

- Přehledy IS
- APS (20)
- BPM - procesní řízení (22)
- Cloud computing (IaaS) (10)
- Cloud computing (SaaS) (33)
- CRM (51)
- DMS/ECM - správa dokumentů (20)
- EAM (17)
- Ekonomické systémy (68)
- ERP (77)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (37)
- WMS (31)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (39)
- Dodavatelé CRM (33)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (71)
- Informační bezpečnost (50)
- IT řešení pro logistiku (45)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (27)
Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce
| Přihlaste se k odběru newsletteru SystemNEWS, který každý týden přináší výběr článků z oblasti podnikové informatiky | |
 | |


Partneři webu

Aktuality -> Podnikové aplikace a služby - 12. 7. 2024 - redakce
ACREA vylepšuje své řešení pro textovou analýzu o novou proceduru
 Analytický software IBM SPSS Statistics nativně nenabízí procedury určené pro textovou analýzu. Proto společnost ACREA připravila pro své uživatele specializovaný modul Acrea Text Analytics, který tuto funkcionalitu nabízí formou samostatných procedur určených pro konkrétní specifickou činnost. Celkově se jedná o tři procedury. ATA Sentiment, ATA Labels a ATA Entities. Aktuální novinkou je nová procedura ATA Entities a přepracovaná procedura ATA Labels, ve které byla zrušena volba domény dokumentů a typu hesla.
Analytický software IBM SPSS Statistics nativně nenabízí procedury určené pro textovou analýzu. Proto společnost ACREA připravila pro své uživatele specializovaný modul Acrea Text Analytics, který tuto funkcionalitu nabízí formou samostatných procedur určených pro konkrétní specifickou činnost. Celkově se jedná o tři procedury. ATA Sentiment, ATA Labels a ATA Entities. Aktuální novinkou je nová procedura ATA Entities a přepracovaná procedura ATA Labels, ve které byla zrušena volba domény dokumentů a typu hesla.


Procedura ATA Entities se využívá k extrakci pojmenovaných entit z textového dokumentu. Například při extrakci entit z příspěvků ze sociálních sítí jako je Facebook, Instagram, X (Twitter), různých diskusních fór, článků, otevřených otázek v dotaznících a podobně. Pojmenovanou entitou může být osoba, organizace nebo místo. Typy entit se zaznamenávají do datové matice jako nový atribut s hodnotami person, organization, location. Před samotnou extrakcí entit lze realizovat automatické rozpoznání jazyka a doplnění diakritiky, pokud chybí. Primárně je procedura určená k analýze českého a slovenského textu, umožňuje však analyzovat i texty z jiných jazyků, například angličtiny či němčiny.
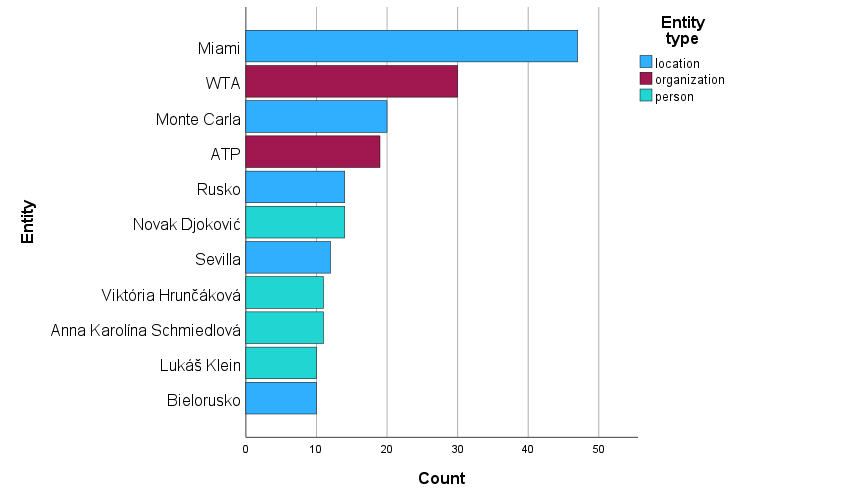
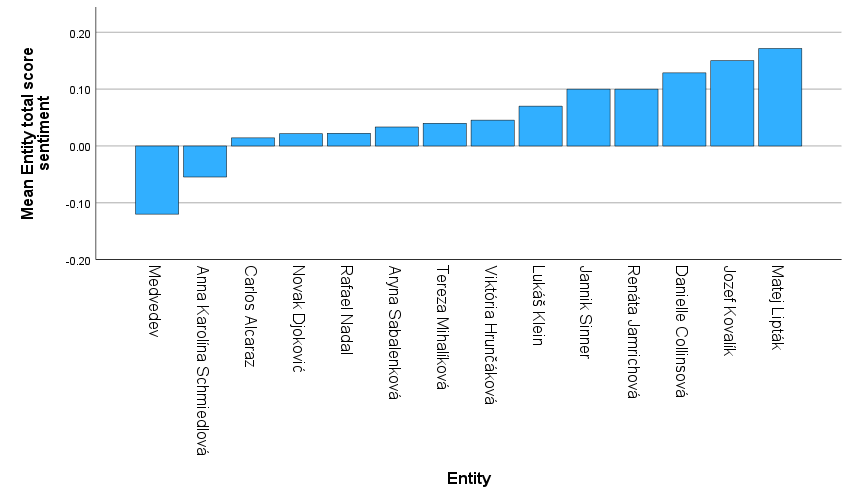
Ke každé entitě je možné připojit sentiment spojený s entitou a případně jej kvantifikovat pomocí skóre. Kategorie sentimentu jsou very negative, negative, neutral, positive, very positive a ambivalent. Celkové skóre nabývá hodnot od -1 do +1. Kladné hodnoty indikují pozitivní sentiment, záporné negativní. Celkové skóre je součtem pozitivního a negativního skóre.
Procedura ATA Entities restrukturalizuje zpracovávanou datovou matici na dlouhý transakční formát, kde řádky reprezentují nalezené pojmenované entity a jsou identifikovány identifikátorem původního dokumentu.




| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 1 | 2 | 3 | 4 | 5 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
IT Systems podporuje
| 6.10. | Unicorn Banking Forum 2016 |
Formulář pro přidání akce
Další vybrané akce
| 26.6. | Certifikace ISO prakticky |
| 30.9. | Konference Světlo |