




- Přehledy IS
- APS (21)
- BPM - procesní řízení (23)
- Cloud computing (IaaS) (9)
- Cloud computing (SaaS) (29)
- CRM (49)
- DMS/ECM - správa dokumentů (19)
- EAM (16)
- Ekonomické systémy (68)
- ERP (87)
- HRM (27)
- ITSM (6)
- MES (32)
- Řízení výroby (47)
- WMS (28)
- Dodavatelé IT služeb a řešení
- Datová centra (25)
- Dodavatelé CAD/CAM/PLM/BIM... (40)
- Dodavatelé CRM (36)
- Dodavatelé DW-BI (50)
- Dodavatelé ERP (80)
- Informační bezpečnost (42)
- IT řešení pro logistiku (46)
- IT řešení pro stavebnictví (25)
- Řešení pro veřejný a státní sektor (26)
Partneři sekce

Tematické sekce
 ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tisk
ERP systémy CRM systémy Plánování a řízení výroby AI a Business Intelligence DMS/ECM - Správa dokumentů HRM/HCM - Řízení lidských zdrojů EAM/CMMS - Správa majetku a údržby Účetní a ekonomické systémy ITSM (ITIL) - Řízení IT Cloud a virtualizace IT IT Security Logistika, řízení skladů, WMS IT právo GIS - geografické informační systémy Projektové řízení Trendy ICT E-commerce B2B/B2C CAD/CAM/CAE/PLM/3D tiskBranžové sekce




Partneři webu

Business Intelligence , AI a Business Intelligence


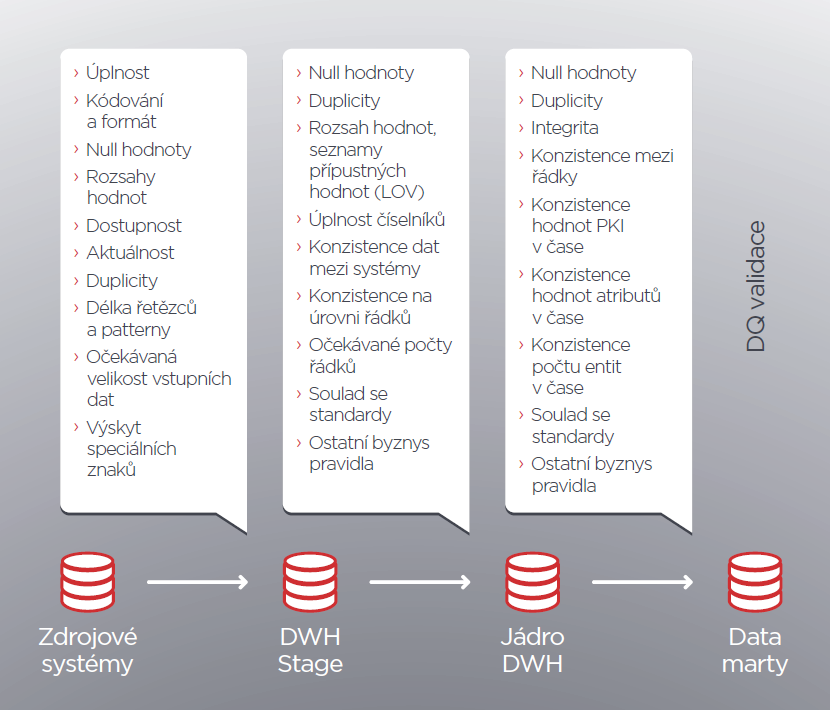
Datová kvalita pro datové sklady
 Uživatelé datových skladů a Business intelligence (BI) řešení se shodují na tom, že nízká kvalita dat je neobyčejně frustrující a drahá. Jsou si vědomi, že řízení datové kvality je pro datové sklady druhá nejdůležitější kompetence, hned po řízení metadat. Méně jednotný názor však mají na to, co to vlastně datová kvalita je a co musí splňovat BI řešení, aby se sledováním a zlepšováním datové kvality mohli zabývat.
Uživatelé datových skladů a Business intelligence (BI) řešení se shodují na tom, že nízká kvalita dat je neobyčejně frustrující a drahá. Jsou si vědomi, že řízení datové kvality je pro datové sklady druhá nejdůležitější kompetence, hned po řízení metadat. Méně jednotný názor však mají na to, co to vlastně datová kvalita je a co musí splňovat BI řešení, aby se sledováním a zlepšováním datové kvality mohli zabývat.
Často používaná definice říká, že data jsou kvalitní, pokud uživatelé mají data kompletní, srozumitelná, konzistentní, relevantní a včas. Ještě jednodušeji řečeno, data jsou kvalitní, pokud splňují požadavky uživatelů na jejich použití. V prostředí datového skladu se ale vyskytují dvě velké skupiny uživatelů, které mají různé zájmy. Vlastníci datového skladu jsou ochotni považovat data za kvalitní, pokud nenaruší zpracování v datovém skladu od vstupu dat až po výpočty cílových datamartů a reportů. Na druhé straně stojí byznys uživatelé, které zajímá zda jsou výsledky důvěryhodné a k dispozici včas. Popřípadě ještě chtějí vědět, na základě jakých dat byla spočtena reportovaná čísla, zda při zpracování došlo k nějakým chybám, jak byly opraveny a zda měly nějaký dopad na výsledek.
Připravme se na nepředvídané
Z mnoha pohledů je první skupina ve velké výhodě. Zná technologie, rozumí řešení datového skladu a implementuje změny. Síla byznys uživatelů spočívá v tom, že mohou definovat a vyžadovat byznys pravidla, která musí datový sklad splňovat, a zejména v tom, že ve většině případů řešení financují.
Připravit datový sklad pro řízení datové kvality znamená připravit se na nepředvídané. Řešení musí být podobné jako systémy pro krizové řízení v případě přírodních katastrof. Musí být jednoduché a rychlé, aby fungovalo v krizových situacích. Musí být použitelné jak při záplavách, tak při požárech ze sucha, a dokonce i při zemětřesení, i když všichni tvrdí, že zemětřesení nastat nemůže. Řešení musí zahrnovat technické prostředky i procesy. Postupy musí být dobře popsány a všichni zainteresovaní musí znát své povinnosti. Zároveň se všechny činnosti musí pravidelně trénovat.
Základní strategie, jak s vadami bojovat, je jejich odhalování a testování datové kvality na všech úrovních datového skladu během každého zpracování. Na obrázku jsou uvedena místa testování a doporučené typy testů. Co to znamená z pohledu datového skladu? Řešení datové kvality musí být zohledněna v návrhu datového modelu, při analýze a vývoji transformací i při procesech provozování datového skladu.
Zvyšování datové kvality
Procesy spojené s řízením datové kvality a opravou chyb jsou kapitolou samy o sobě. Asi nikdo už dnes nepochybuje o tom, že každá nalezená chyba v datové kvalitě musí být zaznamenána, že o tom, jak bude opravena, musí rozhodnout byznys vlastník dat, nikoliv technik, a že musí být zaznamenáno, kdy, co a jak bylo opraveno. U každé chyby bychom měli být schopni alespoň přibližně odhadnout její finanční dopad. Ne každá nekonzistence či nekvalita je pro uživatele dat důležitá a její oprava je ekonomicky výhodná.
Často je nastaven proces, kdy se chybná data opravují v primárních systémech a do datového skladu se dostanou při příštím zpracování. To je preferovaný přístup, protože zvyšuje datovou kvalitu nejen v datovém skladu, ale napříč firmou. S tímto procesem bývají všichni spokojeni až do okamžiku, kdy primární systém ohlásí, že data změnit nemůže, protože to prostě nejde. Proto při návrhu řešení je nutné počítat s opravami jako standardní součástí zpracování. Použití opravných položek a opakované zpracování opravených dat z chybových tabulek je jedním z možných přístupů.
Definice transformačních pravidel
Transformační procedury, ať už jsou uskutečňovány jakkoliv, mění data v datovém skladu, a proto většina vad v datové kvalitě je spojena právě s nimi. Přístup k jejich návrhu a vývoji je tak zásadní. Můžeme je rozdělit do tří skupin – transformace, byznys pravidla a datové integrace. Tyto transformace jsou zpravidla navrhovány analytiky a vytvářeny ručně. Z pohledu datové kvality je kritická dostatečně rozsáhlá kontextová, strukturální a sémantická analýza vstupních dat a také adekvátní profilování vstupních dat. To je jediný způsob, jak předcházet vzájemné nekonzistenci, výskytu duplicit nebo ztrátě dat způsobené chybami v definici transformačních pravidel.
Druhým typem transformací jsou technologické transformace. Mezi ně patří nahrání dat z primárních systémů, historizace nebo archivace. Tyto procedury mohou být kompletně generovány na základě datového modelu a vzorů připravených architekty. Vynechání lidských zásahů do kódu významně snižuje počet chyb a tím i možnost vzniku chyb v datech. Ostatně jakýkoliv ručně vytvářený kód, nebo dokonce data jsou velikým rizikem z pohledu datové kvality a nejčastější příčinou chyb. Generováním lze navíc získat jako bonus snížení nákladů na vývoj a údržbu.
Třetím typem transformací jsou procesy validace datové kvality. Doporučovaným patternem je rozdělení každé logické transformace na byznys transformaci, následné ověření datové kvality výsledných dat a jejich následné zpracování – nejčastěji historizace. Aby tento pattern mohl efektivně fungovat, je nutné, aby validační pravidla byla definována metadaty a relativně snadno měnitelná bez nutnosti zásahu do kódu řešení. V takovém případě je možné při nalezení chyby definovat nové pravidlo, které identifikuje vadná data při dalším zpracování. Zároveň je možné měnit místo, kde validace vadná data identifikují. Obecně platí, že čím blíže zdrojovým datům je chyba identifikovaná, tím menší dopad má. Metadaty řízené validace navíc umožňují operativně řídit rozsah prováděných validací a tím výpočetní nároky zpracování.
Kvalitní model jako základ
Dobrý datový model je vždy kompromisem, který vychází z existujících dostupných logických datových modelů pro jednotlivé vertikály, modely primárních aplikací a požadavky na srozumitelnost modelu. Obecné logické modely se vyznačují velkou komplexitou – prostě proto, že jsou obecné. Na druhé straně je v nich koncentrovaná nenahraditelná zkušenost z desítek existujících řešení. Slepá aplikace těchto modelů vede ke zbytečně složitým transformacím, které jsou náchylné produkovat chyby nejen v datové kvalitě. Na druhé straně často většina dat pochází z jednoho nebo dvou primárních systémů a uživatelé by nejraději chtěli zachovat jejich datový model i v datovém skladu, protože ho znají a rozumějí mu. Přílišné lpění na modelu dat z jednoho primárního systému ale vede k problémům při integraci s ostatními daty a k následným nekonzistencím.
Pro udržení datové kvality je nutné mít velmi přesný popis sémantiky modelu, všech jeho tabulek a sloupců. Nestačí pouze existence popisu, stejně nutné je dosáhnout jednotného chápání modelu mezi všemi uživateli. Právě rozdílné názory na význam jednotlivých entit jsou častým důvodem nekonzistencí a chyb v transformačních pravidlech.
Z pohledu datové kvality je velmi důležité, aby technické aspekty datového modelu, které podporují řízení a ověřování datové kvality, byly jednotně řešeny v celém modelu. Zpravidla jde o sloupce označující chybové nebo nevalidní řádky, „error tabulky“ – tabulky obsahující řádky, které neprošly testy datové kvality, auditní sloupce se záznamy o původu dat a identifikací procesů, které řádky do datového skladu přidaly nebo je měnily. Sem patří jednoznačně definované způsoby použité historizace, jednotná pravidla pro práci s null hodnotami, s velikostí použitých datových typů a pravidla pro práci s umělými klíči.
Jediný způsob, jak zvládnout komplexitu problematiky návrhu datového modelu, je zapojení datového architekta s dostatečnou zkušeností už v počátečních etapách přípravy řešení. Musí být schopen rozhodnout o vhodnosti použitých patternů, strategií a procesů z pohledu velikosti datového skladu, účelu řešení i vyspělosti zákazníka. Musí být schopen ohodnotit dopad všech rozhodnutí jak v době vývoje, tak v době provozování a rozvoje řešení. Zároveň musí být schopen dohodnout se na výsledném řešení s budoucími byznys uživateli. Na něm leží největší váha při dohledu nad výsledky práce jednotlivých analytiků a musí průběžně revidovat všechny změny datového modelu.
 |
Ondřej Zýka Autor článku pracuje ve společnosti Profinit na pozici Senior Data Consultant. Má dvacetiletou zkušenost s datově intenzivními projekty – jako je budování datových skladů a speciálních operativních datastorů, datové migrace, projekty řízení datové kvality a řízení metadat. V současnosti také vyučuje na ČVUT FIT a UAI Jihočeské univerzity. |
Téma bude zpracováno podrobněji na webových stránkách společnosti Profinit.
Chcete získat časopis IT Systems s tímto a mnoha dalšími články z oblasti informačních systémů a řízení podnikové informatiky? Objednejte si předplatné nebo konkrétní vydání časopisu IT Systems z našeho archivu.










| Po | Út | St | Čt | Pá | So | Ne |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 1 | 2 | 3 | 4 | 5 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
IT Systems podporuje
Formulář pro přidání akce
Další vybrané akce