ch zdroj� vyu��vaj� operace pro v�b�r, �i�t�n�, vytv��en� (nap�. v�po�tem, agregac� nebo restrukturalizac�), slu�ov�n� (vedle sebe nebo pod sebe) a form�tov�n� dat. Pro segmenta�n� model slou�� datov� matice o t�ech atributech, proto�e v�ak nejsou m��eny ve stejn�ch jednotk�ch, a tedy na stejn� �k�le, budou p�ed vstupem do modelu standardizov�ny.
Pro churn model vyu��v�me datovou matici, kter� obsahuje atributy odpov�daj�c� stavu m�s�c p�ed ukon�en�m smlouvy klienta. Atributy pro vstup do modelu zahrnuj� p��znaky produkt� klienta, dobu vztahu klienta, provolan� minuty do jednotliv�ch s�t�, objem vyu�it�ch dat, sumu zaplacenou nad r�mec pau��lu, v�k, pohlav�, kraj, rodinn� stav, jazyk klienta, p��znaky vol�n� z nebo na infolinku konkurence, po�et p�eru�en�ch hovor�, po�et st�nost� atd. Odvozena byla tak� c�lov� prom�nn�, zda b�hem t�� m�s�c� po skon�en� smlouvy dojde k pod�n� ��dosti o p�enos ��sla k jin�mu oper�torovi. V p��pad� pot�eby se realizovala i kategorizace a transformace dat. P�ed modelov�n�m se datov� matice rozd�lila na tr�ninkovou mno�inu, na kter� se model vytv���, a testovac� mno�inu, kter� slou�� k vyhodnocen� jeho kvality. �asov� n�ro�nost 75 MD.
4. f�ze: Modeling
Porovn�vali jsme r�zn� modelovac� algoritmy s r�zn�m nastaven�m parametr�, ale vzhledem k porovnateln� kvalit� a po�adavku interpretovatelnosti byla pro churn model zvolena logistick� regrese a algoritmus TwoStep pro segmenta�n� model.
Optim�ln�m algoritmem byly stanoveny �ty�i klastry. Obr�zek n�e uv�d� pr�m�rn� hodnoty atribut� pro jednotliv� klastry, kter� jsou barevn� odli�eny pro snadn�j�� interpretaci. V prvn�m klastru jsou klienti, kte�� maj� v pr�m�ru n�zk� v�echny hodnoty atribut� oproti jin�m klastr�m. Druh� klastr je charakteristick� nejvy���m pr�m�rn�m vyu�it�m objemu dat, t�et� klastr nejvy���mi pr�m�rn�mi provolan�mi minutami a �tvrt� klastr nejvy���m pr�m�rn�m po�tem odeslan�ch textov�ch zpr�v.
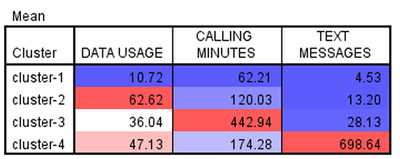
Obr. 2: Pr�m�rn� hodnoty v jednotliv�ch klastrech
Dal�� obr�zek p�edstavuje odhad regresn�ch koeficient� churn modelu. Z nich je vid�t, �e nejrizikov�j�� klienti a ��sla pro pod�n� ��dosti o p�enos ��sla k jin�mu oper�torovi jsou ti s kr�tkou dobou ��sla u TS, kr�tkou dobou klienta u TS, klienti s pron�jmem jak�hokoliv za��zen�, klienti bez ��sla s mo�nost� dob�jen� kreditu, klienti s vysok�m po�tem provolan�ch minut, s existenc� hlasov� schr�nky, klienti s internetem od TS a s velk�m objemem vyu�it�ch dat. �asov� n�ro�nost 5 MD.

Obr. 3: Odhad regresn�ch koeficient� churn modelu
5. f�ze: Evaluation
Kvalita segmenta�n�ho modelu podle pr�m�rn� siluety je vy��� ne� 0,5. To zna�� uspokojiv� model. Sv�d�� o tom i rozd�ly mezi klastry podle jejich charakteristik. Churn model je podle Giniho evalua�n� metriky na tr�ninkov� i testovac� mno�in� porovnateln�, nedoch�z� k jeho p�eu�en� a je nad hodnotou 0,5, co� p�edstavuje dobr� model. Postup cel�ho �e�en� byl p�ed jeho nasazen�m zkontrolov�n. F�ze evaluace trvala 2 MD.
6. f�ze: Deployment
�e�en� je integrov�no do rozhodovac�ch proces� TS. Pro oba modely je nastaveno automatick� sk�rov�n� na m�s��n� b�zi spolu s aktualizac� DS datov�ho skladu.
Hlavn� v�stup segmenta�n�ho modelu je datab�zov� tabulka, kter� obsahuje identifik�tor m�s��n�ho sn�mku, identifik�tor klienta, hodnoty vstupn�ch atribut� modelu, za�azen� do klastru v aktu�ln�m a p�edchoz�m sn�mku. Slou�� jako podklad pro c�len� marketingov� kampan�.
Pro churn model je prim�rn�m v�stupem datab�zov� tabulka s iden�ti�fi�k�to�rem m�s��n�ho sn�mku, identifik�torem klienta, telefonn�m ��slem a pravd�podobnost� pod�n� ��dosti o p�enos ��sla k jin�mu ope�r�to�ro�vi b�hem t�� m�s�c� po skon�en� smlouvy. Tento v�stup slou�� jako podklad pro reten�n� marketingov� kampan� a pro integraci rizikovosti klienta do intern�ho syst�mu formou barevn�ho semaforu.
Na z�v�r byla vytvo�ena projektov� dokumentace a prezentov�ny dosa�en� v�sledky. Celkov� n�ro�nost projektu je 120 MD. N�kdy je schopen projekt realizovat jeden �lov�k, ale typicky je to t�mov� spolupr�ce kvalifikace a kompetence jednotliv�ch �len� t�mu.
 |
Mgr. Ing. Milan Machalec Autor �l�nku je senior data scientist ve spole�nosti ACREA SR. |
Chcete z�skat �asopis IT Systems s t�mto a mnoha dal��mi �l�nky z oblasti informa�n�ch syst�m� a ��zen� podnikov� informatiky? Objednejte si p�edplatn� nebo konkr�tn� vyd�n� �asopisu IT Systems z na�eho archivu.











